
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Порядок выполнения работы в системе STATISTICA
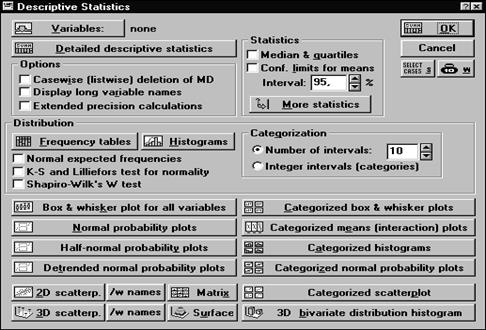
1. Откройте из Windows переключатель модулей системы STATISTICA и выделите в нем строку Basic Statistics/Tables - Основные статистики/таблицы. Щелкните по ней мышью либо нажмите кнопку Switch То - Переключиться в. Перед вами появится стартовая панель модуля, в которой предлагается меню методов и кнопка открытия файла данных, которые впоследствии будут обрабатываться. 2. Прежде всего, откройте файл данных, для чего инициируйте кнопку Open_Data – Открыть данные в правом нижнем углу окна. Укажите диск, на котором находятся ваши данные. Выберите заданный файл Nagruzka.sta, дважды щелкнув на имени файла либо высветив его имя и нажав ОК (либо высветив имя и нажав просто ENTER на своей клавиатуре, подтвердив тем самым выбор). После того как файл открыт, вы вновь окажетесь в стартовом окне модуля. 3. Для того чтобы создать файл регистрации всего вывода - автоотчет, вызовите диалоговое окно Page/Output Setup - Параметры страницы/вывода, выберите опцию Automatically Print All graphs - Автоматически печатать все графики и установите флажок в поле Window в рамке Output - Вывод. Диалоговое окно Page/Output Setup - Параметры страницы/вывода может быть вызвано с помощью меню File - Файл или двойного нажатия мыши на поле Output - Вывод в строке состояния внизу окна STATISTICA. 4. Выберите в предлагаемом меню методов верхнюю строчку Discriptive Statistics - Описательные статистики, дважды щелкнув по словам Discriptive Statistics либо выделив их цветом и щелкнув на кнопку ОК. Перед вами откроется диалоговое окно Описательные статистики (рис. 1).
Рис. 1. Окно Описательные статистики
5. Начните с выбора переменных. Щелчком по кнопке Variables - Переменные откройте окно: Selеct the variables for analysis - Выбрать переменные для анализа. Переменные можно выбрать несколькими способами, например, задать номера переменных в строке Select variables - Выбрать переменные либо высветить их. Если вы хотите выбрать сразу все переменные в файле данных, щелкните по кнопке Select All - Выбрать все. Выберите для анализа необходимые переменные, высветив их имена и нажмите ОК. Вы вновь окажитесь в окне Описательные статистики. В окне Описательные статистики имеется несколько групп кнопок. Обратите внимание на кнопку Detailed descriptive statistics - Детальные описательные статистики, которая позволяет просмотреть всевозможные описательные статистики выбранных переменных. Справа от нее находится группа кнопок Statistics - Статистики. Здесь можно задать дополнительные статистики: Median& quartile - Медиана и квартиль, Conf. limit for means - Доверительные границы для среднего. В строке Alpha error - Альфа ошибка задается уровень значимости. 6. Выполните расширенный набор описательных статистик, для этого щелкните по кнопке Моre statistics - Еще статистик. Перед вами появится следующее меню (рис. 2). Пометьте дополнительные статистики, которые вы хотите вычислить, например, variance - дисперсию, rаnge - размах, skewness - коэффициент асимметрии, kurtosis - коэффициент эксцесса и другие. Выбрав нужные статистики, щелкните ОК и вернитесь обратно.
