
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Статистические характеристики, применяемые при статистических методах в управлении процессами
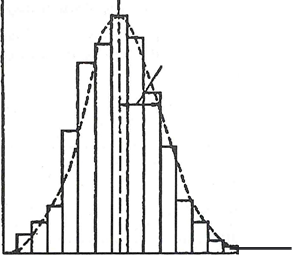
Предмет изучения статистики включает: – совокупность данных о множестве однородных объектов. Например, данные о количестве пассажиров, пользующихся метрополитеном в течение суток. – совокупность методов обработки данных с целью представления полученной информации более наглядной и понятной. Первым шагом анализа для статистического управления процессами в системе менеджмента качества является сбор данных и их обсуждение. Однако эти собранные данные должны быть эффективно используемыми. В связи с этим важно усвоить общие принципы сбора и систематизации данных в такой форме, в которой ими можно пользоваться. Кроме того, такие данные необходимо не только представить в виде графиков и таблиц, но и перевести в цифры для статистической оценки. Для этого целесообразно знать порядок расчета и природу средних квадратических отклонений значений параметров. Для сбора данных в первую очередь надо четко сформулировать его цель. На практике, однако, нередко бывает, что цель сбора данных неясна и это делают потому, что «всегда так делали» или «начальство приказало». Нет ничего странного в том, что данные, собранные таким образом, нельзя использовать. Необходимо, прежде всего, подумать, зачем и как использовать собранные данные, где лучше собрать данные, кому лучше всего поручить сбор данных, каким путем лучше собрать и т.п. Необходимо рассмотреть пять факторов, касающихся данных: 1. Зачем собирать данные? Цель сбора достаточно ясна? 2. Собираются ли сведения в местах, соответствующих цели, и путем, соответствующим цели? 3. Производятся ли измерения, соответствующие цели сбора? 4. Оценивают ли данные путем, соответствующим цели сбора? 5. Используются ли результаты сбора данных точно для цели? Цели сбора данных могут быть различными, но их можно сгруппировать на три большие группы: 1) Сбор данных для управления. Технологический процесс подвергается проверке на отсутствие отклонений. При выявлении какого-либо отклонения, выяснив и устранив его причину, обеспечивают нормализацию технологического процесса. Для этого часть продукции исследуется с целью получения данных. 2) Сбор данных для инспекции. Производится регистрация отклонений от нормы и сортировка изделий. Изделия с отклонениями изучаются для выявления причины отклонений и результаты сообщаются соответствующим подразделениям. 3) Сбор данных для анализа. Для уменьшения брака производится анализ условий и правильности порядка выполнения работы. Остановимся на общих принципах систематизации данных: I. Продумать систематизацию данных в положительную сторону. Предприятия с многономенклатурным мелкосерийным производством продукции нередко утверждают, что «вследствие большого разнообразия номенклатуры продукции представить данные о браке в виде графика невозможно». Тем не менее, какой бы широкий ни была номенклатура продукции, не может быть, чтобы причин появления брака было бы столь много. Одним словом, необходимо систематизировать данные таким образом, чтобы они помогали исключить возможность появления брака, то есть чтобы эта систематизация была прямо связана с прибылью компании. Так чтобы, рассмотрев данные, можно было бы сказать, в чем заключается проблема. II. Подготовить данные точно и аккуратно. Из опасения, что допущение брака может повлиять на оценку эффективности работы, действительное положение дел с браком не всегда отражается в данных. Кроме того, в тех случаях, когда в ходе технологического процесса производится ручная правка, либо же когда инспекция или проверка осуществляется самим производственным подразделением, нередко это не фиксируется в журнале брака. Подобные случаи необходимо регистрировать в контрольной ведомости. III. Систематизировать данные понятным способом. Данные нужно систематизировать понятно, так, чтобы менеджеры могли сразу же войти в суть проблемы и правильно и своевременно принять меры. Представляя данные в виде диаграмм, таких как диаграмма Парето, гистограмма, график разброса данных и др., можно наглядно увидеть суть проблемы. IV. Дифференцировать проблемы и ситуации цифрами. Кем вызвана данная проблема (опытным работником или стажером)? Когда (днем или вечером, в ясную или в дождливую погоду)? Где (в какой машине или устройстве)? Надо разделить проблемы и ситуации подобным образом, выразить условия происхождения брака цифрами и сопоставить данные – этот анализ послужит одним из ключей к разрешению проблемы. V. Выявить причинно-следственные отношения. Следуетзаранее представить причинно-следственные отношения в виде диаграммы «причины и следствия» для того, чтобы избавиться от необходимости выяснять причину проблемы после ее возникновения. VI. Использовать стандартные цифровые показатели. Используя уже имеющиеся стандартные цифровые показатели можно более точно оценить результаты деятельности. Стандарт может указывать среднее значение, исключающее ненормальные значения, либо же целевое значение, чуть завышенное, чем результаты в прошлом, как ориентир для того, чтобы работники прилагали больше усилий, стараясь достичь более высоких показателей. VII. Нельзя обманываться средними значениями. Чтобы избежать этого, возникает необходимость применения графика плотности распределения или среднего квадратического отклонения (нормального отклонения) (рис. 1).
