
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Экстраполяция методом сглаживания ряда динамики.
Суть различных приемов сглаживания сводится к замене фактических уровней временного ряда расчетными, которые в меньшей степени подвержены колебаниям. Это способствует более четкому проявлению тенденции развития. Методы сглаживания можно условно разделить на два класса, опирающиеся на различные подходы: аналитический и алгоритмический. Аналитический подход основан на допущении, что исследователь может задать общий вид функции, описывающей регулярную, неслучайную составляющую. Наиболее простой путь, облегчающий процесс выбора кривой роста – визуальный, опирающийся на графическое изображение временного ряда. Подбирают такую кривую роста, форма которой соответствует фактическому развитию процесса. Если на графике исходного ряда тенденция развития просматривается недостаточно четко, то проводят стандартные преобразования временного ряда, например сглаживание, а потом подбирают функцию, отвечающую графику преобразованного ряда. В алгоритмическом подходе отказываются от ограничительного допущения, свойственного аналитическому. Процедуры этого класса не предполагают описания динамики неслучайной составляющей с помощью единой функции, они предоставляют исследователю лишь алгоритм расчета неслучайной составляющей в любой заданный момент времени t. В любом случае, вне зависимости от группы методов выбранных исследователем, они базируются на одном и том же постулате: сглаживающая кривая должна быть так построена, чтобы, сохраняя основную тенденцию ряда уменьшить диапазон его колебаний, т.е. дисперсию фактического ряда. Сглаживающие модели временных рядов позволяют довольно успешно справляться с обоснованием и конструированием безусловных прогнозов развития разнообразных социально-экономических явлений. При этом ясно, что построение точечного прогноза носит понятный механический характер при удовлетворительных результатах идентификации и оценки модели развития. Для отыскания прогнозного интервала предсказания поведения ряда с заданным уровнем значимости В этом случае среднее значение случайной составит: Таким образом, для получения удовлетворительного интервального прогноза искомой величины на заданную дату либо за предусмотренный промежуток времени необходимо рассчитать дисперсию ошибки прогноза
Здесь xp – прогноз экзогенных переменных модели. Имея в виду возможность проведения для данного динамического ряда оценки дисперсии (s2) случайной составляющей временного ряда, т.е. При этом, как известно, величина среднеквадратической ошибки ряда может быть оценена по формуле:
Соответственно, интервальный прогноз рассчитываем как точечный прогноз плюс минус среднеквадратическая ошибка прогноза, умноженная на t-статистику Стьюдента с заданным уровнем значимости
Множественная регрессия. Экономические явления, как правило, определяют большим числом одновременно и совокупно действующих факторов. В связи с этим часто возникает задача исследования зависимости одной переменной у от нескольких объясняющих переменных х1, х2,..., хn. Эта задача решается с помощью множественного регрессионного анализа. Основная цель множественной регрессии – построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель. Множественная регрессия представляет собой регрессию результативного признака с двумя и большим числом факторов, т.е. модель вида:
Модель (1) - классическая нормальная линейная модель множественной регрессии. Чтобы оценить параметры Величины По теореме Г-М коэффициенты Коэффициенты множественной регрессии проверяются гипотезой об их значимости (t-тест); качество модели оценивается при помощи коэффициента детерминации; значимость уравнения проверяется F-тестом (в том числе частный F-тест на добавление переменных.) Множественная регрессия может быть и нелинейной. 1) нелинейность по переменным: Введем новые переменные: 2) нелинейность по параметрам: Тогда, прологарифмировав обе части уравнения, получаем: Ввиду четкой интерпретации параметров наиболее широко используются линейная и степенная функции. В линейной множественной регрессии В степенной функции Возможны и другие функции для построения уравнения множественной регрессии: · экспонента - · гипербола - Однако, чем сложнее функция, тем менее интерпретируемы ее параметры. Использование индикативных (фиктивных) переменных. Может появиться необходимость включения в модель наряду с количественными факторами, фактор, имеющий 2 или более качественных уровня. Это могут быть разного рода атрибутивные признаки. Например, профессия, пол, образование, климатические условия.… Чтобы ввести такие переменные в регрессионную модель им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные должны быть преобразованы в количественные. 1) если исходным данным присуща неоднородность. Например, пусть у – спрос на автомобили. Рассмотрим исходное уравнение регрессии: Рассмотрим переменную Учтем влияние этой переменной: а) б) 2) если выборка неоднородна. Пусть выборка состоит из двух подвыборок А и В. Рассмотрим переменную При построении регрессионных моделей при воздействии качественных признаков может быть использован критерий Чоу. Он используется когда имеется возможность разделения совокупности наблюдений по степени воздействия качественного фактора на определенные группы и требуется установить возможность использования единой модели регрессии. Построение сценарных прогнозов на базе модели множественной регрессии. Строится множественная регрессия
Оцениваем параметры и строим уравнения регрессии. Проверяем уравнение на значимость, адекватность, на наличие мультиколлинеарности, автокорреляции, гетероскедастичности, на применимость для прогнозирования. Выдвигаем сценарные гипотезы: 1) оптимистическая (что будет с y, если признаки будут развиваться положительно); 2) реалистическая (что будет с y, если признаки будут развиваться так, как развивались); 3) пессимистическая (что будет с y, если признаки будут развиваться отрицательно). Сначала проверяем реалистическую гипотезу. Оцениваем динамику факторов методами экстраполяции (три способа). Получили по три колонки значений для каждого признака, затем находим прогнозные значения y. Когда получили реалистичную оценку, будем отклоняться в сторону пессимизма и оптимизма по факторам. Затем также методами экстраполяции оцениваем пессимистическую и оптимистическую версию и получаем прогнозные значения y. Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 810; Нарушение авторского права страницы
 и соответствующим числом степеней свободы
и соответствующим числом степеней свободы 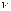 будем использовать тот факт, что величина ошибки прогноза, т.е.
