
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Гипотезы о виде законов распределения генеральной совокупности
Проверка гипотез о виде законов распределения генеральной совокупности осуществляется с помощью критериев согласия. Критерием согласия называется статистический критерий, предназначенный для проверки гипотезы Н0 о том, что ряд наблюдений х1, х2, …хn образует случайную выборку, извлеченную из генеральной совокупности Х с функцией распределения F(x)=F(x; θ 1; θ 2; … θ k), где общий вид функции F(x) считается заданным, а параметры θ 1; θ 2; … θ k, от которых она зависит могут быть, как известными, так и неизвестными. Критерии согласия основаны на использовании различных мер расстояний между анализируемой эмпирической функцией распределения Fn(x), определяемой по выборке, и функцией распределения F (x) генеральной совокупности Х. Математически, нулевую гипотезу можно записать в следующем виде: Н0: рl – вероятность попадания случайной величины в i-тый интервала или вероятность того, что дискретная величина примет i-тое значение (Х=хi). Критерий Пирсона (критерий - Процедура проверки статистической гипотезы о виде распределения с помощью критерия согласия Пирсона состоит из следующих этапов. 1. Весь диапазон значений исследуемой случайной величины разбивается на ряд интервалов группирования Δ 1, Δ 2, …, Δ l, необязательно одинаковой длины. 2. Подсчитывается число точек, попавших в каждый из интервалов группирования Δ i. 3. На основе сгруппированных данных вычисляются оценки 4. Вычисляется вероятность рi попадания случайной величины Х в каждый из интервалов группирования Δ i. 5. Вычисляется наблюдаемое значение статистики критерия
Если В случае нормального закона распределения вероятность попадания случайной величины Х в соответствующие интервалы вычисляется по интегральной теореме Лапласа: рi = Р(аi< x< bi) = где t1i =
Контрольные вопросы и задачи 3.1. По результатам 15 испытаний установлено, что среднее время изготовления детали 3.2. На основании 20 измерений, было установлено что средняя длина трубы равна 3.3. По данным задачи 3.2 проверить на уровне значимости 3.4. По двум независимым выборкам объемом 3.5. Для сравнения точности изготовления деталей двумя станками-автоматами взяты две выборки объемом n1=12 и n2=8. По результатам измерений контролируемого размера деталей вычислены средние 3.6. По четырем независимым выборкам объемом n1 =12, n2=8, n3=13, n4=11, извлеченным из нормальных генеральных совокупностей, найдены выборочные исправленные дисперсии 3.7. Для сравнения точности работы четырех станков из продукции каждого станка взято по одной выборке из 25 деталей. По результатам измерений найдены несмещенные оценки дисперсий 3.8. Для сравнения качества работы четырех сборочных конвейеров из общего дневного объема продукции каждого конвейера отобрано соответственно n1 =20, n2=26, n3=18, n4=24 изделий, из которых оказались дефектными m1=2, m2=4, m3=1, m4=2. На уровне значимости
Тема 4. Методика статистического анализа количественных и Корреляционный анализ является методом исследования взаимозависимости признаков в генеральной совокупности. Основная задача корреляционного анализа состоит в оценке корреляционной матрицы генеральной совокупности по выборке и определении на ее основе оценок коэффициентов корреляции. В рамках реализации статистических процедур корреляционного анализа необходимо: выбрать (с учетом специфики и природы анализируемых переменных) подходящий измеритель статистической связи (коэффициент корреляции, корреляционное отношение, ранговый); оценить с помощью точечной и интервальной оценок его числовое значение по выборочным данным; проверить гипотезу о том, что полученное числовое значение анализируемого измерителя связи действительно свидетельствует о наличии статистической связи. Парная корреляция занимается изучением характеристик взаимосвязи двух случайных величин. Корреляционная зависимость двух случайных величин задается моделью X=X(Y, Z) и Y= Y(Х, Z), где Z –набор внешних случайных факторов. Основой получения этих характеристик служит совместное распределение случайных величин F(x, y) = P Плотность двумерного нормального закона распределения определяется пятью параметрами: Парный коэффициент корреляции характеризует тесноту линейной связи между двумя переменными. Выборочное значение
Коэффициент корреляции не имеет размерности и изменяется в диапазоне В рамках корреляционного анализа можно построить линии условных математических ожиданий (линий регрессии у по х и х по у) у(х)=М(Y/X=x), x(y)=М(X/Y=y) ; (4.2) а также линии условных дисперсий, которые характеризует, насколько точно линии регрессии передают изменение одной случайной величины при изменении другой,
Точные (или приближенные) прямолинейные регрессии y(x) = задаются следующими коэффициентами:
Если случайные величины Х и Y независимы, ρ =0, то все условные математические ожидания и дисперсии не зависят от фиксированного значения другой случайной величины и совпадают с безусловными. Стоит отметить, что выборочные коэффициенты корреляции могут быть формально вычислены для любой двумерной системы наблюдений. Для проверки значимости парного коэффициента корреляции выдвигается гипотеза Н0: ρ =0. При проверки нулевой гипотезы используется статистика:
имеющая распределение Стьдента с ν =n-2 числом степеней свободы. Если На практике для проверки нулевой гипотезы пользуются также распределением Фишера-Йетса. На уровне значимости α по таблице распределения Фишера-Йетса находят Для значимых параметров связи можно построить интервальную оценку. При определении границ доверительного интервала коэффициента корреляции ρ используется преобразование Фишера: Предварительно устанавливают интервальную оценку для Р( где Получив доверительный интервал для При выборе Трехмерная корреляционная модель является частным случаем множественной корреляционной модели. На примере анализа трехмерной корреляционной модели удобно показать все свойства множественной корреляции. Трехмерная нормально распределенная генеральная совокупность, образуемая тремя признаками X, Y, Z, определяется девятью параметрами: тремя математическими ожиданиями, тремя дисперсиями и тремя парными коэффициентами корреляции:
При изучении корреляционной зависимости между более чем двумя случайными величинами с заданным совместным многомерным распределением используют множественные и частные коэффициенты корреляции. Частный коэффициент корреляции – это мера линейной зависимости между двумя случайными величинами из некоторой совокупности Х1, Х2, …, Хn, когда исключено влияние остальных случайных величин. Частный коэффициент корреляции обладает всеми свойствами парного коэффициента корреляции. В общем случае частный коэффициент корреляции выражается через элементы корреляционной матрицы R = В рамках простой трехмерной корреляционной модели могут быть рассчитаны три частных коэффициента корреляции:
Для проверки значимости частного коэффициента корреляции выдвигается гипотеза Н0:
имеющая распределение Стьюдента с ν =n-3 числом степеней свободы. Если Как и в случае парной корреляции на практике для проверки нулевой гипотезы чаще пользуются распределением Фишера-Йейтса. На уровне значимости α по таблице распределения Фишера-Йейтса находят При определении границ доверительного интервала коэффициента корреляции ρ используется преобразование Фишера: Предварительно устанавливают интервальную оценку для Р( где Получив доверительный интервал для Множественный коэффициент корреляции R служит мерой линейной зависимости между случайной величиной Х1 и набором случайных величин Х2, …, Хn. В общем случае множественные коэффициенты корреляции выражаются через элементы корреляционной матрицы. Для трехмерной модели может быть рассчитано три множественных коэффициента корреляции:
Множественный коэффициент корреляции изменяется в диапазоне 0 Множественный коэффициент детерминации При проверке значимости множественного коэффициента корреляции (множественного коэффициента детерминации) выдвигается гипотеза Н0:
имеющая распределение Фишера-Снедекора с числом степеней свободы Если Корреляционное отношение.Как уже отмечалось выше коэффициент корреляции является адекватной мерой статистической взаимозависимости только в случае линейного характера связи между признаками. Для изучения связи между признаками, выражаемой нелинейной функцией, применяется более общий показатель тесноты связи – корреляционное отношение. В теории статистики разработан специальный критерий оценки нелинейности связи между двумя переменными:
где
Если Использование корреляционного отношения основано на разложении общей дисперсии зависимой переменной на составляющие: дисперсию, характеризующую влияние объясняющей переменной, и дисперсию, характеризующую влияние неучтенных факторов: где
Корреляционное отношение определяется по формуле:
Корреляционное отношение не имеет размерности и изменяется в диапазоне 0 Для проверки значимости корреляционного отношения выдвигается гипотеза Н0:
которая имеет распределение Стьюдента с числом степеней свободы ν =n-2. Если Доверительный интервал имеет вид: где Ранговая корреляция. Для изучения взаимосвязи признаков, не поддающихся количественному измерению, используются различные показатели ранговой корреляции. Под ранговой корреляцией понимается статистическая связь между порядковыми переменными. В статистической практике эта связь анализируется на основании исходных статистических данных, представленных упорядочениями (ранжировками) n рассматриваемых объектов. Методы ранговой корреляции широко используются, в частности, при организации и статистической обработке различного рода систем экспертных обследований. Для измерения тесноты связи между порядковыми переменными используются различные показатели, такие как коэффициент Спирмена, коэффициент Кэнделла, коэффициенты конкордации, ассоциации, контингенции. Рассмотрим пример расчета рангового коэффициента корреляции Спирмена.
