
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Практическая работа №1. Решение задач эконометрики с применением парной линейной регрессии
Батасова В.С. Практикум по основам эконометрики в среде Excel: учебное пособие по курсу «Эконометрика». – М.: Издательский дом МЭИ, 2009.– 68 с. ISBN Практикум предназначен для приобретения студентами навыков решения задач эконометрики с целью дальнейшего применения в специальных дисциплинах и практической деятельности. Включает работы по следующим темам: линейная парная регрессия, линейная множественная регрессия, временные ряды, фиктивные переменные, одновременные уравнения. Предназначен для студентов всех направлений подготовки факультета «Экономика и управление» ГПИ МЭИ (ТУ) при изучении курса эконометрики. Может использоваться всеми студентами экономических специальностей.
ISBN © Московский энергетический институт, 2009 Введение В настоящее время стремительно развиваются науки, связанные с применением математических методов и информационных технологий в различных областях человеческой деятельности. Эконометрика – одна из таких наук. Эконометрика занимается разработкой и применением статистических методов для определения взаимосвязей между экономическими переменными. Основная цель таких исследований состоит в том, чтобы получить возможность по значениям одних переменных прогнозировать значения других. Эконометрика – одна из дисциплин, составляющих базовую подготовку экономистов. Она входит в Государственные образовательные стандарты для экономических специальностей как обязательная дисциплина. Предлагаемый практикум состоит из шести работ, материал которых приблизительно соответствует программе по эконометрике для вузов. Цель практикума – приобретение студентами навыков решения эконометрических задач для дальнейшего применения их в специальных дисциплинах и практической деятельности. Задачи взяты из [1-10]. Некоторые задачи упрощены, учитывая небольшой объем часов практических занятий. Для успешного прохождения практикума необходимо, чтобы студенты были знакомы с основами теории вероятностей и математической статистики в объеме [5 (гл.1, 2), 2], а также имели навыки работы в среде Microsoft Excel Выбор табличного процессора Excel как вычислительной среды обусловлен, с одной стороны, наличием в нем достаточно мощных инструментов для эконометрических расчетов (статистические функции, пакет анализа). С другой стороны, в Excel результат можно получить разными способами, в том числе легко сделать проверочные расчеты по формулам, не используя указанные инструменты. Еще одним преимуществом Excel является доступность; несомненно, этот табличный процессор имеет большую популярность, чем любая система статистического анализа данных. Задания пособия использовались при проведении занятий по эконометрике со студентами различных специальностей дневного и вечернего отделения факультета «Экономика и управление» ГПИ МЭИ в 2005-2008 гг.
Практическая работа №1. Решение задач эконометрики с применением парной линейной регрессии Теоретическая часть Понятие тесноты связи Заметим, что сдвиг b нельзя считать объективной характеристикой зависимости Y от X, потому что его величина определяется выбором начала координат. Из соотношения (5), в частности, следует, что для МНК-оценок
Это соотношение связывает отклонения оценки отклика и фактора от их выборочных средних значений. Переход от величин к их отклонениям от среднего называется центрированием этих величин. Заметим, что значение На первый взгляд кажется, что по величине коэффициента
где введено обозначение:
Величина r называется выборочным коэффициентом корреляции (см. Приложение). Коэффициент r показывает, на сколько значений sy в среднем увеличится отклик, если фактор увеличится на sx. Говорят, что выборочный коэффициент корреляции характеризует тесноту связи между X и Y. Известно, что |r| ≤ 1. Чем ближе |r| к 1, тем теснее связь между X и Y; чем ближе |r| к 0, тем слабее связь. При r=±1 точки наблюдений лежат на прямой, задаваемой соотношением (2). При r=0 прямая (2) параллельна оси абсцисс, и связь между X и Y отсутствует. Примеры тесной и слабой связи даны на рис.2.