Рис. 1. График плотности распределения и среднее квадратическое отклонение VIII. Привыкнуть к понятию «среднее значение», «дисперсия», «среднее квадратическое отклонение (сигма)» и др. Для количественного выражения характеристик генеральной совокупности, как правило, применяется среднее значение, дисперсия, среднее квадратическое отклонение и др. В случае обработки измеренных значений выборки: величины среднего, дисперсии и среднего квадратического отклонения несколько колеблются в зависимости от конкретной выборки, даже если они принадлежат одной и той же генеральной совокупности. Поэтому им дается общее название – статистические величины. Дисперсия, вычисляемая из пробы в качестве оценочной величины дисперсии совокупности, называется несмещенной дисперсией. Это означает оценочную величину, освобожденную от смещения дисперсии параметра.
Выражая данные в форме гистограммы, можно понять их в общих чертах. Чтобы войти в их суть более подробно, необходимо представить их в количественном выражении. Для этого применяются среднее ( (1) Среднее ( (2) Медиана ( Это значение, занимающее среднее место в единицах данных, расположенных в порядке по величине, когда число единиц данных нечетное. Так при 2, 3, 5, 6, 8 медианой служит 5.
Если число единиц данных четное, то медианой служит арифметическое среднее срединных двух членов. Так, при 2, 3, 4, 6, 7, 9
(3) Широта (R). Разность наибольшего и наименьшего значений данных называется широтой. Широта показывает широту распределения, то есть степень разброса данных. Надо отметить, что, сколько бы данных ни было, используются только две единицы данных, а именно наибольшее и наименьшее значения, независимо от числа промежуточных единиц данных. Так, при 2, 3, 4, 6, 7, 9, наибольшее значение = 9, наименьшее значение = 2, поэтому широта R = 9-2 = 7; (4) Среднее квадратическое отклонение. Среднее квадратическое отклонение, как и широта, дает ориентировочное представление о степени разброса данных. Теперь допустим, что в результате измерения массы изделий получены 40, 50, 60, 60, 90 г., и среднее значение составляет 60, 0. При этом рассчитываем степень отклонения каждого значения от среднего, то есть разность данного значения и среднего (называемую отклонением). Формула для расчета отклонения:
40-60 = -20 50-60 = -10 60-60 = 0 60-60 = 0 90-60 = 30 Итого 0
По данной формуле для расчета отклонения, если добавляется отклонение как оно есть, результат будет равен 0. Поэтому для проверки степени разброса одной единицы данных добавляют значение отклонения, возведенное в квадрат, с последующим делением на число единиц данных. Полученный результат называется дисперсией. Дисперсия рассчитывается по формуле: Дисперсия = Среднее квадратическое отклонение = Квадратный корень дисперсии называют средним квадратическим отклонением. Для лучшего понимания расчета среднего квадратического отклонения попытаемся объяснить более подробно. Допустим, что имеются два пакета данных, которые приведены ниже: (1) 50 50 50 50 100 (2) 40 50 60 60 90 Среднее каждого пакета данных равно 60, 0, а разность наибольшего и наименьшего значений (широта) – 50. Значит, два пакета данных одинаковы как по среднему ( s = В случае с пакетом 2 среднее квадратическое отклонение будет равно: s = Таким образом, мы выяснили, что пакеты данных 1 и 2 отличаются друг от друга по степени разброса данных. Значит, можно сказать, что степень разброса данных получается более точной, если выразить ее через среднее квадратическое отклонение. Кроме вышеизложенного порядка расчета среднего квадратического отклонения, приведем также и два-три упрощенных способа расчета: 1) Расчет на основе суммы квадратов отклонений (или суммы квадратов). Как излагалось ранее, под отклонением понимается разность значения данных и среднего (x - S = (x1 - Переписывая это уравнение, получим S =
Значит, S =
2) Дисперсия. При делении суммы квадратов отклонений, показывающей общую степень разброса данных, на число единиц данных получается мера разброса на единицу данных. Такая мера называется дисперсией, которая выражается через σ 2. σ 2 = Среднее квадратическое отклонение σ = 3) Несмещенная дисперсия. Значение, получаемое из выборки в качестве оценочного значения модуля, или параметра совокупности, называют несмещенной дисперсией. Это означает несмещенное оценочное значение дисперсии совокупности. Дисперсия генеральной совокупности (дисперсия совокупности) рассчитывается как σ 2 = Несмещенная дисперсия при оценке дисперсии совокупности на основе выборки рассчитывается как σ 2 = Следовательно, среднее квадратическое отклонение по совокупности рассматривается как σ = Если величина