|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Расширяемый язык разметки XML. Синтаксис. Понятия правильно оформленного и действительного документов.
XML, или eXtensible Markup Language - язык разметки, который позволяет вам создавать свои собственные теги. Он разработан консорциумом World Wide Web Consortium для того, чтобы обойти ограничения HTML - языка разметки, лежащего в основе всех WEB страниц. Подобно HTML, XML основывается на SGML - Standard Generalized Markup Language Спецификация XML требует, чтобы программа-анализатор XML отклонял любой XML документ, не соответствующий этим основным правилам. Существуют два уровня правильности XML документов. XML документ может быть: • Правильно построенный (Well-formed). Документ следует правилам, определенным в спецификации XML, но не имеет ассоциированного с ним определения типа документа. • Действительным (Valid). Документ следует правилам, определенным в спецификации XML, а так же с документом ассоциировано Определение типа документа и документ соответствует этому определению. Взаимоотношение понятий действительности и правильности построения, в каком порядке XML анализатор выполняет проверку XML кода. 1. XML документ загружается и выполняется проверка на соответствие спецификациям XML. Если проверка не прошла, документ признается недействительным и неправильно построенным. Если проверка прошла успешно, документ признается правильно построенным и анализатор приступает к проверке на действительность. 2. Выполняется проверка на соответствие DTD. Если проверка не прошла документ признается недействительным (но правильно построенным! ). Если проверка прошла успешно, документ признается действительным (а значит и правильно построенным). Таким образом, понятие действительность включает в себя понятие правильного построения. Действительность является более строгим понятием. Корневой элемент Весь XML документ должен содержаться в одном элементе. Этот элемент называется корневым и содержит в себе весь текст и все другие элементы документа. В следующем примере (Пример 3.4, «Well-formed документ») весь XML документ содержится внутри элемента greeting. Обратите внимание, что документ имеет комментарий, который находится вне корневого элемента и это вполне допустимо. <? xml version=" 1.0"? > <! -- A well-formed document --> < greeting> Hello, World! < /greeting> Пример 3.4. Well-formed документ А в следующем примере (Пример 3.5, «Не Well-formed документ») документ не имеет единственного корневого элемента
<? xml version=" 1.0"? > <! -- A well-formed document --> < greeting> Hello, World! < /greeting> < greeting> Hola, el Mundo! < /greeting> Пример 3.5. Не Well-formed документ Анализатор XML отклонит такой документ, независимо от содержащейся в нем информации. Элементы не могут пересекаться Элементы не могут пересекаться. В примере 3.6 показан неправильный XML документ. <! -- NOT legal XML markup --> < p> < b> I < i> really love< /b> & xml;.< /i> < /p> Пример 3.6. Пересекающиеся элементы Если вы начали элемент i внутри элемента b, то и закончить его вы должны здесь-же. В примере 3.7 показана исправленная версия этого документа. <! -- Legal XML markup --> < p> < b> I < i> really love< /i> < /b> < i> XML.< /i> < /p> Пример 3.7. Исправление пересекающихся элементов Анализатор XML примет только второй вариант. Анализатор HTML в большинстве браузеров примет оба. Закрывающие теги обязательны Вы не можете оставлять элементы незакрытыми! В примере 3.8 разметка неверна, т.