7. Щелкните далее по кнопке Detailed descriptive statistics - Детальные описательные статистики, и вы увидите первый результат ваших действий - таблицу описательных статистик. В таблице слева направо записаны имена переменных, число случаев для каждой переменной, mean - среднее значение по случаям, minimum - минимум, maximum - максимум переменной, std.dev. - стандартное отклонение. Просмотрев значения статистик в таблице, щелкните по кнопке Continue - продолжить в левом верхнем углу таблицы и продолжите диалог, вернувшись в окно Описательные статистики. 8. Определите среднее, минимальное, максимальное значение для выпадений микроэлементов (сравните их с приводимыми в специальной геохимической литературе - используйте полученные знания по курсу геохимии ландшафтов и др.). Сделайте предварительную оценку близости распределения для выбранных микроэлементов по величине показателей выборочной ассиметрии и эксцесса (для нормального распределения коэффициент ассиметрии близок к 0, нормальное распределение симметрично при коэффициенте эксцесса =3. Если выборочная ассиметрия и эксцесс сильно отличаются от этих величин, то это позволяет усомниться в гипотезе о нормальности выборки. Существует и следующей способ проверки близости к нормальному типу распределения по отношению стандартного отклонения к среднему арифметическому (33% при нормальном распределении, при не очень жестком допущении - до 50%). 9. Построить таблицу частот или гистограмму выборки можно с помощью кнопок, объединенных в группу Distribution - Распределение. С помощью них можно просмотреть таблицу частот - кнопка Frequency tables – Таблицы частот, построить гистограммы значений переменных - кнопка Histograms – Гистограммы. Число групп для построения гистограммы оценивается по формуле Стержесса (Sturgess): k = 1+3.32lg(n) = 1.44ln(n)+1, где k – число групп; n – численность совокупности. 10. На гистограмму, при желании, можно наложить плотность нормального распределения, проверить согласие данных с нормальным законом с помощью критериев Колмогорова-Смирнова, Лилиефорса, вычислить статистику Шапиро-Уилкса (соответствующие значения будут указаны вверху графика). Сделайте выводы о близости распределений выбранных микроэлементов к нормальному. Очень эффектным графическим способом оценки близости данных к нормальному типу распределения является график на нормальной вероятностной бумаге. Такая проверка осуществляется выбором кнопки Normal Probilataly Plot. При распределении близком к нормальному данные должны ложиться на прямой. 11. Справа от группы кнопок находятся две опции Categorization - Группировка, позволяющие сгруппировать значения переменных. Кнопки, находящиеся в нижней части панели, связаны с различными способами визуализации данных и их описательных статистик. В нашем случае используя эту опцию Integer intervals-Целые интервалы можно визуально оценить структуру данных по расположению точек отбора (проведите эти операцию для переменных Тип землепользования, Тип ландшафта (КЛАСС2). 12. Кроме этого данный модуль позволяет осуществить подробный графический категориальный анализ данных. Эти опции расположены в нижней правой части и объединены общим словом Categoriens. Можно графически определить различия в средних для разных групп данных (выполните эту операцию для оценки влияния городов на выпадения микроэлементов со снегом)- первые две опции; оценить нормальность распределения для разных категорий и другие задачи. Подгонка данных к тому или иному типу распределения может быть осуществлена в модуле Непараметрическая статистика (рис.4). Для этого откройте из Windows переключатель модулей системы STATISTICA и выделите в нем строку Nonparametric stats – Непараметрическая статистика. Щелкните по ней мышью либо нажмите кнопку Switch То - Переключиться в. Перед вами появится стартовая панель модуля, в которой предлагается меню методов и кнопка открытия файла данных, которые впоследствии будут обрабатываться. Сделайте установки, как показано на рис.4 и рис.5 Проведите подгонку типа распределения и сделайте выводы. (Для графического способа подгонки нажмите кнопку Graph. Обратите внимание на значение критерия Колмогорова-Смирнова). 13. В этом же модуле можно рассчитать такие описательные статистики как мода, среднее геометрическое и др. Выберите этот модуль и установите все значения как показано на рис.5.Рассчитайте также моду среднее геометрическое (при логнормальном распределении может рассматриваться как некое наиболее вероятное (или в данном случае фоновое значение). 14. Осуществите преобразование ваших данных. Создайте для каждого из рассматриваемых вами микроэлементов новые столбцы, используя для этого кнопку VARS - Переменные. Например: Вам необходимо создать новую переменную, которая представляет из себя логарифмы выпадений для марганца (логарифмирование логнормальнораспределенных данных приближает их к нормальному типу распределения). Щелкните мышью на столбце MN. После этого нажмите кнопку Vars и выберите опцию Adds. Нажмите ОК. В результате вы получите новую переменную. Щелкните два раза на имени новой переменной и произведите необходимые настройки, как показано на рис. 6. Аналогичным образом проведите логарифмирование данных для всех рассматриваемых вами микроэлементов. После этого проведите заново оценку близости к нормальному типу распределения с помощью изложенных выше методов.
