
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Показатели формы распределения.
ОТВЕТ К показателям формы распределения относят: 1) Показатель симметричности распределения – коэффициент асимметрии. Симметричным является распределение, в котором частоты любых двух вариантов, равноотстоящих в обе стороны от центра распределения, равны между собой. Для симметричных одновершинных распределений средняя арифметическая, мода и медиана равны между собой. Положительная величина показателя асимметрии указывает на наличие правосторонней асимметрии, отрицательная – на наличие левосторонней асимметрии.
а) б) Рис.4. Виды асимметрии: а) левосторонняя; б) правосторонняя
Существуют различные способы расчета коэффициента асимметрии: 1) As=(Хср-Мо)/s. Величина As может изменяться от –1 до +1 (для одновершинных распределений). Чем ближе по модулю As к 1, тем асимметрия существеннее. 2) Наиболее точным и распространенным является показатель, основанный на определении центрального момента третьего порядка (в симметричном распределении его величина равна нулю):
Для оценки существенности такого коэффициента асимметрии вычисляется показатель средней квадратической ошибки коэффициента асимметрии:
2) Показатель островершинности распределения– Эксцесс. Эксцесс (Ex) представляет собой выпад вершины эмпирического распределения вверх или вниз от вершины кривой нормального распределения. Он рассчитывается для симметричных распределений. Наиболее точным является показатель, использующий центральный момент четвертого порядка (М4):
(для нормального распределения отношение М4/s4=3, следовательно эксцесс равен нулю). Наличие положительного эксцесса означает, что распределение более островершинное чем нормальное; отрицательное значение эксцесса означает более плосковершинный характер распределения, чем у нормального.
Рис. 5. Эксцесс распределения. ВОПРОС 25 Нормальное распределение и его свойства. ОТВЕТ Нормальное распределение может быть представлено графически в виде симметричной куполообразной кривой (рис. 6.). Куполообразная форма кривой показывает, что большинство значений концентрируется вокруг центра измерения. Уравнение нормальной кривой: где Yi- ордината кривой нормального распределения; p=3, 1415 и е=2, 7182 – математические константы, a – математическое ожидание Х (для статистической совокупности a=
Рис. 6. Нормальное распределение.
Основные особенности кривой нормального распределения: 1. Кривая симметрична относительно максимальной ординаты, которая соответствует значению х=Мо=Ме= 2. Кривая асимптотически приближается к оси абсцисс, продолжаясь в обе стороны до бесконечности. Следовательно, чем больше значения отклоняются от Х, тем реже они встречаются. Одинаковые по абсолютному значению, но противоположные по знаку отклонения значений переменной Х от 3. Кривая имеет 2 точки перегиба, находящиеся на расстоянии ±s от 4. При 5. В промежутке 6. Параметры нормального распределения: Мо=Ме= 7. Нормальное распределение с параметрами а=0 и s=1 называется стандартным нормальным распределением.