будем использовать тот факт, что величина ошибки прогноза, т.е.  , в любой точке x также имеет нормальный (близкий к нормальному) закон распределения.
, в любой точке x также имеет нормальный (близкий к нормальному) закон распределения. , а дисперсия ряда соответственно
, а дисперсия ряда соответственно  .
.
 , которая будет складываться из модельной дисперсии
, которая будет складываться из модельной дисперсии  и дисперсии случайной
и дисперсии случайной  по ряду, то есть иначе мы можем записать:
по ряду, то есть иначе мы можем записать: 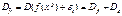 .
. , и оценить модельную дисперсию
, и оценить модельную дисперсию  , значение которой определяется спецификой конкретного модельного представления систематической составляющей ряда, можем получить оценку среднеквадратической ошибки прогноза, которая составит
, значение которой определяется спецификой конкретного модельного представления систематической составляющей ряда, можем получить оценку среднеквадратической ошибки прогноза, которая составит  .
. , где
, где - сглаженное значение ряда;
- сглаженное значение ряда;  - число степеней свободы.
- число степеней свободы. и соответствующим числом степеней свободы, определяемых из числа уровней исследуемого ряда за вычитанием количества параметров сглаживающей модели. Таким образом, окончательно интервальный прогноз временного ряда на L периодов вперед можно оценить следующим образом:
и соответствующим числом степеней свободы, определяемых из числа уровней исследуемого ряда за вычитанием количества параметров сглаживающей модели. Таким образом, окончательно интервальный прогноз временного ряда на L периодов вперед можно оценить следующим образом:  , где
, где - значение точечного прогноза динамики ряда на (n+L)-й момент времени.
- значение точечного прогноза динамики ряда на (n+L)-й момент времени. (1)
(1)  - случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии. Эту случайную величину также называют возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных.
- случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии. Эту случайную величину также называют возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных. по выборке объема n наблюдаемых значений переменных
по выборке объема n наблюдаемых значений переменных 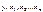 , строим уравнение регрессии
, строим уравнение регрессии  .
.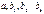 определяются по МНК (аналогично парной регрессии).
определяются по МНК (аналогично парной регрессии).
 являются несмещенными, эффективными, состоятельными оценками параметров
являются несмещенными, эффективными, состоятельными оценками параметров  , если выполняются условия Г-М с (1) по (4). Для построения доверительных интервалов необходимо также условие (5) Г-М.
, если выполняются условия Г-М с (1) по (4). Для построения доверительных интервалов необходимо также условие (5) Г-М.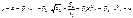
 и получим модель линейной регрессии:
и получим модель линейной регрессии: 


 параметры при
параметры при  называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне. коэффициенты
коэффициенты  являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления. Степенную функцию можно также преобразовать в линейный вид:
являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления. Степенную функцию можно также преобразовать в линейный вид:  , где все переменные выражены в логарифмах.
, где все переменные выражены в логарифмах. ;
;  , которая используется при обратных связях признаков, и другие.
, которая используется при обратных связях признаков, и другие. , где х – доход.
, где х – доход.

 , где
, где 
 , тогда уравнение, учитывающее данную переменную примет вид:
, тогда уравнение, учитывающее данную переменную примет вид:  .
.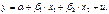 по динамическим рядам:
по динамическим рядам: