
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Метод максимального счета (MSCORE)
Рассмотрим особенности метода максимального счета, применяемого наряду с методом максимального правдоподобия для оценки параметров модели бинарного выбора. Этот метод использует критерий, представляющий собой максимум числа совпадений реальных и расчетных ответов, который критерий можно представить в следующем виде: Max a Sb( a )=
Параметр b – это установленный квантиль; sgn( a ¢ x t) – знак числа a ¢ x t; zt=2yt –1 (zt =–1, если yt=0; zt=1, если yt=1). Если b=1, метод максимального счета выбирает оценку параметров a таким образом, чтобы максимизировать число раз, когда a ¢ x t имеет тот же знак, что и zt. Метод по своей сути является полупараметрическим, поскольку он использует не параметры распределений, а их заменители. Оценки параметров a i (i=1, 2, …, n) определяются путем перебора возможных их сочетаний при заданном уровне точности (например, 0, 0001) с учетом ограничения Так как метод максимального счета не предполагает вычисление функции правдоподобия, то невозможно определить и информационную матрицу для определения стандартных ошибок оценок. Чтобы получить представление об изменчивости оценок, обычно используется метод самонастройки (bootstapping). Он заключается в следующем. После вычиcления набора оценок коэффициентов a T из выборки делается К случайных подвыборок, содержащих по t наблюдений. Для каждой k-й подвыборок метод максимального счета дает свои оценки a t(k). Тогда среднеквадратические отклонения можно оценить следующим образом:
Отметим еще раз, что элементы матрицы MSD не являются ковариациями соответствующих оценок, они лишь характеризуют их взаимную изменчивость. Преимущество полупараметрических методов оценки параметров состоит в том, что при их использовании не возникают ошибки, связанные с неправильным выбором закона распределения погрешностей модели. С другой стороны, нет никаких гарантий, что полученные на их основе оценки будут лучше, чем «параметрические». Существенным недостатком полупараметрических методов является то, что они требуют очень большого количества вычислений для получения оценок параметров. Это выдвигает определенные ограничения в отношении максимального еоличества параметров модели и объема исходной информации. Сейчас метод максимального счета не используется для оценки более чем 15 коэффициентов на основе 1500-2000 наблюдений. Еще один недостаток этого подхода обусловлен невозможностью параллельного получения вместе с оценками параметров дополнительной информации, относящейся к характеристикам качества модели, точности оценок и т. п. Для содержательного анализа влияния факторов на зависимую переменную очень важны маржинальные эффекты, а на основе полупараметрических методов оценить их также не представляется возможным. Как развитиеметода максимального счета можно рассматривать, предложенный его авторами метод вторичного анализа результатов. Этот метод позволяет получить оценки математического ожидания переменной yt, в зависимости от величин, влияющих на нее факторов. Рассмотрим основные положения этого метода. Пусть
F a (zt )=M[yt | a ¢ x t=zt] (10.212)
представляет собой гладкую функцию “отклика” yt на x t. Основываясь на векторе параметров оценок параметров a (полученном с помощью метода максимального счета), авторы предлагают построить F a (zt) с помощью так называемого kernel-метода. Для вектора оценок параметров a и известных значений независимых переменных x t (t=1,..., T) определим следующие значения:
zt= a ¢ x t, (10.213)
Для произвольного значения z*, принадлежащего области допустимых значений произведения a ¢ x, можно определить следующий набор весов (kernel-функций) wt (t=1,..., T):
где
и
Константа Функция F(z*) (в выражении (2.212)) определяется следующим образом:
где – наблюдаемые значения уt, t=1,..., T. Расчетные значения функции F(z*) при заданном наборе факторов х t обычно интерпретируются как математическое ожидание зависимой переменной yt (М[yt]). Вопросы к главе X 1. Каковы последствия ошибок измерений зависимой переменной? 2. Каковы последствия ошибок измерений независимых переменных? 3. Каковы последствия ошибок измерений и зависимой и независимых переменных? 4. Охарактеризуйте модели с фиктивными независимыими переменными. 5. Дайте классификацию моделей с дискретными заивисимыми переменными. 6. В чем состоит суть моделей бинарного выбора? 7. Какие законы распределений наиболее часто используются в моделях бинарного выбора? 8. В чем состоят недостатки линейной модели вероятности? 9. Охарактеризуйте модель бинарного выбора, исходящую из групповых данных? 10. Что собой представляет многомерная probit-модель? 11. Что собой представляют модели множественного выбора? 12. Какие типы моделей используются для описания выбора среди неупорядоченных альтернатив? 13. Каким образом моделируется выбор среди упорядоченных альтернатив? 14. Какие законы распределений используются в моделях счетных данных? 15. Охарактеризуйте последствия построения эконометрической модели на основе усеченной выборки? 16. Как изменяются математическое ожидание и дисперсия зависимой переменной, если при оценки параметров модели используется цензурированная выборка? 17. Охарактеризуйте модели случайно усеченных выборок. 18. Каковы особенности применения метода максимального правдоподобия для оценки параметров моделей с дискретными зависимыми переменными? 19. Как выглядят необходимые условия максимизации логарифма функции правдоподобия для моделей усеченных и цензурированных выборок? 20. Что собой представляет метод максимального счета? 21. В чем суть kernel-метода?