ВОПРОС 26 Сравнение эмпирического и теоретического распределений вариационных рядов. ОТВЕТ В вариационных рядах существует определенная связь между изменениями частот и значений варьирующего признака. Такого рода изменения называются закономерностями распределения. Для дискретного признака имеет место зависимость частостей (играющих роль вероятностей) от значения признака Х. Для непрерывного признака – зависимость между плотностями распределения частот и значениями признака. Теоретическое распределение – хорошо известное и изученное в теории распределение. Оно описывается конкретной функцией (формулой). Параметры данной функции вычисляются по статистическим характеристикам совокупности. Наиболее широкое практическое использование получили следующие виды распределений: Для дискретного признака: - распределение Пуассона; для непрерывного признака: - нормальное распределение; - экспоненциальное распределение Эмпирические (фактические) закономерности отражают ряды распределения, а графически оно представляется с помощью полигона и гистограммы распределения. Фактическое распределение отличается от теоретического в силу влияния случайных факторов. Их влияние сглаживается с увеличением объема исследуемой совокупности. Если отличия между теоретическими и эмпирическими частотами небольшое, то можно считать, что признак Х распределен по данному теоретическому закону. Объективную оценку близости эмпирических частот к теоретическим можно получить с помощью определенных критериев согласия. Существует множество таких критериев. Наиболее широкое распространение получил критерий согласия «хи-квадрат» (или критерий Пирсона ). Данный критерий применяется для сгруппированных данных. Он представляет собой случайную величину, имеющую распределение близкое к распределению «хи-квадрат», которую определяют по формуле: c2(X)=å j=1; m(Nj- N'j)2/N’j, где m-число групп; Nj – эмпирическая частота в j-ой группе; N'j – теоретическая частота в j-ой группе. Если расхождение между сравниваемыми эмпирическими и теоретическими частотами распределения окажется слишком большим, т.е. c2(X) будет принимать большие численные значения, то считают, что эмпирическое распределение сильно отличается от теоретического. А если расхождение окажется небольшим, то предполагают, что эмпирическое распределение близко к теоретическому. Оценку существенности величины c2(X) можно получить, сравнив вычисленное по наблюдаемым данным значение критерия с табличным (критическим) значением - (c2кр). Если c2(X)< c2кр, то считают, что отличие фактического распределения от теоретического несущественно; а если c2(X)> c2кр, то отличие существенно. c2кр определяют по статистическим таблицам значений c2–критерия Пирсона в зависимости от уровня значимости a (вероятности того, что в наших выводах будет допущена ошибка) и параметра k, который равен: k=m-h-1, где h- число оцененных параметров теоретического распределения по наблюдаемым значениям признака. Если проверяется гипотеза для дискретного ряда распределения, то порядок расчета c2(Х)следующий: 1) строится эмпирический ряд распределения и находятся эмпирические частоты Nj. При этом может оказаться, что для некоторых групп Nj < 5 (обычно в начале или конце ряда). Такие группы следует объединить с соседними, чтобы условие Nj ≥ 5 выполнялось для всех групп. 2) рассчитываются теоретические вероятности pj, для объединенных групп соответствующие вероятности суммируются. Если параметры теоретического распределения неизвестны, то их оценивают по наблюдаемым значениям признака (например, методом максимума правдоподобия). 3) вычисляются ожидаемые частоты: N’j =N· pj, где N – объем совокупности; 4) вычисляется значение критерия «хи-квадрат» по формуле одноименной формуле. Если исследуемая переменная непрерывна, то порядок расчета остается прежним. При этом эмпирический ряд распределения строится как интервальный. Теоретические вероятности pj рассчитываются через интегральную функцию теоретического распределения - F(Х), как: pj= F(Хвj) - F(Хнj), где Хвj и Хнj - соответственно верхняя и нижняя границы j–го интервала. После этого может быть применена описанная выше методика расчета.