где Если два ряда полностью совпадают, то Для проверки значимости рангового коэффициента корреляции Спирмена выдвигается гипотеза Н0: где Регрессионный анализ – статистический метод исследования зависимости случайной величины Y от переменных Х1, Х2, …, Хm , рассматриваемых как неслучайные величины, независимо от истинного закона распределения Хi . Регрессия – функция f(Х1, Х2, …, Хm), описывающая зависимость условного математического ожидания зависимой переменной Y (вычисленного при условии, что независимые переменные зафиксированы на уровнях Х1, Х2, …, Хm) от заданных фиксированных значений независимых переменных. В рамках регрессионного анализа решаются следующие задачи: выбор математической модели, описывающей изучаемый процесс; отбор наиболее информативных объясняющих переменных (регрессоров); вычисление оценок для неизвестных значений параметров, участвующих в записи уравнения искомой зависимости; анализ точности полученного уравнения связи. Выбор конкретной формы уравнения регрессии зависит от экономической сущности изучаемого явления или процесса. На практике чаще всего встречаются следующие виды уравнений регрессии: 1) 2) 3) 4) 5) Так как аппарат исследования линейных функций разработан наиболее полно, на практике чаще всего прибегают к линейному преобразованию (линеаризации) степенных, полиномиальных, гиперболических, а также любых других нелинейных функций, поддающихся такому преобразованию. Например, степенное регрессионное уравнение может быть приведено к линейной форме путем логарифмирования:
и далее
где Общая модель линейной относительно оцениваемых параметров регрессии может быть представлена следующим образом:
где
Для оценки неизвестных параметров модели используются уже описанные выше статистические методы оценивания: метод максимального правдоподобия (ММП), метод наименьших квадратов (ММП) и метод моментов. В теории регрессионного анализа доказывается, что ММП– и МНК–оценки являются наилучшими линейными оценками неизвестных параметров уравнения регрессии, обладающими свойствами несмещенности и эффективности. Ввиду относительной простоты реализации в практических приложениях чаще всего используется метод наименьших квадратов. Для получения несмещенных и эффективных МНК-оценок неизвестных параметров необходимо выполнение некоторых предпосылок, касающихся как всего уравнения в целом, так и его отдельных составляющих. Основные предпосылки формулируются следующим образом: 1. Объем наблюдений n больше числа оцениваемых параметров m. 2. Между объясняющими переменными не должно существовать строгой линейной зависимости, т.е. предполагается отсутствие мультиколлинеарности. 3. Зависимая переменная Y и объясняющие параметры Хi распределены нормально. 4. Регрессоры являются неслучайными величинами. 5. При построении функции регрессии предполагается, что результативный признак Y зависит только от объясняющих переменных Хi, которые включены в регрессию. Таким образом, предполагается, что на переменную Y не оказывают влияния никакие другие систематически действующие факторы. Суммарный эффект от воздействия на зависимую переменную неучтенных факторов учитывается возмущающей переменной ε. При этом предполагается, что математическое ожидание возмущающей переменной ε равно 6. Объясняющие переменные не коррелируют с возмущающей переменной ε, т.е. 7. Распределение возмущающей переменной подчиняется нормальному закону распределения. 8. Возмущаюшая переменная ε имеет постоянную дисперсию 9. Значения возмущающей переменной ε попарно некоррелированы, т.е. Для нахождения оценок неизвестных параметров
где
Разность Дифференцируя функционал S по
После соответствующих преобразований имеем:
Решив данную систему относительно
Свободный член уравнения регрессии Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 1790; Нарушение авторского права страницы
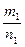 =р1,
=р1,  = р2,
= р2, 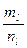 = рl,
= рl, 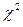 ) имеет наибольшее применение при проверке согласования теоретической и эмпирической функций распределения.