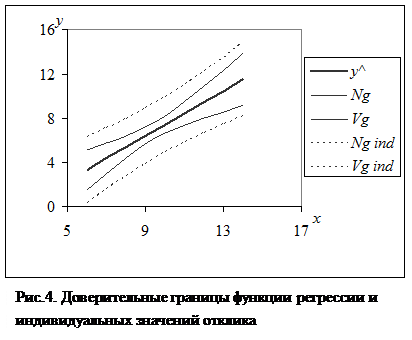
Теоретическая часть Постановка задачи Продолжаем исследовать зависимость добычи угля на 1 рабочего (Y) от толщины угольного пласта (Х) (см. таблицу 1). Требуется: 1. Найти с надежностью γ =0, 95 интервальные оценки коэффициента регрессии m и дисперсии s2 возмущений. 2. Построить 95-процентные доверительные интервалы линии регрессии и индивидуальных значений отклика. 3. Повторить п.п.1-2 для доверительной вероятности 0, 9. 2.2. Выполнение задания в среде Excel Доверительный интервал коэффициента регрессии определяем по формуле (18). В практической работе №1 уже нашли: Для расчета интервальной оценки дисперсии возмущений в формулу (19) подставляем значение Qe=8, 39 из таблицы 3. Квантили распределения хи-квадрат находим, применяя функцию ХИ2ОБР: c2(0, 025; 8)=17, 53, c2(0, 975; 8)=2, 18. Получаем 95-процентный доверительный интервал дисперсии возмущений: 0, 479≤ s2≤ 3, 85. Расчеты доверительных границ функции регрессии и индивидуальных значений отклика приведены в таблице 5. Рассматривался немного более широкий диапазон x, чем диапазон наблюдений. Значения
Графики доверительных границ, построенные по таблице 5, показаны на рис. 4.
Таблица 5. Расчеты доверительного интервала функции регрессии
Для быстрого выполнения расчетов необходимо грамотно использовать абсолютные адреса ячеек Excel. Так, например, чтобы провести вычисления для двух значений доверительной вероятности (γ =0, 95 и γ =0, 9) достаточно:
3. Задание на самостоятельную работу. Продолжаем исследование зависимости доли расходов на продовольственные товары в общих расходах (Y) от средней дневной заработной платы одного работающего (X) в семи территориях Уральского региона (таблица 4). Необходимо провести расчеты доверительных интервалов параметров линейной регрессии по аналогии с §2. Теоретическая часть О выборе линейной модели В настоящем пособии рассматривается только линейная регрессионная модель. Такой выбор обусловлен, с одной стороны, ограниченным объемом практикума, а, с другой стороны, тем, что именно линейная модель чаще всего используется в эконометрических исследованиях. Причины, по которым предположение о линейности связи Y(X) получило распространение, перечислены ниже (см., например, [5]): 1. Простота линейной модели. 2. Для линейной модели характерен меньший риск существенной ошибки прогноза. 3. Если двумерная случайная величина (X, Y) имеет нормальное распределение, то уравнение регрессии Y(X) является линейным (также как и уравнение регрессии X(Y)). Предположение о нормальном распределении часто является вполне обоснованным. 4. Многие традиционно используемые в эконометрике зависимости Y от X можно свести к линейной модели заменой переменных (например, для экспоненциальной зависимости достаточно вместо Y рассмотреть lnY). 5. Большинство «гладких» нелинейных зависимостей можно привести к линейным (DY»f′ DX при малом DX). Насколько хорошо линейная (и любая другая) модель соответствует реальному объекту можно судить лишь продолжая наблюдения над объектом и сравнивая прогнозируемые значения величин с реальными. Математические аспекты анализа качества линейной модели рассматривались в §1.5. Таблица 11. Оценки коэффициентов регрессии
Поясним смысл столбца «Значимость F» таблицы 10. В нем приведено минимальное значение amin, такое что при a³ amin выполняется неравенство (35), и, следовательно, гипотеза о незначимости регрессии отвергается. Аналогично в столбце «P-значение» таблицы 11 даны значения amin, такие что при a³ amin справедливо неравенство (37), с помощью которого определяется значимость коэффициентов регрессии. Читателю предлагается убедиться, что с помощью функции ЛИНЕЙН и окна Регрессия пакета анализа получились одинаковые результаты. Заметим, что пакет анализа использует функцию ЛИНЕЙН. 3. Задание на самостоятельную работу* Предприниматель намерен использовать множественный регрессионный анализ для оценки стоимости офисного здания в заданном районе, используя данные таблицы 12. Для этого предлагается выполнить следующую работу: 1. Определить уравнение регрессии и его характеристики. 2. Проанализировать значения коэффициентов детерминации (стандартного и адаптированного). Можно ли говорить о сильной зависимости между объясняющими переменными и стоимостью здания? 3. Проверить значимость уравнения регрессии по критерию Фишера при уровне значимости 0, 05. 4. Построить доверительные интервалы для коэффициентов уравнения регрессии. 5. Проверить значимость коэффициентов уравнения регрессии при уровне значимости 0, 05. Все ли факторы полезны при оценке стоимости здания?