ВОПРОС 27 Понятие выборочного статистического исследования и условия его проведения. Генеральная и выборочная совокупность, их показатели. ОТВЕТ Выборочное статистическое исследование – это обследование выборочной совокупности с целью получения достоверных суждений о характеристиках или параметрах генеральной совокупности (qг). Генеральная совокупность – это полная совокупность единиц (статистическая совокупность). Выборочная совокупность (выборка) - это часть единиц генеральной совокупности, отобранная в соответствии с принципами выборочного метода. Принципы выборочного метода: 1) обеспечение случайности отбора единиц совокупности (т.е. равной возможности попадания единицы в выборку); 2) обеспечение достаточного числа единиц в выборке. Условия, требующие проведения выборочного исследования: - экономия времени и средств в результате сокращения объема работы (при выборочном методе обследованию подвергается 5-10%, реже до 15-20% изучаемой совокупности); - сведение к минимуму порчи или уничтожения исследуемых объектов (например, при определении прочности пряжи на разрыв нити, при испытании электрических лампочек на продолжительность горения, при проверке консервов на доброкачественность); - исследуемая совокупность может быть полностью недоступна; - исследуемая совокупность может не иметь конечного объема. Чаще всего с помощью выборочного метода исследуются следующие характеристики совокупности: 1) среднее арифметическое значение признака в совокупности ( 2) доля альтернативного признака (r): где r - доля альтернативного признака в генеральной совокупности; Na – число единиц, обладающих заданным значением альтернативного признака в генеральной совокупности; N – объем генеральной совокупности. Альтернативный признак – это признак, принимающий 2 значения. Если одно из этих значений принять как заданное, то доля альтернативного признака будет характеризовать долю (удельный вес) единиц в статистической совокупности, которые имеют заданное значение альтернативного признака. Например, доля нестандартных изделий во всей партии товара, удельный вес продукции собственного производства в товарообороте предприятия, удельный вес продавцов в общей численности работников магазина и т.п. 3) дисперсия признака в совокупности (s2). Часто с помощью выборочного метода исследуются не просто характеристики генеральной совокупности, а параметры распределения изучаемого признака генеральной совокупности, если удалось установить (из теоретических соображений), какое именно распределение имеет признак. Например, если наперед известно, что изучаемый признак распределен нормально, то исследуемыми параметрами будут: a- математическое ожидание и s - среднее квадратическое отклонение. Если же есть основания считать, что признак имеет распределение Пуассона, то необходимо оценить параметр l- лямбда, которым это распределение определяется. По данным выборки мы не можем найти точное значение характеристики или параметра генеральной совокупности (qг), однако мы можем получить его приближенное значение (оценку). ВОПРОС 28 Понятие статистической оценки. Свойства сатистических оценок: состоятельность, несмещенность, эффективность. ОТВЕТ Статистической оценкой (q*) характеристики (параметра) генеральной совокупности называют приближенное значение искомой характеристики (параметра), полученное по некоторой функции от наблюдаемых в выборке значений признака Х, т.е.: q* =f(X1, X2,..., Xn), где n – объем выборки; (X1, X2,..., Xn) – рассматриваются как независимые случайные величины. Функцию f называют способом оценивания. Примером оценки генеральной средней является выборочная средняя, генеральной дисперсии - выборочная дисперсия. Однако совсем не обязательно в качестве статистической оценки характеристики (параметра) генеральной совокупности использовать выборочный статистический показатель. Возможны и другие способы оценивания. От выборки к выборке статистическая оценка (даже при одном и том же способе оценивания) меняется (q*1, q*2, …, q*m) (рис.7). Получаемая оценка (q*j) представляет частный случай случайной переменной, т.к. сочетание значений признака Х в выборке случайно, а, следовательно, случайным будет и значение функции от них. Таким образом, значение статистической оценки зависит от: 1) вида характеристики (параметра) генеральной совокупности; 2) способа оценивания; 3) конкретной выборки (т.е. сочетания значения признака Х).
1(n1) 2 (n2)..... m (nm) f1: q*11 q*12 q*1m f2: q*21 q*22 q*2m где nj – объем j-ой выборки; q*ij- оценка qг, полученная по данным j–ой выборки при i–ом способе оценивания; m- число выборок; f1, f2 – соответственно 1-ый и 2-ой способы оценивания qг.
Рис.7. Оценивание генеральной характеристики по данным выборки.