к. у элементов p нет закрывающих тегов (< /p> ). Это допустимо в HTML и иногда в SGML, но анализатор XML отклонит такой документ. <! -- NOT legal XML markup --> < p> Yada yada yada... < p> Yada yada yada... < p>... Пример 3.8. Элемент не закрыт Если элемент не содержит никакой разметки внутри, он называется пустым. В html примерами таких элементов могут быть элементы br и img. В XML, чтобы указать пустой элемент, вы должны поместить слэш (/) в конце открывающего тега. В примере 3.9) два элемента br и два элемента img значат для XML анализатора одно и то же. <! -- Два эквивалентных элемента br --> < br> < /br> < br /> <! -- Два эквивалентных элемента img --> < img src="../img/c.gif" > < /img> < img src="../img/c.gif" /> Пример 3.9. Пустые элементы Имена элементов чувствительны к регистру Имена элементов чувствительны к регистру. В HTML теги h1 и H1 значат одно и то же. Но в XML это не так! Если вы попытаетесь закрыть элемент h1 тегом < /H1>, то получите ошибку. В ( примере 3.10) верхний заголовок неправильный, а нижний правильный. <! -- NOT legal XML markup --> < h1> Elements are case sensitive< /H1> <! -- legal XML markup --> < h1> Elements are case sensitive< /h1> Пример 3.10. XML чувствителен к регистру Атрибуты должны быть заключены в кавычки В XML есть два правила для атрибутов • Атрибуты должны иметь значения • Эти значения должны быть заключены в кавычки Сравните два примера ниже (Пример 3.11, «Атрибуты»). Верхний правилен в HTML, но неправилен в XML. Нижний правилен и в HTML и в XML. <! -- NOT legal XML markup --> < ol compact> <! -- legal XML markup --> < ol compact=" yes" > Пример 3.11. Атрибуты
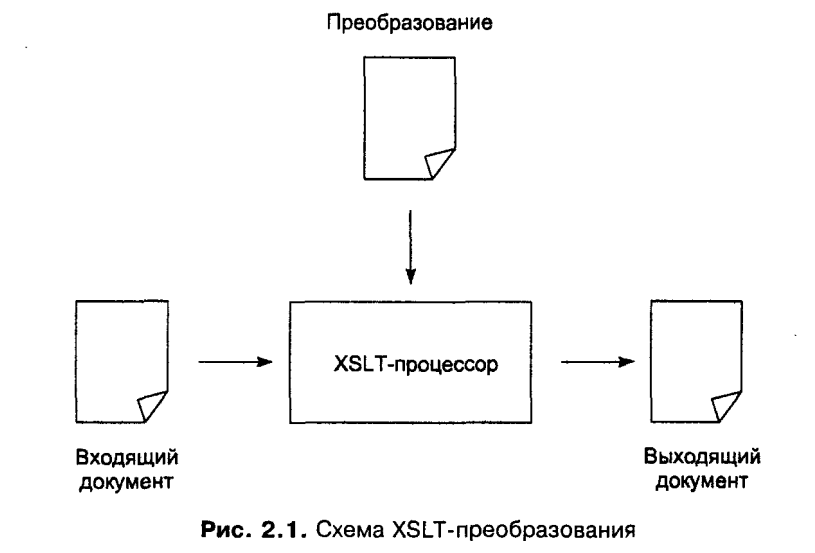
2. Язык преобразования XML документов - XSLT. Назначение, общая структура и основные понятия. Основные управляющие операторы. XSLT (Extensible Stylesheet Language Transformations) — часть спецификации XSL, задающая язык преобразований XML-документов. Спецификация XSLT является рекомендацией W3C. XSLT имеет множество различных применений, в основном в области web-программирования и генерации отчётов. Одной из задач, решаемых языком XSLT, является отделение данных от их представления, как часть общей парадигмы MVC (англ. Model-view-controller). Другой стандартной задачей является преобразование XML-документов из одной XML-схемы в другую. Консорциум W3 определяет три составные части языка XSL (англ. eXtensible Stylesheet Language — Расширяемый Язык Стилей): XSLT, XPath (язык путей и выражений, используемый в XSLT для доступа к отдельным частям XML-документа) и XSL-FO (англ. eXtensible Markup Language Formatting Objects — язык разметки типографских макетов и иных предпечатных материалов. Пример
Основные управляющие операторы – непонятно что это в своей сути. Преобразование, выраженное через XSLT, описывает правила преобразования исходного дерева документа в конечное дерево. Преобразование строится путем сопоставления образцов и шаблонов. Образец сравнивается с элементами исходного дерева, а шаблон используется для создания частей конечного дерева. Конечное дерево отделено от исходного дерева. Структура конечного дерева может полностью отличаться от структуры исходного дерева. В ходе построения конечного дерева элементы исходного дерева могут подвергаться фильтрации и переупорядочению, также может добавлена новая структура. Преобразование, выраженное через XSLT, называется стилем (stylesheet). Так сделано потому, что в случае, когда XSLT приводится к словарю форматирования XSL, данное преобразование выполняет функции стиля. Стиль содержит набор правил шаблона. Правило шаблона состоит из двух частей: это образец, который сопоставляется с узлами в исходном дереве, и шаблон, который может быть обработан для формирования фрагмента в конечном дереве. Такая схема позволяет использовать один стиль для большого класса документов, имеющих одинаковую структуру исходного дерева. Чтобы получить фрагмент в конечном дереве, шаблон обрабатывается для определенного элемента в исходном документе. Шаблон может содержать элементы, определяющие фиксированную структуру конечного элемента. Шаблон может также содержать элементы из пространства имен XSLT, дающие инструкции по созданию фрагментов конечного дерева. При обработке шаблона каждая инструкция обрабатывается и заменяется на полученный фрагмент конечного дерева. Инструкции могут находить в исходном дереве и обрабатывать элементы-потомки. При обработке элемента-потомка в конечном дереве создается фрагмент путем нахождения соответствующего правила шаблона и обработки