Таблица 12. Данные по стоимости офисных зданий
Теоретическая часть Метод скользящего среднего Метод скользящего среднего (МСС) состоит в замене каждых k последовательных уровней ряда их средним значением. Величина k называется окном усреднения (сглаживания). Если k нечетно (k=2l+1, где l-целое положительное число), то скользящее среднее ut задается формулой:
Таким образом, среднее, вычисленное по k уровням ряда, приписывается к срединному моменту времени окна сглаживания. В приведенной выше формуле t=l+1, …, n-l. Следовательно, скользящее среднее не определено для l начальных и l конечных моментов времени. Переход от наблюдений Y к скользящему среднему позволяет «сгладить» ряд и получить значения, более близкие к тренду. Действительно, если разброс значений yt около тренда характеризуется дисперсией s2, то разброс среднего по k уровням ряда будет характеризоваться существенно меньшей дисперсией (s2/k – при независимости случайных величин Y(t)). Если ряд содержит циклическую составляющую, то следует брать k равным ее периоду, чтобы отрицательные и положительные отклонения от тренда гасили друг друга. Рассмотрим случай четного k (k=2l). Предположим, что вычислили среднее значение для 2l моментов времени, начиная с t0: t0, t0+1, …, t0+l-1, t0+l, …, t0+2l-1.Середина такого интервала находится между t0+l-1 и t0+l; поэтому непонятно, к какому моменту привязать значение скользящего среднего. Выход состоит в следующем: приписываем среднее любому из этих моментов, например, меньшему – t0+l-1, а затем полученный ряд еще раз сглаживаем с окном k1=2, так чтобы скользящее среднее было правильно привязано к центру окна. Эта процедура поясняется также на примере (см. §2.3.4). Сравним два метода оценивания тренда: аналитический (см. §1.3) и МСС. Первое преимущество МСС состоит в том, что он не требует никаких предположений о характере зависимости T(t); вторым его достоинством является простота вычислений. Очевидный недостаток МСС состоит в отсутствии оценок тренда для первых и последних наблюдений. Кроме того, МСС дает только оценки тренда для моментов наблюдений, и не дает формулу зависимости T(t). Если ряд имеет циклическую компоненту, то ее значения можно вычислить после определения тренда. Пренебрегая случайными возмущениями, для аддитивной модели ряда из формулы (40) получаем: S»Y-T, (43) для мультипликативной модели из формулы (41) получаем: S»Y/T. (44) Полученные приближенные значения циклической составляющей далее обрабатываются следующим образом:
Задание Для временного ряда, представленного таблицей 13 «Динамика выпуска продукции Финляндии»* выполнить следующие исследования: 1. С помощью мастера диаграмм получить уравнение, график и значение коэффициента детерминации R2 для следующих трендов: линейного, логарифмического, степенного, полиномиального третьей и шестой степени, экспоненциального. 2. Выбрать из полученных трендов наиболее соответствующий наблюдениям и логике задачи. 3. Исследовать показательный тренд с помощью функции ЛГРФПРИБЛ.