Для одного и того же параметра генеральной совокупности может быть предложено несколько способов оценивания. Таким образом, возникает проблема выбора лучшего способа оценивания. Критерием выбора является требование состоятельности, несмещенности и эффективности оценки, получаемой при данном способе оценивания. Способ оценивания дает состоятельные оценки, если при бесконечно большом объеме выборки значение статистической оценки стремится к искомому значению параметра генеральной совокупности. Способ оценивания дает несмещенные оценки, если математическое ожидание оценки при данном способе оценивания тождественно искомому параметру генеральной совокупности (при любом объеме выборки), т.е.Е(q*)=qг. Если математическое ожидание оценки не равняется характеристике генеральной совокупности, то оценка называется смещенной. И разность (Е(q*)-qг) называется смещением. Было бы ошибочным считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Действительно, возможные значения получаемой оценки могут быть сильно рассеяны вокруг своего среднего значения, т.е. дисперсия оценки может быть значительной. Поэтому еще одним важным требованием, предъявляемым к способам оценивания, является эффективностьоценок. Оценка, полученная при данном способе оценивания, называется эффективной , если ее дисперсия минимальна (при заданном объеме выборки n). ВОПРОС 29 Ошибки репрезентативности. Средние и предельные ошибки выборки. ОТВЕТ Выборочные (статистические) оценки отличаются от генеральных параметров за счет ошибки наблюдения (регистрации) и ошибки репрезентативности (выборки): q*=qг+ошибка регистрации+ошибка репрезентативности. Будем считать, что ошибка регистрации равна нулю. Репрезентативность (представительство) выборки означает, что структура выборки должна быть близка к структуре генеральной совокупности, т.е. выборка должна состоять из тех же типов и в той же пропорции, что и генеральная совокупность. Если структура выборки не соответствует структуре генеральной совокупности, то при оценке характеристик (параметров) будут допущены ошибки репрезентативности. Ошибки репрезентативности делятся на: · систематические – отклонения от схемы (способа отбора); · случайные (ошибки выборки) - это отклонения, возникающие из-за недостаточно равномерного представления в выборочной совокупности различных категорий единиц генеральной совокупности, в силу чего распределение отобранной совокупности единиц не вполне точно воспроизводит распределение единиц генеральной совокупности. Величина случайной ошибки репрезентативности равна: e=½ q*-qг½ и может быть оценена с помощью соответствующих математических методов. Различают среднюю и предельную ошибки выборки. Средняя ошибка выборки (m) вычисляется как средняя из возможных ошибок ej, j –номер выборки j=1; m. Она обычно рассчитывается по формуле средней квадратической: В каждой конкретной выборке фактическая ошибка выборки может быть меньше средней ошибки, равна ей или больше ее. Причем каждое из этих расхождений имеет различную вероятность. Предельная ошибка выборки (D) – это максимально возможная при данной вероятности ошибка выборки (рис.8).
e 0 ej m ei D
Рис.8. Предельная ошибка выборки (D).
То есть мы с заданной вероятностью гарантируем, что ошибка нашей (j-ой) выборки не превысит предельную ошибку D. Заданная вероятность называется доверительной вероятностью - g. Предельная ошибка равна: D=t·m, где t- коэффициент доверия, значение которого определяется доверительной вероятностью g. Величина случайной ошибки репрезентативности (ошибки выборки) зависит от: 1) способа формирования выборочной совокупности; 2) объема выборки (чем больше объем выборки, тем меньше ошибка); 3) степени колеблемости изучаемого признака в генеральной совокупности (чем больше колеблемость (вариация) признака, тем ошибка больше).
ВОПРОС 30 Закон больших чисел – методологическая основа выборочного метода. ОТВЕТ Теоретической основой выборочного метода служит закон больших чисел, суть которого состоит в следующем: с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются (чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик). Математически данный закон записывается через неравенство П.Л.Чебышева: Неравенство Чебышева доказывает принципиальную возможность определения генеральной средней по данным простой случайной выборки. Однако, оно не позволяет указать вероятность появления ошибок определенной величины. Это позволяет сделать центральная предельная теорема А.М.Ляпунова (доказанная в 1901 г.), которая гласит: при достаточно большом числе независимых наблюдений вероятность того, что расхождение между выборочной и генеральной средней не превзойдет по модулю некоторую величину – t·m, равна интегралу Лапласа: Данное утверждение справедливо для генеральной совокупности с конечной средней и ограниченной дисперсией.
Из этой теоремы следует важный вывод: при достаточно большом числе независимых наблюдений (объеме выборки) распределение отклонений выборочных средних от генеральной средней, а, следовательно, и самих выборочных средних приближенно нормально. Данное утверждение справедливо и для других видов статистических оценок. То есть можно утверждать, что для выборок большого объема статистические оценки распределены по нормальному закону.