Упражнения к главе Х Задание 10.1 Logit-модель была применена к выборке, в которой y=1, если количество занятых в фирме выросло (y=0 – в противном случае), х1 – доход фирмы, в млн. $; х2=1, если фирма относится к области высоких технологий (х2=0 – в противном случае). Получена следующая модель:
Требуется определить оценку вероятности роста занятости для фирмы высокотехнологичной фирмы А с доходом в 5 млн. $ и для фирмы Б, не относящейся к сфере высоких технологий и имеющей доход 7 млн. $. Задание 10.2 Имеется выборка, состоящая из 528 наблюдений, в которой y=1, если заработная плата работника ниже 5$ в час (y=0 – в противном случае). Предполагается, что уровень заработной платы зависит от следующих факторов: х1 – образование, лет; х2 – пол (1–женский, 0 – мужской); х3 – опыт работы, лет. В табл. 10.1 приведены коэффициенты, полученные при оценке линейной регрессии y от х1, х2 и х3 с помощью МНК, и при оценке Logit-модели с помощью нелинейного МНК. Таблица 10.1
Требуется: 1. Определить на основе Logit-модели, оценку вероятности для мужчины и для женщины, имеющих 12 лет образования и 15 лет опыта работы, оказаться низкооплачиваемыми работниками. 2. Определить на основе Logit-модели, изменение оценки вероятности быть низко оплачиваемым работником для мужчины с характеристиками из п. 1, если он проучится на один год больше. 3. Ответить на вопросы п. 1–2 с использованием линейной регрессионной модели.
Задание 10.3 Имеется выборка, состоящая из 528 наблюдений, в которой y=1, если работник состоит в профсоюзе (y=0 – в противном случае). Предполагается, что членство в профсоюзе зависит от следующих факторов: х1 – образование, лет; х2 – пол (1–женский, 0 – мужской); х3 – опыт работы, лет; х4 – опыт работы в квадрате. Выборочные средние равны
На основе выборочных данных была получена следующая Probit-модель:
Требуется определить, насколько снижается вероятность быть членом профсоюза в расчете на год дополнительного образования.
Задание 10.4 Имеется набор данных, состоящий из 6 наблюдений.
Требуется: 1. Оценить линейную модель вероятности с помощью МНК. Рассчитать R2. 2. Использовать оцененную модель для разделения индивидуумов на 2 группы. Рассчитать количество случаев правильного отнесения к соответствующей группе, применяя следующее правило классификации: группа I (y=1), если группа II (y=0), если Сопоставьте долю правильного попадания и коэффициент детерминации.
Задание 10.5 Среди 48 респондентов был проведен опрос о среднемесячных затратах на табачные изделия. Полученные результаты представлены в табл. 10.2. Таблица 10.2
Требуется: 1. Определить по цензурированным данным МНК-оценку параметра Tobit-модели 2. Определить по усеченным на уровне 0 данным МНК-оценку параметра Tobit-модели. Задание 10.6 [1] В 1973 году в г. Трое (штат Мичиган) проводился референдум по вопросу о введении местного школьного налога. В ходе опроса были выявлялись определенные характеристики участников референдума (см. табл. 10.3). Таблица 10.3
Кроме того, YEARS=количество лет, прожитых в Трое; LogINC=натуральный логарифм годового дохода домашнего хозяйства, $; PTCON=натуральный логарифм суммы годовых платежей по налогу на имущество, $. Информация о 95 респондентах представлена в табл. 10.4 Таблица 10.4
Продолжение табл. 10.4
Продолжение табл. 10.4
Окончание табл. 10.4
Требуется: 1. Оценить параметры следующей модели: Prob(YESVM=1)=F(PUB1& 2, PUB3& 4, PUB5, PRIV, YEARS, SCHOOL, LogINC, PTCON) c использованием МНК, Probit- и Logit-процедур. 2. Рассчитать на основе модели, оцененной с помощью МНК, прогноз вероятности для каждого из респондентов проголосовать “за” введение местного школьного налога. Определить для скольких случаев прогнозное значение выходит за рамки интервала от 0 до 1.
Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 624; Нарушение авторского права страницы
 ( a ¢ x t)]*. (10.210)
( a ¢ x t)]*. (10.210)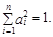





 (10.217)
(10.217)
 используется для стандартизации логистического распределения, которое применяется в kernel-функции; l – параметр сглаживания. Значения l должны быть досаточно велики, чтобы функция F(z*) была гладкой, использование маленьких, близких к нулю, значений l усиливает большую колебания функции. Хорошей теоретической основы для выбора l не существует, за исключением некоторых предположений, которые можно сделать на основе описательной статистики.
используется для стандартизации логистического распределения, которое применяется в kernel-функции; l – параметр сглаживания. Значения l должны быть досаточно велики, чтобы функция F(z*) была гладкой, использование маленьких, близких к нулю, значений l усиливает большую колебания функции. Хорошей теоретической основы для выбора l не существует, за исключением некоторых предположений, которые можно сделать на основе описательной статистики.





 где et ~N(0, s2), и уt = уt *, если уt*> 0, уt =0, если уt*£ 0.
где et ~N(0, s2), и уt = уt *, если уt*> 0, уt =0, если уt*£ 0.