) имеет наибольшее применение при проверке согласования теоретической и эмпирической функций распределения.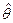 k неизвестных параметров распределения θ k.
k неизвестных параметров распределения θ k.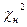 =
= 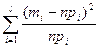 , (3.32)
, (3.32)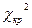 , найденным для уровня значимости α и числа степеней свободы ν = l-k-1, где l -число интервалов, k – число параметров, которыми определяется функция распределения.
, найденным для уровня значимости α и числа степеней свободы ν = l-k-1, где l -число интервалов, k – число параметров, которыми определяется функция распределения.
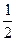
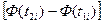 , (3.33)
, (3.33)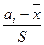 , t2i =
, t2i = 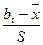 ; аi, bi – нижняя и верхняя граница соответствующего интервала i.
; аi, bi – нижняя и верхняя граница соответствующего интервала i.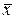 = 28с. В предположении, что время изготовления детали является нормальной случайной величиной с известным генеральным средним квадратическим отклонением
= 28с. В предположении, что время изготовления детали является нормальной случайной величиной с известным генеральным средним квадратическим отклонением 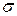 =1, 2с, на уровне значимости
=1, 2с, на уровне значимости 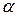 =0, 05 проверить гипотезу Н0: μ = 30 с против конкурирующей гипотезы Н1: μ = 25с.
=0, 05 проверить гипотезу Н0: μ = 30 с против конкурирующей гипотезы Н1: μ = 25с.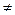 15м.
15м.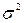 =0, 06 м2 при конкурирующей гипотезе Н1:
=0, 06 м2 при конкурирующей гипотезе Н1:  n1=30 и n2=15, извлеченным из нормальных генеральных совокупностей, найдены выборочные средние
n1=30 и n2=15, извлеченным из нормальных генеральных совокупностей, найдены выборочные средние 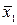 =25 и
=25 и 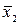 =27. Дисперсии генеральных совокупностей известны
=27. Дисперсии генеральных совокупностей известны 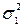 =1, 3 и
=1, 3 и 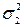 =1, 6. На уровне значимости
=1, 6. На уровне значимости 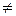 μ 2.
μ 2.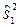 =1, 05мм2 и
=1, 05мм2 и 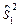 =2, 1,
=2, 1, 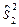 =1, 9,
=1, 9, 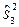 =2, 2,
=2, 2, 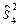 =2, 3. Проверить на уровне значимости
=2, 3. Проверить на уровне значимости 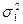 =
= 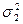 =….=
=….= 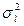 .
.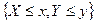 .
.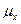 - математическое ожидание Х;
- математическое ожидание Х; 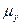 - математическое ожидание Y;
- математическое ожидание Y; 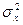 - дисперсия Х;
- дисперсия Х; 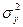 - дисперсия Y;
- дисперсия Y; 
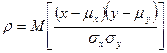 - парный коэффициент корреляции между Х и Y.
- парный коэффициент корреляции между Х и Y.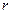 парного коэффициента корреляции ρ подсчитывается по исходным статистическим данным по формуле:
парного коэффициента корреляции ρ подсчитывается по исходным статистическим данным по формуле: 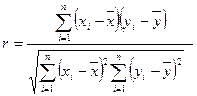 . (4.1)
. (4.1)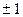 говорит о функциональном характере связи между Х и Y.
говорит о функциональном характере связи между Х и Y.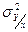 = М
= М 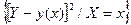 , (4.3)
, (4.3)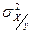 = М
= М 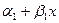 ,
, 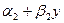 (4.4)
(4.4)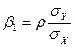 ;
; 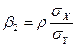 , (4.5)
, (4.5)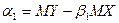 ,
, 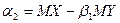 .