Таблица 13. Динамика выпуска продукции Финляндии
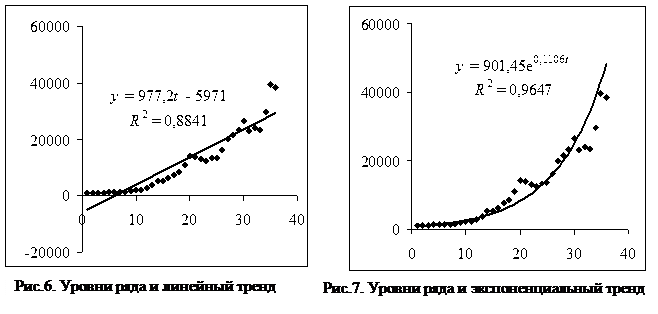
Выполнение Перед построением диаграмм необходимо преобразовать таблицу 13. Во-первых, надо перейти от четырех к двум столбцам (t – год, y – выпуск продукции). Во-вторых, рекомендуется нумеровать рассматриваемые годы, начиная с единицы (сдвинуть начало отсчета времени в точку t=1960); если оставить исходную нумерацию годов, то некоторые коэффициенты уравнений (например, сдвиг в линейном тренде) будут иметь очень большие значения (~106). Уровни ряда показываем на координатной плоскости (t, y). Для этого выделяем преобразованную таблицу, вызываем мастер диаграмм и выбираем точечную диаграмму без соединительных линий (см. рис. 6).
Наибольшее значение R2 имеет полиномиальный тренд 6-й степени. Однако использование полиномиального тренда обычно приводит к большому риску существенной ошибки прогноза. Поэтому выбираем экспоненциальный тренд, который имеет лишь на 0, 008 меньшее значение R2. Заметим, что линейный тренд, который также имеет достаточно большое значение R2, использовать не стоит, так как для начальных значений t он дает отрицательные оценки выпуска продукции y. Для анализа показательного тренда (y=bmt) можно использовать функцию ЛГРФПРИБЛ. Эта функция работает так же, как функция ЛИНЕЙН для линейного тренда. Результаты функции расположены, как показано в таблице 2. В таблице 15 приведены результаты применения ЛГРФПРИБЛ к исследуемым данным. Учитывая, что показательный и экспоненциальный тренды однозначно связаны друг с другом, можно сравнить значения параметров тренда из таблицы 15 и рисунка 7:
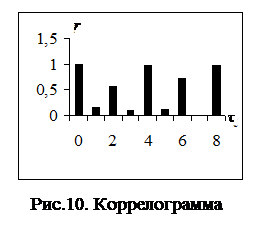
Задание 1 В таблице 18 представлены данные об объеме y потребления энергии за четыре года (время t измеряется в кварталах). Сгладить временной ряд методом скользящего среднего, самостоятельно подобрав размер k окна сглаживания. 2.4.2. Выполнение задания 1 Из графика зависимости y(t) (см. рис. 9) видно, что временной ряд содержит циклическую компоненту с периодом Tп=4. Рассчитав с помощью функции КОРРЕЛ выборочный коэффициент автокорреляции r(1, t) (см. таблицу 19) и построив коррелограмму (с помощью мастера диаграмм – см. рис.10), получаем, что максимум коэффициента автокорреляции имеет место при значениях t, кратных четырем; это подтверждает (см. §1.2), что Tп=4. Окно сглаживания следует выбрать равным (см. §1.5) периоду циклической составляющей: k=Tп=4. Тогда результатом сглаживания будет являться приближенный тренд (за период положительные и отрицательные значения циклической составляющей будут компенсировать друг друга). В третьем столбце таблицы 18 приведены результаты расчета скользящего среднего u1(t) для k=4. Средняя точка tср окна сглаживания находится между вторым и третьим моментом времени окна. Так, например, для первого окна (содержащего моменты времени t=1, 2, 3, 4) tср=2, 5; такого момента времени в наших данных нет, и мы приписываем среднее значение наблюдений по окну моменту t=2. Для второго окна tср=3, 5, и среднее значение наблюдений по второму окну будет приписано моменту t=3. Аналогично, среднее значение наблюдений для каждого следующего скользящего окна мы будем приписывать второму моменту времени этого окна. Для установки соответствия между средним значением наблюдений по окну и серединой окна tср необходимо применить к u1(t) метод скользящего среднего с окном сглаживания, равным двум: u2(t)=[u1(t-1)+u1(t)]/2. Результаты расчета приведены в таблице 18 (четвертый столбец). Напомним (см. также §1.5), что расчет u2 нужен только в случае четного k. Для нечетного k средняя точка окна сглаживания tср совпадает с одним из имеющихся в таблице моментов времени. Таблица 18. Расчет тренда и циклической составляющей
Таблица 19. Коэффициент автокорреляции.