ВОПРОС 31 Способы отбора. ОТВЕТ Основное требование к отбору - отбор должен быть простым по возможности. Различают следующие виды отбора: простой собственно-случайный отбор (без предварительного расчленения генеральной совокупности на какие-либо группы) и отбор с предварительным разбиением совокупности на группы. Простой собственно-случайный отбор – такойотбор единиц из генеральной совокупности, когда на включение или исключение объекта из выборки не может повлиять какой-либо фактор кроме случая. Вероятность включения (исключения) объекта в выборку одинакова. Технически он осуществляется посредством жеребьевки или таблиц случайных чисел. Примером собственно-случайного отбора могут служить тиражи выигрышей: из общего количества выпущенных билетов наугад отбирается определенная часть номеров, на которые приходится выигрыши. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки. Собственно-случайный отбор «в чистом виде» применяется в практике выборочного наблюдения редко, но он является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного наблюдения. Простой отбор может быть организован как повторный или бесповторный. При повторном отборе общая численность единиц генеральной совокупности в процессе выборки остается неизменной. Ту или иную единицу, попавшую в выборку, после регистрации снова возвращают в генеральную совокупность, и она сохраняет равную возможность со всеми прочими единицами при повторном отборе вновь попасть в выборку. Повторная выборка в социально-экономической жизни встречается редко. При бесповторной выборке единица совокупности, попавшая в выборку, затем в генеральную совокупность не возвращается и в дальнейшем в выборке не участвует; т.е. последующую выборку делают из генеральной совокупности уже без отобранных единиц. Таким образом, при бесповторной выборке численность единиц генеральной совокупности сокращается в процессе выборки. Отбор с предварительным делением исходной совокупности на группы может быть организован разными способами, которым соответствуют свои виды отбора: 1) Механический отбор - это бесповторный отбор элементов из генеральной совокупности, упорядоченной по нейтральному (несущественному для цели исследования) признаку через равные интервалы. В этом случае механический отбор дает хорошие результаты и близок к бесповторному собственно-случайному отбору. Например, при исследовании успеваемости студентов вуза в качестве нейтрального признака можно взять фамилию, имя и отчество студента. Всех студентов упорядочивают по этому признаку. После чего отбирают заданное число студентов по фамилиям механически, через определенный интервал. Размер интервала в генеральной совокупности равен обратному значению доли выборки. Так, при 2%-ой выборке отбирается и проверяется каждая 50-я единица (1/0, 02), при 5%-ой выборке – каждая 20-ая единица (1/0, 05). 2) Для отбора единиц из неоднородной совокупности применяется так называемый расслоенный (стратифицированный) отбор. Расслоенный отбор используется тогда, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных групп по существенным для цели исследования признакам. Затем из каждой выделенной группы собственно-случайным или механическим способом производится индивидуальный отбор единиц в выборочную совокупность. Если пропорции между группами в выборке совпадают с пропорциями между группами в генеральной совокупности, то имеем типический отбор. 3) Серийный отбор предполагает случайный отбор из генеральной совокупности не отдельных единиц, а их равновеликих групп (гнезд, серий) с тем, чтобы в таких группах подвергать наблюдению все без исключения единицы совокупности. Применение серийной выборки обусловлено тем, что многие товары для их транспортировки, хранения, продажи упаковываются в пачки, ящики и т.п. Поэтому при контроле качества упакованного товара рациональнее проверить несколько упаковок (серий), чем из всех упаковок отбирать необходимое количество товара. 4) Смешанные (комбинированные) виды отбора. По числу единиц в выборочной совокупности выборки делят на большие (n> 30) и малые (n< 30). ВОПРОС 32 Точечные и интервальные оценки. Доверительный интервал. ОТВЕТ Различают точечное и интервальное оценивание. Точечной называют оценку, которая определяется одним числом. При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, т.е. приводить к грубым ошибкам. Интервальной называют оценку, которая определяется двумя числами – концами интервала. Интервальные оценки позволяют установить точность (границы интервала оценивания) и надежность (вероятность, с которой гарантирован результат оценивания) оценок. Доверительным интервалом называют интервал (q*-D; q*+D), который покрывает неизвестную характеристику (параметр) генеральной совокупности с заданной надежностью (доверительной вероятностью) g. То есть: P[q*-D< qг< q*+D]=g. Обычно надежность оценки задается наперед, причем в качестве g берут число, близкое к единице. Наиболее часто задают надежность, равную 0, 95; 0, 99 и 0, 999. Интервал (q*-D; q*+D) имеет случайные концы (доверительные границы), которые являются случайными величинами функциями от (X1, X2,..., Xn) и будут меняться от выборке. На рис. 9 показаны доверительные интервалы для результатов оценивания по трем различным выборкам, но при одном и том же способе оценивания, одной и той же генеральной совокупности и одной и той же доверительной вероятности g=0, 9545. Здесь доверительный интервал под номером 3 «не покрывает» генеральную характеристику.