Рис.4. Меню Подгонка типа распределения
Рис.5. Меню Подгонка непрерывных распределений
Рис. 6. Меню Управления переменной Вопросы для самопроверки 1. Поясните понятия: медиана; верхняя квартиль; нижняя квартиль. 2. Что такое уровень значимости? 3. Что такое функция распределения? 4. Что такое функция плотности вероятности? 5. В чем заключается проверка статистических гипотез?
ЛАБОРАТОРНАЯ РАБОТА № 3 Тема: Моделирование загрязнения вод суши.
Продолжительность 4 часа
Задание: Используя программу РЕКА определить 1. На каком расстоянии от устья реки возможен сброс промышленных вод предприятия с сохранением в устье реки качества вод не превышающем ПДК. Предусмотреть случай уменьшения расхода реки на 30% (Табл.1). 2. Определить загрязнение реки на заданном километре от устья в результате сбросов группы предприятиятий. Оценить “вклад” в загрязнение каждым предприятием (Табл.2).
Расчеты основаны на " Методике расчета предельно допустимых сбросов (ПДС) веществ в водные объекты со сточными водами", ВНИИВО, Харьков 1990 г.
Модель водного объекта имеет следующий вид
где К – множество номеров расчетных створов, в которых моделируется качество воды; Yk – вектор показателей (концентраций веществ), характеризующих качество воды в створе k, г/м3; Yk-1 – то же для предшествующего по течению створа k-1 (если (k-1) Порядок работы: 1. Входим в директорию РЕКА и запускаем файл peka.exe. 2. С помощью кнопок " Река" и " Вариант" выбираем реку с которой будем работать. Кратко работу с программой можно пояснить так: вначале подготавливаются (редактируются) исходные данные для моделирования, затем запускается расчет и анализируются результаты либо в табличной, либо в графической форме с выводом на экран, либо на принтер. 3. Прежде чем запустить расчет загрязнения необходимо подготовить таблицу гидросети исследуемого водотока, таблицу источников сбросов загрязняющих веществ, таблицу притоков, таблицу загрязняющих веществ. Для этого выберите меню " Таблицы", затем из списка таблиц выберите название редактируемой таблицы. Таблица " Гидросеть" определяет графический вид гидросети (Меню Схема) и определяет гидрологические параметры моделирования. Добавить новую строку можно нажатием клавиши “Ins”, а удалить строку нажатием клавиши “Del”. Поля " Река" и " Вариант" при добавлении новой строки заполняются автоматически текущими значениями. Поле " Характеристика" может принимать следующие значения: л.с. - насел.пункт на левом берегу реки п.с. - насел.пункт на правом берегу реки л.р. - левый приток реки п.р. - правый приток реки сбр. - источник сброса В поле " Расстояние, км" задается расстояние от точки начала водотока (принимается за 0 км) до описываемого в данной табличной строке створа. Скорость и расход воды в основном водотоке на уровне данного створа заносятся в поля " Скорость, м/с" и " Расход, л/c". Если в таблице " Гидросеть" изменить поле " Река" или " Вариант" или и то и другое, то при сохранении Таблица с новым сочетанием " Река" и " Вариант" заменит Таблицу " Гидросеть" со старыми значенпиями " Река" и " Вариант". Будьте внимательны! Поля " Код реки" и " Номер ист.сбр." являются вспомогательными, их можно не вводить. Таблица " Притоки" имеет аналогична таблице источников сбросов. Для удаления строки из таблицы " Загрязняющие вещества" достаточно поставить в поле " Выбор" данной строки " -". После выхода из редактирования (Клавиша " Esc" ) с сохранением результата и повторного входа в данную таблицу этой строки уже не будет. 4. Запуск режима " Моделирование" формирует таблицу " Результаты моделирования". Количество загрязняющих веществ и их состав определяются исходной таблицей " Загрязняющие вещества" для выбранной реки и варианта. Сохраняется только последний вариант таблицы " Результаты моделирования", то есть новая таблица " Результаты моделирования" стирает старую таблицу 5. Режим " Схема" формирует и выводит слева на экран графическое представление гидросети реки и справа графики концентраций загрязняющих веществ. Для перемещения схемы и графиков вниз, вверх, вправо, влево по экрану необходимо поместить курсор мыши в крайнее положение на экране (вниз, вверх, вправо, влево) и щелкнуть левой кнопкой мыши. При этом изображение сдвинется в сорону противоположную от курсора. 6. Режим " Печать" позволяет распечатать таблицы на принтере и редактировать эти таблицы в текстовом редакторе Лексикон не выходя из программы РЕКА.
