
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Классическая нормальная линейная модель множественной регрессии
Соотношение (24) называется классической нормальной линейной моделью множественной регрессии, если выполняются следующие условия:
Справедлива теорема Гаусса-Маркова: В условиях классической нормальной линейной модели множественной регрессии* оценки (28 )являются эффективными (т. е. имеют наименьшую дисперсию) в классе всех линейных несмещенных оценок. Кроме того, можно доказать (см., например, [5]), что в условиях классической нормальной модели множественной регрессии оценки (28) обладают следующими свойствами#: 1. b – несмещенная оценка вектора b (Mb=b). 2. Ковариационная матрица оценок b может быть вычислена по формуле: Db=s2(X¢ X)-1. (31) 3. bj (j=0, 1, …, p) являются нормальными случайными величинами. 4. Остаточная сумма квадратов Qe независима от b, а статистика
имеет распределение хи-квадрат с числом степеней свободы n-p-1 (c2n-p-1). 5. Статистика s2:
является несмещенной оценкой дисперсии возмущений (Ms2=s2). Значение числа степеней свободы n-p-1 можно объяснить следующим образом: из n наблюдений необходимо потратить p+1 наблюдений на оценку параметров регрессии. Оценивание значимости множественной регрессии Как и в случае парной регрессии, для оценивания качества оценок уравнения множественной регрессии используют критерии, вычисляемые через остаточную, регрессионную и полную суммы квадратов (см. §1.5 работы №1). Коэффициент детерминации R2 (см. формулу (12)) характеризует близость регрессионной модели к наблюдениям. Известно, что 0≤ R2 ≤ 1. Чем ближе R2 к 1, тем лучше уравнение регрессии соответствует наблюдениям. Если R2=1, то все остатки равны нулю. Если R2=0, то Известно, что коэффициент детерминации R2 возрастает с увеличением числа факторов. С другой стороны, добавление факторов не всегда улучшает качество модели. Поэтому в модели множественной регрессии предпочтительней (вместо R2) использовать нормированный (скорректированный, поправленный) коэффициент детерминации
При добавлении новых факторов, не оказывающих существенного влияния на отклик, Для множественной регрессии F-статистика Фишера вычисляется по следующей формуле, являющейся обобщением формулы (13) для парной регрессии:
Известно, что в условиях классической нормальной линейной регрессионной модели статистика (34) распределена по Фишеру со степенями свободы k1=p и k2=n-p-1. Обозначим через f(a; p; n-p-1) квантиль F-распределения уровня 1-a. Если уравнение регрессии незначимо, то большие значения статистики F маловероятны. Поэтому гипотезу о незначимости уравнения регрессии следует отклонять, если F> f(a; p; n-p-1). (35) Вероятность ошибки первого рода (отклонить гипотезу при условии, что она верна) при использовании правила (35) равна a. Проверка гипотезы о коэффициентах линейной регрессии Коэффициент bj незначим, если bj =0, j=1, …, p; в этом случае зависимая переменная Y не зависит от j-го фактора (т. е. фактор незначим). Проверим гипотезу Hj: bj =0. Оценка bj параметра bj имеет (см. §1.4) нормальное распределение
имеет распределение Стьюдента с n-p-1 степенями свободы. Если гипотеза Нj верна, то
и большие по модулю значения статистики (36а) маловероятны. Поэтому при выполнении неравенства |Tj |> t(a; n-p-1), (37) где t(a; n-p-1) – квантиль распределения Стьюдента уровня 1-a, гипотезу Нj следует отклонить. Вероятность ошибки первого рода при использовании правила (37) равна a. Проверяя неравенство (37), можно определить, какие факторы надо исключить из модели множественной регрессии как незначимые. Популярное:
|
Последнее изменение этой страницы: 2016-08-31; Просмотров: 1571; Нарушение авторского права страницы
 (32)
(32)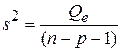 (32а)
(32а)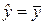 , и регрессионная модель в качестве оценки отклика дает его выборочное среднее.
, и регрессионная модель в качестве оценки отклика дает его выборочное среднее. :
: 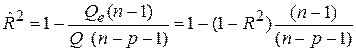 . (33)
. (33) (34)
(34) , причем дисперсия
, причем дисперсия 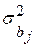 определяется как j-й диагональный элемент матрицы (31). Среднее квадратичное отклонение возмущений s обычно неизвестно, и в (31) s заменяют на s (см. формулу (32а)); выборочную дисперсию, полученную в результате такой замены, обозначим
определяется как j-й диагональный элемент матрицы (31). Среднее квадратичное отклонение возмущений s обычно неизвестно, и в (31) s заменяют на s (см. формулу (32а)); выборочную дисперсию, полученную в результате такой замены, обозначим  . Так как bj и s независимы, то статистика
. Так как bj и s независимы, то статистика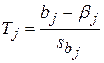 (36)
(36)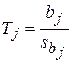 , (36а)
, (36а)