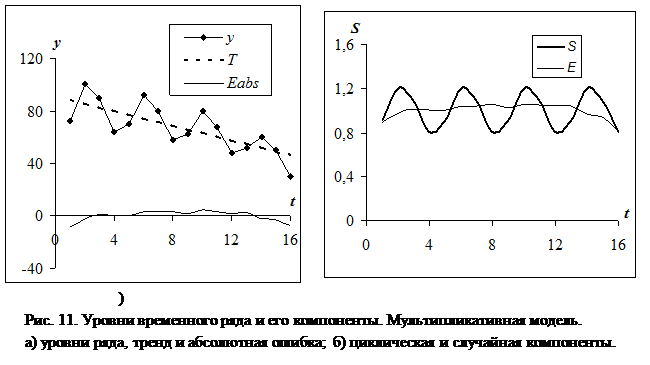
Задание 2 Вычислить значения циклической компоненты временного ряда по данным таблицы 18. Результаты записать в эту же таблицу. 2.4.4. Выполнение задания 2 Рассматриваемый временной ряд описывается аддитивной моделью, так как амплитуда колебаний уровней ряда практически не зависит от времени (см. рис. 9). По формуле (43) (учитывая, что T»u2) рассчитываем S1 – первое приближение циклической компоненты ряда. Значения S2 получены усреднением S1 по периодам. Так как среднее значение циклической компоненты за период для аддитивной модели ряда должно равняться нулю, то выравниваем значения S2: S3= S2-S2 ср, где через S2 ср обозначено среднее значение S2. Значения циклической компоненты S получены копированием S3 по всем периодам. Получив циклическую компоненту, вычислим следующее приближение тренда в предположении, что тренд линеен. Рассчитаем зашумленные значения тренда: T+E=Y-S (см. формулу (40)). Применив к этим значениям МНК (с помощью функции ЛИНЕЙН), получим следующую формулу: T(t)=0, 186t+5, 72. По этой формуле вычислим значения тренда, а затем, учитывая, что E=Y-T-S, – значения случайной компоненты E. На рис. 9 компоненты ряда показаны графически. Так как случайная компонента существенно меньше остальных компонент ряда, можно считать, что полученные оценки тренда и циклической составляющей вполне приемлемы. Задание 3 В первых двух столбцах таблицы 20 приведены поквартальные данные о прибыли компании (в усл. ед.) за последние четыре года. Определить трендовую, циклическую и случайную компоненты временного ряда. 2.4.6. Выполнение задания 3 Из графика зависимости y(t) (см. рис. 11, а) видно, что временной ряд содержит циклическую компоненту с периодом Tп=4. Построив коррелограмму (которая здесь не приводится), можно удостовериться, что максимум коэффициента автокорреляции имеет место при значениях t, кратных четырем; это подтверждает, что Tп=4. Окно сглаживания выбираем равным (см. §1.5) периоду циклической составляющей: k=Tп=4. В третьем и четвертом столбце таблицы 20 приведены результаты расчета приближений тренда u1(t) и u2(t), полученные так же, как в таблице 18. Для рассматриваемого временного ряда следует выбрать мультипликативную модель, так как амплитуда колебаний уровней ряда изменяется пропорционально тренду (см. рис. 11, а). По формуле (44) (учитывая, что T»u2) рассчитываем S1 – первое приближение циклической компоненты ряда. Значения S2 получены усреднением S1 по периодам. Так как среднее значение циклической компоненты за период для мультипликативной модели должно равняться единице, то от S2 переходим к следующему приближению циклической компоненты: S3= S2/S2 ср, где S2 ср – среднее значение