n велика, то n ≈ n – 1. При выборке малой порции пробы из совокупности средних квадратических отклонений σ среднее квадратическое отклонение пробы не равно среднему квадратическому отклонению по совокупности. Но все же при оценке среднего квадратического отклонения по совокупности на основе выборки (пробы) пользуются следующей формулой: Рассчитывая среднее и среднее квадратическое отклонение x, вычитают определенное значение (10) из каждой единицы данных в целях облегчения расчета. При этом к среднему нужно добавить 10, но можно оставить его без добавления, так как среднее квадратическое отклонение все равно не изменится. Среднее = Среднее квадратическое отклонение = Отсюда, прежде всего, определим S. S = Σ x2 - Отсюда S = 76 - Среднее квадратическое отклонение = Получаем среднее квадратическое отклонение Существует также экспресс-метод расчета среднего квадратического отклонения в случае большого числа данных. Данный метод применим в тех случаях, когда число данных слишком велико, либо же число разрядов данных велико, за счет чего усложняется сам расчет. Для облегчения расчета часто применяется прием преобразования переменных. К примеру, из частотной таблицы переписывают числовые интервалы и частоту f (табл.1). Табл. 1. Частотная таблица для расчета среднего квадратического отклонения
Определяют медиану в каждом числовом интервале. По таблице 1 медиана между значениями 16, 5 и 17, 5 равна 17. Делают то же и с остальными значениями. Затем определяют представительное значение. Представительное значение лежит ближе к середине, то есть к месту большой частоты. По таблице 1 этим значением является 25. Взяв это представительное значение за 0, записывают -1, -2, -3, …и т.д. вверх от 0. Затем вниз от 0 записывают +1, +2, …и т.д. (см. графу «U» в табл. 1). Далее вычисляют частоту f * U в каждом числовом интервале, полученный результат записывают в графу «Uf», и определяют сумму. Умножают Uf на U, что равносильно умножению U2 * f, записывают результат в графе «Uf2» и определяют сумму. Среднее По таблице 1 представительное значение равно 25, сумма Uf – 20, сумма частот f – 120, ширина интервалов, то есть разность представительных значений во взаимно соседствующих интервалах, -18-17=1. Следовательно из формулы выше Среднее квадратическое отклонение σ рассчитывается по формуле: σ = σ = В нашем конкретном случае среднее квадратическое отклонение σ = Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 636; Нарушение авторского права страницы
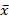 (икс с верхней чертой)
(икс с верхней чертой)
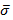 или s (сигма с шапкой)
или s (сигма с шапкой)
 ), медиана (
), медиана ( 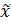 ), широта (R), среднее квадратичное отклонение, дисперсия и др.
), широта (R), среднее квадратичное отклонение, дисперсия и др.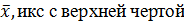 );
); 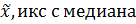 ).
).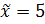
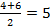
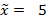 ;
; 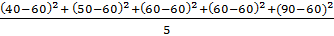 = 280
= 280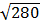 = 16, 7
= 16, 7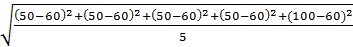 =
=  =
= 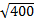 = 20, 0
= 20, 0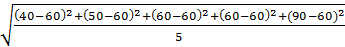 =
= 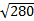 = 16, 7
= 16, 7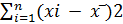
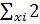 -
- 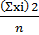
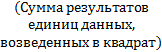 -
- 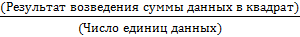

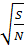
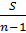
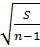
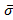 =
= 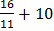 = 11, 45
= 11, 45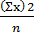
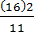 = 52, 8
= 52, 8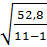 = 2, 3
= 2, 3 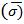 равное 2, 3.
равное 2, 3.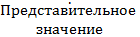 +
+  *
* 
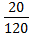 * 1 = 25, 17.
* 1 = 25, 17.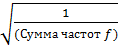 { (Сумма Uf2 –
{ (Сумма Uf2 – 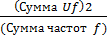 } * (Ширина интервалов);
} * (Ширина интервалов); 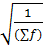 { (∑ Uf2 –
{ (∑ Uf2 – 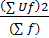 } * h
} * h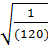 { (1644 –
{ (1644 – 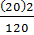 } * 1 =
} * 1 = 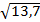 * 1 = 3, 7
* 1 = 3, 7