Контрольные вопросы 1. Приведите основные расчетные условия используемые при моделировании загрязнения вод суши с помощью программы РЕКА. 2. Какие исходные данные необходимы для выполнения расчета загрязнения поверхностного водотока с помощью программы РЕКА? 3. Что такое коэффициент неконсервативности загрязняющего вещества? 4. К какому классу моделей относится используемая модель водотока?
ЛАБОРАТОРНАЯ РАБОТА № 4 Тема: Применение корреляционного анализа в экологических исследованиях с использованием пакета прикладных программ " Olymp (СтатЭксперт)".
Продолжительность 4 часа
Основная цель работы: изучение особенностей применения корреляционного анализа в экологических исследованиях. Задание: используя данные о климатических и геоморфологических условиях в городах европейской части России (табл.1, 2), а также данные об аномальности магнитного поля (табл. 2) с помощью корреляционного анализа определите основные закономерности в распределении городского населения. Теоретическая часть: Наиболее употребительной статистической величиной является коэффициент корреляции, указывающий на тесноту и направление прямолинейной связи. Следует предостеречь исследователей от небрежного применения коэффициентов корреляции. Их можно применять только при следующих условиях: 1. Если зависимость прямолинейная, т. е. рой точек вытянут вдоль прямой. 2. Если распределение нормальное. Статистические связи между природными факторами могут по-разному и с различной теснотой проявляться на территориях разного масштаба. Так, на большом пространстве явно сказываются зональные связи, например, между почвами и растительностью. Сосна растет на песчаных и щебнистых почвах умеренного пояса, но на мелких участках, окруженных сосновыми борами, она вырастает и на болоте и на черноземе. Таким образом, каждая корреляция имеет характерный масштаб проявления, и с этим надо считаться при вычислении корреляционной зависимости. На фоновые корреляции накладываются локальные вариации, иногда совсем иного происхождения. То же относится и к регрессиям. Ход работы: 1. Запустите программу " Olymp (СтатЭксперт)". (Пуск-Программы-Olymp- СтатЭксперт) 2. Введите исходные данные по городам (Файл-Открыть). Таблицы (размещение файлов с: \olymp\tabl_1.asc, с: \olymp\tabl_2.asc, с: \olymp\tabl_3.asc. 3. Выделите в введенной таблице все данные кроме первого столбца. 4. Запустите корреляционный анализ (СтатЭкс-Корреляция). 5. В появившемся окне " Установки блока данных" установите ориентацию таблицы по колонкам и поставьте флажки в " Наличие наименований" для " наблюдений" и " переменных". Нажмите клавишу " Установить". 6. В окне " Корреляционный анализ" добавьте все переменные в " Список выбранных переменных" и нажмите кнопку " Вычислить". 7. При наличии пропущенных данных включите процедуру восстановления данных. (для пространственных данных рекомендуется использовать регрессионную модель (пошаговую). 8. Проведите анализ корреляционной таблицы, опишите основные закономерности. 9. Попробуйте самостоятельно (используя помощь ППП Olymp) применить необходимые группировки и построить гистограммы для дополнитнльного анализа основных закономерностей расселения городов. 10. Подготовьте отчет по проделанной работе работе. 11. Проведите частную и множественную корреляцию только с 3-5 рядами данных, показавшими наибольшие парные корреляции. Контрольные вопросы: 1. Перечислите задачи корреляционного анализа. 2. Перечислите основные условия применения корреляционного анализа. 3. В чем различие парных и частных коэффициентов корреляции? 4. Для чего применяется выборочный множественный коэффициент корреляции? 5. Какие критерии используются при корреляционном анализе?