S2. Значения циклической компоненты S получены копированием S3 по всем периодам. Далее вычислим следующее приближение тренда в предположении, что тренд линеен. Рассчитаем зашумленные значения тренда: TE=Y/S (см. формулу (41)). Применив к этим значениям МНК (с помощью функции ЛИНЕЙН), получим формулу для тренда: T(t)=-2, 77t+90, 57. По этой формуле вычислим значения тренда, а затем – значения случайной компоненты E (E=Y/(TS)). Абсолютная погрешность модели рассчитывается по формуле: Eabs=Y-TS. На рис. 11 компоненты ряда показаны графически. Заметим, что абсолютная погрешность существенно меньше уровней ряда и тренда. Кроме того, случайная компонента практически для всех значений t близка к единице. Поэтому оценки тренда и циклической составляющей вполне приемлемы.
Таблица 20. Данные о прибыли компании
3. Задание на самостоятельную работу 1. 2. В таблице 22** приведено среднее число y яиц на несушку на каждый месяц по США с 1938 по 1940 г. Требуется: 1) построить график y(t) и коррелограмму. Анализируя их, ответить на вопросы: содержит ли ряд линейный тренд? Содержит ли ряд циклическую составляющую? Чему равен период циклической составляющей Тц? Какая модель подходит для описания ряда – аддитивная или мультипликативная? 2) определить компоненты ряда. Таблица 22. Среднее число y яиц на несушку
3. В таблице 23 даны уровни некоторого ряда, время t измеряется в кварталах. Провести для этих данных исследования, аналогичные п.2. Таблица 23. Уровни ряда
Практическая работа №5. Использование фиктивных Теоретическая часть Выполнение Популярное:
|
Последнее изменение этой страницы: 2016-08-31; Просмотров: 2086; Нарушение авторского права страницы
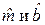 прямая, задаваемая уравнением (2), всегда проходит через точку (
прямая, задаваемая уравнением (2), всегда проходит через точку ( 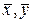 ). Подставив (5) в (2), после несложных преобразований получим:
). Подставив (5) в (2), после несложных преобразований получим:  . (6)
. (6) в соотношении (6) не присутствует.
в соотношении (6) не присутствует. можно судить о степени зависимости Y от X: чем больше
можно судить о степени зависимости Y от X: чем больше  sx (sy). Разделим обе части соотношения (6) на sy, а затем правую часть умножим и разделим на sx. Тогда получим:
sx (sy). Разделим обе части соотношения (6) на sy, а затем правую часть умножим и разделим на sx. Тогда получим:  (7)
(7)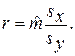

 1, 02,
1, 02,  =0, 207 (см. таблицу 3); t(0, 05; 8)=2, 31 (с помощью функции СТЬЮДРАСПОБР). Подставив эти значения в формулу (18), получаем 95-процентный доверительный интервал для коэффициента m: 0, 538≤ m≤ 1, 495.