.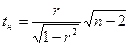 , (4.6)
, (4.6)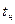 <
< 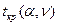 , нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если
, нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. Если 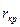 (α, ν =n-2). Если
(α, ν =n-2). Если 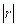
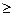
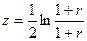 . (4.7)
. (4.7) из условия:
из условия: 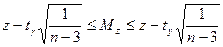 ) =
) = 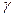 =Ф(
=Ф( 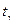 ), (4.8)
), (4.8)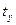 находят по таблице интегральной функции Лапласа для данного уровня
находят по таблице интегральной функции Лапласа для данного уровня 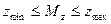 , при помощи таблицы z- преобразования Фишера делают обратный переход от
, при помощи таблицы z- преобразования Фишера делают обратный переход от 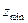 и
и 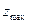 к
к 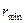 и
и 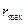 . Таким образом окончательно получаем:
. Таким образом окончательно получаем: 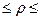
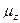 - математические ожидания Х, Y и Z соответственно;
- математические ожидания Х, Y и Z соответственно; 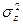 - дисперсии Х, Y и Z соответственно;
- дисперсии Х, Y и Z соответственно; 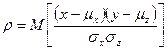 - парный коэффициент корреляции между Х и Z,
- парный коэффициент корреляции между Х и Z, 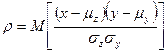 - парный коэффициент корреляции между Z и Y.
- парный коэффициент корреляции между Z и Y. , составленной из коэффициентов парной корреляции.
, составленной из коэффициентов парной корреляции.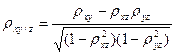 ;
; 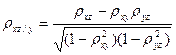 ;
; 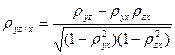 . (34.9)
. (34.9)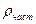 =0. При проверки нулевой гипотезы используется статистика:
=0. При проверки нулевой гипотезы используется статистика: 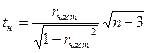 , ((34.10)
, ((34.10)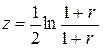 (34.11)
(34.11)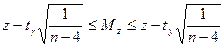 ) =
) = 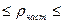
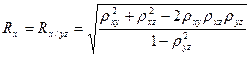 ;
; 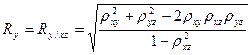 ; (34.13)
; (34.13)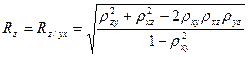 .
.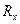 = 1, то связь между случайной величиной Х и двумерной случайной величиной (Х, Z) является функциональной; если
= 1, то связь между случайной величиной Х и двумерной случайной величиной (Х, Z) является функциональной; если 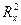 показывает долю дисперсии случайной величины Х1, обусловленную влиянием остальных факторов Х2, …, Хn, входящих в многомерную модель. Множественный коэффициент детерминации может увеличиваться при введении в модель дополнительных признаков и не увеличиваться при исключении некоторых признаков из модели. Для двухмерной корреляционной модели коэффициент детерминации равен квадрату парного коэффициента корреляции.
показывает долю дисперсии случайной величины Х1, обусловленную влиянием остальных факторов Х2, …, Хn, входящих в многомерную модель. Множественный коэффициент детерминации может увеличиваться при введении в модель дополнительных признаков и не увеличиваться при исключении некоторых признаков из модели. Для двухмерной корреляционной модели коэффициент детерминации равен квадрату парного коэффициента корреляции.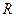 =0 (или
=0 (или 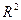 =0 ). При проверке нулевой гипотезы используется статистика:
=0 ). При проверке нулевой гипотезы используется статистика: 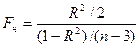 , (34.14)
, (34.14)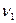 =2 и
=2 и 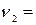 n-2.
n-2.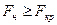 (α,
(α, 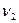 ), нулевая гипотеза отвергается, следовательно, множественный коэффициент корреляции (множественный коэффициент детерминации) считается значимым.
), нулевая гипотеза отвергается, следовательно, множественный коэффициент корреляции (множественный коэффициент детерминации) считается значимым.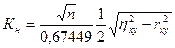 , (34.15)
, (34.15)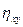 - корреляционное отношение между X и Y,
- корреляционное отношение между X и Y, 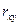 - коэффициент корреляции между X и Y.
- коэффициент корреляции между X и Y.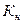 > 2, 5, то корреляционную связь можно считать нелинейной.
> 2, 5, то корреляционную связь можно считать нелинейной. , (34.16)
, (34.16)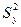 - общая дисперсия зависимой переменной,
- общая дисперсия зависимой переменной, 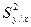 - дисперсия функции регрессии относительно среднего значения зависимой переменной, характеризующая влияние объясняющей переменной.