ЛАБОРАТОРНАЯ РАБОТА № 5 Тема: Применение информационно-картографического подхода к анализу связей природных явлений Продолжительность 4 часа Задание: выполните пространственный анализ закономерностей между заданными преподавателем факторами информационным методом. Ход работы: Определите моделируемую систему, выделив компонент и факторы, определяющие состояние выбранного компонента. Подготовьте исходные данные, для этого: постройте с помощью ГИС ArcView 3.1 цифровые карты компонента и факторов. Далее необходимо разбить на зоны все карты так, чтобы и факторы и компоненты были разбиты на несколько интервалов. С помощью функции ГИС «Гистограмма по зонам» подготовьте данные для таблиц частот наблюдений для каждого однофакторного канала связи. Количество строк в каждой таблице равно количеству интервалов фактора, а количество столбцов равно количеству интервалов компонента.[1] С помощью компьютерной программы INFORM вычислите основные характеристики информационного анализа для каждой однофакторной связи «фактор Вi - компонент А». Выполните анализ полученных данных, при этом постарайтесь выяснить, в какой степени факторы влияют на компонент ПТК; где эта связь крепче или, наоборот, слабее; если каждому состоянию компонента соответствует определенный интервал значений факторов, то какой именно; каков объем экологической ниши, занимаемый каждым состоянием компонента в многомерном пространстве факторов; какие именно показатели определяют локализацию тех или иных состояний компонента на исследуемой территории. 1. на основе коэффициентов информативности постройте графики плотности связи, откладывая по оси ординат значения коэффициентов информативности фактора, а по оси абсцисс значения фактора. 2. Сопоставляя значения коэффициентов эффективности передачи информации от факторов к компоненту в однофакторных каналах связи «компонент В – фактор Аi» определите: а) ведущий фактор в определении пространственного поведения компонента; б) порядок значимости факторов в поведении компонента. 3. Постройте карту плотности связи для ведущего фактора. 4. Выявите с помощью коэффициентов информативности и коэффициентов связи: а) участки наибольшей и минимальной информативности факторов о компоненте; б) взаимоспецифичные состояния (С(ai|bj)> 1). На основании коэффициентов связи определите экологические амплитуды типологических единиц компонента по каждому фактору. Положение коэффициентов связи ( знаков «+» для С(ai|bj)> 1) прямо указывает на пределы крайних значений фактора, при которых встречается то или иное состояние компонента, т. е. характеризует амплитуду устойчивости данного варианта компонента по отношению к рассматриваемому фактору. Разновидностью экологической амплитуды является относительная мера устойчивости по отношению к тому или иному фактору. Если для каждого фактора принять разность крайних значений, наблюдаемых на исследуемой территории за условную единицу, то экологическая амплитуда по каждому фактору для каждого варианта компонента может быть выражена как доля рассматриваемого интервала крайних значений фактора. Очевидно, что, чем больше доля в каждом конкретном случае, тем больше устойчивость того или иного варианта компонента к изменениям данного фактора. Таким образом, экологическая амплитуда по каждому фактору для каждого варианта компонента может выражаться как в реальных значениях данного фактора, так и как доля от условной единицы. Применение объективных экологических амплитуд, выраженных в долях единицы, значительно расширяет возможности анализа и позволяет получить ряд количественно подкрепленных выводов. Логично предположить, что чем больше средние значения экологической амплитуды по рассматриваемому фактору, тем больше приспособленность данной группы типологических единиц компонента к изменениям фактора; чем меньше среднее значение экологической амплитуды по фактору, тем больше значимость этого показателя в пространственном поведении данной группы типологических единиц компонента. Информационно-картографический анализ открывает широкие возможности для объективного изучения пространственных связей природных явлений.
Вопросы для самопроверки 1. Как на основе информационного анализа сделать прогноз компонента по заданной совокупности значений факторов? 2. Какова точность информационного анализа? 3. Перечислите преимущества и недостатки информационного анализа.
ЛАБОРАТОРНАЯ РАБОТА № 6 Тема: Создание оценочной и типологической синтетических карт природно-рекреационного потенциала геосистем Мордовии
Продолжительность 4 часа
Задание: выполните оценку рекреационного потенциала районов республики с помощью следующих наборов показателей: процент лесистости, густота речной, овражной, транспортной сетей, густота дорог с твердым покрытием, доступность от столицы, удельный региональный выброс загрязняющих веществ в атмосферу, техногенная нагрузка на водные объекты в расчете на душу населения, на 1 км.кв. водотока, число рекреационных учреждений, природных объектов на основе карт оценочной и типологической классификации.