=0, 207 (см. таблицу 3); t(0, 05; 8)=2, 31 (с помощью функции СТЬЮДРАСПОБР). Подставив эти значения в формулу (18), получаем 95-процентный доверительный интервал для коэффициента m: 0, 538≤ m≤ 1, 495.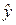 вычислялись по формуле (2),
вычислялись по формуле (2),  – по формуле (20), sy * – по формуле (23). Значения
– по формуле (20), sy * – по формуле (23). Значения 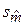 , s были взяты из таблицы 3. Через N (V) обозначена нижняя (верхняя) доверительная граница функции регрессии, через N инд (V инд) –нижняя (верхняя) доверительная граница индивидуальных значений отклика. В соответствии с соотношениями (21), (22) использовались формулы:
, s были взяты из таблицы 3. Через N (V) обозначена нижняя (верхняя) доверительная граница функции регрессии, через N инд (V инд) –нижняя (верхняя) доверительная граница индивидуальных значений отклика. В соответствии с соотношениями (21), (22) использовались формулы: 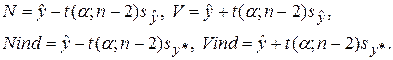
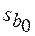 =1, 91
=1, 91
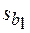 =0, 221
=0, 221
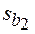 =0, 243
=0, 243
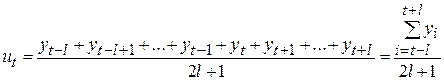 .
.
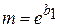 =e0, 1106=1, 12, b=b0=901, 45. Проверим значимость показательного тренда по критерию Фишера. Из таблицы 15 возьмем значение F-статистики: F= 929, 99; определим пороговое значение F-статистики с помощью функции FРАСПОБР: при a=0, 05 и n=36 f(a; 1; n-2)=4, 13. Так как неравенство (14) выполняется, то тренд значим.
=e0, 1106=1, 12, b=b0=901, 45. Проверим значимость показательного тренда по критерию Фишера. Из таблицы 15 возьмем значение F-статистики: F= 929, 99; определим пороговое значение F-статистики с помощью функции FРАСПОБР: при a=0, 05 и n=36 f(a; 1; n-2)=4, 13. Так как неравенство (14) выполняется, то тренд значим. Таблица 14. Значения R2
Таблица 14. Значения R2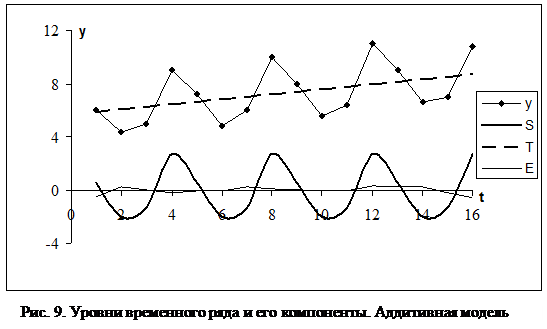
 r(τ )
r(τ )
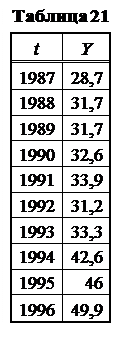 В таблице 21* представлены данные о производительности труда Y для некоторого предприятия с 1987 по 1996 г. Получить уравнения и графики трендов: линейного, логарифмического, степенного, полиномиального, экспоненциального. Выбрать из них тренд, наиболее соответствующий наблюдениям (сравнивая значение R2). Для выбранного тренда проверить гипотезу независимости остатков по критерию Дарбина-Уотсона (при n=10 dн=0, 88 dв=1, 32). Зачем надо проверять эту гипотезу?
В таблице 21* представлены данные о производительности труда Y для некоторого предприятия с 1987 по 1996 г. Получить уравнения и графики трендов: линейного, логарифмического, степенного, полиномиального, экспоненциального. Выбрать из них тренд, наиболее соответствующий наблюдениям (сравнивая значение R2). Для выбранного тренда проверить гипотезу независимости остатков по критерию Дарбина-Уотсона (при n=10 dн=0, 88 dв=1, 32). Зачем надо проверять эту гипотезу?