Рис.9. Интервальное оценивание генеральной характеристики.
Вероятность того, что доверительный интервал не покроет генеральную характеристику (параметр) совокупности обозначают a и называют уровнем значимости. a =1-g, т.е. при g=0, 95 a=0, 05; при g=0, 99 a=0, 01. Событие, обладающее столь малой вероятностью, считается практически невозможным. Порядок расчета интервальной оценки характеристики (параметра) генеральной совокупности: 1. Определение точечной оценки характеристики (параметра) генеральной совокупности (q*). 2. Расчет средней (среднеквадратической) ошибки выборки - m. Формулы расчета средней ошибки выборки -m зависят от способа отбора и от вида оцениваемой характеристики (параметра) генеральной совокупности. 3. Расчет предельной ошибки выборки: При большом объеме выборки значение коэффициента доверия t находим из таблиц интеграла Лапласа по заданной доверительной вероятности g. Так, для g=0, 95 t=1, 96. При g=0, 99040 t=2, 58. При небольшом объеме выборки (n£ 30) значение t определяют по таблицам интеграла распределения Стьюдента. Распределение Стьюдента (рис.10) имеет один параметр – объем выборки (n), либо число степеней свободы (k=n-1). Данное распределение симметрично относительно оси ординат, похоже на стандартное нормальное распределение, только более пологое. При n®¥ распределение Стьюдента стремится к стандартному нормальному распределению.
Рис. 10. Распределение Стьюдента.
Основные характеристики данного распределения: Е(t)=0; Mo=Me=0; s2=(n-1)/(n-3) > 1; As=0; Ex=6/(n-5). 4. Результатом интервального оценивания является доверительный интервал: (q*-D; q*+D).
ВОПРОС 33 Оценивание среднего арифметического значения и доли по данным собственно- случайного повторного отбора. Оценивание дисперсии. ОТВЕТ В качестве точечной оценки среднего арифметического значения принимают выборочную среднюю: В качестве точечной оценки доли альтернативного признака принимают выборочную долю: В качестве точечной оценки дисперсии принимают исправленную дисперсию (s2): . Если в качестве оценки генеральной дисперсии принять выборочную дисперсию Средняя ошибка выборки при собственно-случайном повторном отборе определяется следующим образом: где n - объем выборочной совокупности. При проведении выборочных обследований она, как правило, неизвестна, поэтому на практике при расчете средней ошибки выборки используется исправленная дисперсия. В случае больших выборок вместо исправленной дисперсии можно использовать выборочную дисперсию. Для доли (частости): s2= Результатом интервального оценивания генеральной средней Результатом интервального оценивания генеральной доли (частости) где
ВОПРОС 34 Оценивание по данным бесповторного случайного отбора, расслоенного, серийного отбора. Расчет необходимого объема выборки. ОТВЕТ Оценивание по данным бесповторного случайного отбора. При бесповторном отборе средняя ошибка выборки определяется следующим образом:
где N - объем генеральной совокупности. При сравнительно небольшом проценте выборки отношение n/N близко к нулю, следовательно, значение средней ошибки выборки при бесповторном отборе близко к значению средней ошибки для повторного отбора. Это имеет место в тех случаях, когда число единиц генеральной совокупности неизвестно или безгранично, или когда n очень мало по сравнению с N. Оценивание по данным расслоенного отбора. При расчете средней ошибки выборки по данным расслоенного отбора в качестве показателя вариации используют среднюю взвешенную из внутригрупповых дисперсий:
где m - число выделенных типологических групп. При оценивании среднего значения: где s2j – дисперсия признака Х внутри j–ой группы; nj –численность j-ой группы. При оценивании доли (частости): где Оценивание по данным серийного отбора. При расчете средней ошибки выборки по данным серийного отбора в качестве показателя вариации берется межгрупповая (межсерийная) дисперсия (d2). Серийный отбор, как правило, является бесповторным. В случае равновеликих серий средняя ошибка выборки будет рассчитываться по формулам:
где r- число отобранных серий; R-общее число серий. При оценивании среднего значения
Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 3866; Нарушение авторского права страницы


 As< 0 As> 0
As< 0 As> 0

 .