- дисперсия функции регрессии относительно среднего значения зависимой переменной, характеризующая влияние объясняющей переменной.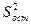 - остаточная дисперсия.
- остаточная дисперсия.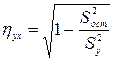 =
= 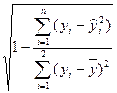 (34.17)
(34.17)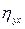
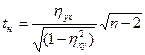 , (43.18)
, (43.18)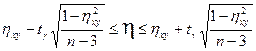 , (34.19)
, (34.19)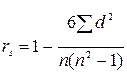 , (34.20)
, (34.20)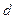 - разность значений рангов, расположенных в двух рядах у одного и того же объекта.
- разность значений рангов, расположенных в двух рядах у одного и того же объекта.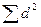 =0, и следовательно,
=0, и следовательно, 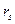 =1. При полной обратной связи ранги двух рядов расположены в обратном порядке и
=1. При полной обратной связи ранги двух рядов расположены в обратном порядке и 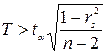 , (43.21)
, (43.21)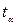 определяется по таблице распределения Стьюдента для уровня значимости α и числа степеней свободы ν =n-2. Если
определяется по таблице распределения Стьюдента для уровня значимости α и числа степеней свободы ν =n-2. Если 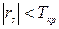 нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. В противном случае ранговый коэффициент корреляции считается значимым.
нулевая гипотеза не отвергается, следовательно, случайные величины Х и Y независимы. В противном случае ранговый коэффициент корреляции считается значимым.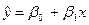 - двумерное линейное;
- двумерное линейное; 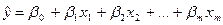 - многомерной линейное;
- многомерной линейное; 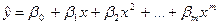 - полиномиальное;
- полиномиальное; 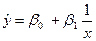 - гиперболическое;
- гиперболическое; 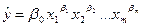 - степенное.
- степенное.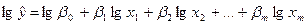 ,
, 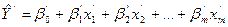 ,
, 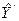 = lg
= lg 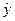 ,
, 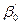 = lg
= lg 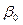 ,
, 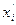 =
= 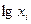 .
.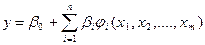 +ε,
+ε, 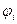 - некоторая функция переменных
- некоторая функция переменных 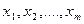 ,
, 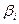 - неизвестные параметры уравнения регрессии, которые необходимо оценить по выборочным данным,
- неизвестные параметры уравнения регрессии, которые необходимо оценить по выборочным данным, 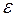 - случайное слагаемое или ошибка модели (возмущение), с нулевым математическим ожиданием
- случайное слагаемое или ошибка модели (возмущение), с нулевым математическим ожиданием 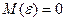 и дисперсией
и дисперсией 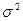 .
. =0. Отсюда следует, что переменные Хi объясняют переменную Y, а переменная Y не объясняет переменные Хi.
=0. Отсюда следует, что переменные Хi объясняют переменную Y, а переменная Y не объясняет переменные Хi.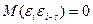 для s≠ 0. Иначе это свойство называется отсутствием автокорреляции возмущающей переменной ε.
для s≠ 0. Иначе это свойство называется отсутствием автокорреляции возмущающей переменной ε.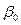 и
и 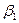 двумерного линейного уравнения регрессии
двумерного линейного уравнения регрессии 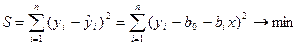 , (4.22)
, (4.22)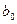 и
и 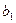 - оценки неизвестных параметров
- оценки неизвестных параметров 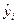 - расчетные значения зависимой переменной
- расчетные значения зависимой переменной 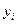 .
.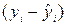 называется остатком и дает количественную оценку воздействия возмущающей переменной ε.
называется остатком и дает количественную оценку воздействия возмущающей переменной ε. (4.23)
(4.23)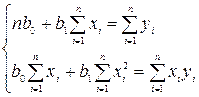 (4.24)
(4.24)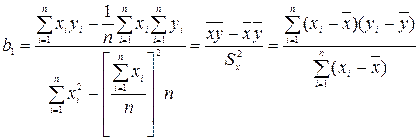 ; (4.25)
; (4.25)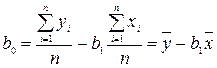 . (4.26)
. (4.26)