Ход работы: Основные этапы выполнения работы представлены на рис. 1. 1. Подготовьте исходные данные для проведения моделирования. ESTIMATE.EXE – файл программы оценочной классификации; WEIGHT.DAT – файл весовых коэффициентов показателей; STANDART.DAT – файл эталонных значений показателей; RECREAC.DAT – файл исходных данных (23 района, 11 показателей); 2. Запустите программу ESTIMATE.EXE для создания файла с евклидовыми расстояниями районов от эталонного района (REZULT1.DAT). 3. Используя данные файла REZULT1.DAT вручную проведите оценочную классификацию, желательно различными методами. 4. “Привяжите” результаты классификации к карте Республики в ГИС ArcView3.1. 5. Подготовьте оценочную карту по данным файла REZULT1.DAT используя методы классификации ГИС ArcView3.1. 6. Проведите оценку полученных вариантов классификаций. Выберите наилучший вариант. 7. Попробуйте выполнить оценочную классификацию с измененными весовыми коэффициентами, количеством показателей и количеством районов. Проанализируйте результаты классификации. 8. Используя программу TYPOLOG.EXE проведите на тех же исходных данных типологическую классификацию природно-рекреационного потенциала геосистем Мордовии задавая различное число таксонов. 9. Преобразуйте полигональные темы в GRID-темы. 10. Используя картографический калькулятор (Map Calculator) модуля Spatial Analyst ГИС ArcView3.1. 11. По полученным результатам постройте карты в ГИС ArcView3.1. 12. Подготовьте в редакторе Word отчет.
Рис.1 Блок-схема алгоритма выполнения лабораторной работы.
Контрольные вопросы: 11. С какой целью используются весовые коэффициенты в используемых алгоритмах классификаций? 12. Как задействовать нечисловые данные в алгоритмах классификаций? 13. Как оценить результаты классификаций при выборе наилучшего варианта? 14. Каковы особенности классификаций в ГИС ArcView3.1?
ЛАБОРАТОРНАЯ РАБОТА № 7 Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 897; Нарушение авторского права страницы
 Комментарий: другие описательные статистики, в частности процентили, мода доступны в опции Описательные статистики в модуле Непараметрическая статистика.
Комментарий: другие описательные статистики, в частности процентили, мода доступны в опции Описательные статистики в модуле Непараметрическая статистика. 


 (*)
(*) K, то створ k-1 является начальным створом (истоком) реки и Y k-1 =(Сφ )k1, где (Сφ )k1 – вектор фоновых концентраций веществ в воде водотока в створе k-1, (г/м3); Yν – то же для створа ν, расположенного в устье притока, впадающего на участке (k, k-1); Сi – вектор максимальных среднечасовых концентраций веществ в сточных водах выпуска i, (г/м3); qi- расход сточных вод выпуска i, (м3/с); Qα - расход воды реки в расчетной секции α , (м3/с); α (i)- номер расчетной секции, в начале которой расположен выпуск сточных вод водопользователя i, (м3/с); Vk – множество номеров створов, расположенных в устьях притоков, впадающих на участке (k, k-1); Ik – множество номеров выпуска сточных вод, поступающих в водный объект на участке (k, k-1); Ak, k-1 , Akv и Bki - матрицы, характеризующие разбавление и трансформацию качества речных и сточных вод;
K, то створ k-1 является начальным створом (истоком) реки и Y k-1 =(Сφ )k1, где (Сφ )k1 – вектор фоновых концентраций веществ в воде водотока в створе k-1, (г/м3); Yν – то же для створа ν, расположенного в устье притока, впадающего на участке (k, k-1); Сi – вектор максимальных среднечасовых концентраций веществ в сточных водах выпуска i, (г/м3); qi- расход сточных вод выпуска i, (м3/с); Qα - расход воды реки в расчетной секции α , (м3/с); α (i)- номер расчетной секции, в начале которой расположен выпуск сточных вод водопользователя i, (м3/с); Vk – множество номеров створов, расположенных в устьях притоков, впадающих на участке (k, k-1); Ik – множество номеров выпуска сточных вод, поступающих в водный объект на участке (k, k-1); Ak, k-1 , Akv и Bki - матрицы, характеризующие разбавление и трансформацию качества речных и сточных вод; 