. . Отношение ç Asç /sAs, дающее значение большее 3, свидетельствует о существенном характере асимметрии.
. Отношение ç Asç /sAs, дающее значение большее 3, свидетельствует о существенном характере асимметрии.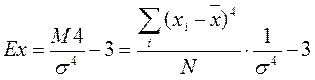 .
.

 Ex> 0
Ex> 0
 Ex=0
Ex=0
 Ex< 0
Ex< 0
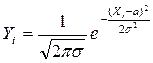 ,
,  ), s- среднее квадратическое отклонение.
), s- среднее квадратическое отклонение. .
. ,
,  Г.С. (N), qг
Г.С. (N), qг




 В.С.
В.С. .
.
 при n®¥, где
при n®¥, где  -выборочная средняя; e- сколь угодно малая величина. Следует отметить, что данное неравенство справедливо для генеральной совокупности с ограниченной дисперсией.
-выборочная средняя; e- сколь угодно малая величина. Следует отметить, что данное неравенство справедливо для генеральной совокупности с ограниченной дисперсией.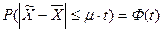 , где Ф(t)=
, где Ф(t)= 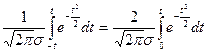 - интеграл Лапласа.
- интеграл Лапласа.
 qг
qг
 , где t–коэффициент доверия.
, где t–коэффициент доверия.
 , которая является состоятельной, несмещенной оценкой генеральной средней.
, которая является состоятельной, несмещенной оценкой генеральной средней. , которая является состоятельной и несмещенной оценкой.
, которая является состоятельной и несмещенной оценкой. , где
, где  - выборочная дисперсия.
- выборочная дисперсия. , то эта оценка будет приводить к систематическим ошибкам, давая заниженное значение генеральной дисперсии, т.е. выборочная дисперсия является смещенной оценкой генеральной дисперсии. Сравнивая формулы выборочной дисперсии и исправленной выборочной дисперсии, можно заметить, что они различаются только знаменателями. Очевидно, что при больших объемах выборки выборочная и исправленная дисперсии различаются мало (n»n-1). На практике пользуются исправленной дисперсией, если n£ 30.
, то эта оценка будет приводить к систематическим ошибкам, давая заниженное значение генеральной дисперсии, т.е. выборочная дисперсия является смещенной оценкой генеральной дисперсии. Сравнивая формулы выборочной дисперсии и исправленной выборочной дисперсии, можно заметить, что они различаются только знаменателями. Очевидно, что при больших объемах выборки выборочная и исправленная дисперсии различаются мало (n»n-1). На практике пользуются исправленной дисперсией, если n£ 30.
 - дисперсия признака в генеральной совокупности;
- дисперсия признака в генеральной совокупности;  , где
, где  - доля альтернативного признака в выборке.
- доля альтернативного признака в выборке.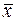 является доверительный интервал:
является доверительный интервал:  .
. :
:  ,
, 
 - для повторного отбора,
- для повторного отбора,  - для бесповторный отбора,
- для бесповторный отбора,  –средняя взвешенная из внутригрупповых дисперсий по выборочной совокупности;
–средняя взвешенная из внутригрупповых дисперсий по выборочной совокупности;  ,
, 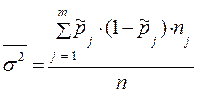 ,
, 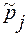 - выборочная доля альтернативного признака, рассчитанная по j–ой группе.
- выборочная доля альтернативного признака, рассчитанная по j–ой группе.
 ,
,