его шаблона. Заметим, что элементы обрабатываются только если они были выбраны в ходе выполнения инструкции. Конечное дерево строится после нахождения правила шаблона для корневого узла и обработки в нем шаблона. В ходе поиска соответствующего правила шаблона может выясниться, что данному элементу соответствует не одно, а сразу несколько правил. Однако использоваться будет только одно правило шаблона. Шаблон даже сам по себе наделен значительной мощностью: он может создавать структуры произвольной сложности, извлекать строковые значения из любых мест исходного дерева, создавать структуры, повторяющие появление элементов в исходном дереве. Для простых преобразований, когда структура конечного дерева не связана со структурой исходного дерева, стиль часто образуется одним шаблоном, который используется как шаблон для всего конечного дерева. Если обрабатывается шаблон, то это всегда делается отталкиваясь от текущего узла и текущего набора узлов. Текущий узел всегда является членом текущего набора узлов. В XSLT многие операции привязаны к текущему узлу. И лишь несколько инструкций меняют текущий набор узлов или текущий узел (см. [5 Правила шаблона] и [8 Повторение]). При обработке любой из этих инструкций текущий набор узлов заменяется новым набором узлов, а каждый член этого нового набора по очереди становится текущим узлом. После того как обработка инструкции завершена, текущий узел и текущий набор узлов становится такими, каким они были до обработки этой инструкции. Для выбора элементов для обработки, обработки при условии и генерации текста XSLT использует язык выражений, сформулированный в [XPath]. Традиционные императивные языки программирования очень плохо подходят для обработки древовидно структурированных данных. Программы, действия в которых непременно выполняются последовательно одно за другим, в общем случае не могут эффективно (с точки зрения компактности и понятности кода) обработать сложные иерархические структуры. Структура XML документов. Определение типа документа (DTD) Зачем может понадобиться определение структуры документа? Это может быть полезно при обмене XML документами между различными организациями или даже разными подразделениями одной организации. Наличие определения структуры позволит гарантировать (проверять) правильность получаемых и отдаваемых документов. Определение структуры документа может понадобиться разработчикам программного обеспечения. Например, разработчики СУБД могут формально определить допустимые структуры документов, которые разработчики сервера приложений могут отправлять в СУБД. Это позволит формально проверять корректность работы сервера приложений с СУБД, не обращаясь к разработчикам СУБД для тестирования. Ну и т.д. Далее мы познакомимся с двумя способами определить структуру документа Первый способ - использовать определение типа документа (Document Type Definition - DTD). DTD определяет элементы, которые можно использовать в XML документе; их содержимое; порядок, в котором они могут появляться в документе и другие детали структуры документа. Синтаксис DTD является частью спецификации XML. Другой способ - использовать схемы. Схемы позволяют определять все то, что и DTD, а кроме этого еще и типы данных, более сложные структуры данных, чем в DTD. Существует несколько языков описания схем. Наиболее распространенные из них W3C XML Schema и RELAX NG. Мы будем изучать язык RELAX NG как более простой. DTD позволяет нам определять базовую структуру XML документа. Давайте внимательно рассмотрим DTD (Пример 3.16, «DTD»), который определяет структуру XML документа, приведенного в первой части лекции (Пример 3.2, «Пример XML»). < address> < name> < title> Mrs.< /title> < first-name> Mary < /first-name> < last-name> McGoon < /last-name> < /name> < street> 1401 Main Street < /street> < city> Anytown< /city> < state> NC< /state> < postal-code> < /postal-code> < /address> Пример 3.2. Пример XML <! -- address.dtd --> <! ELEMENT address (name, street, city, state, postal-code)> <! ELEMENT name (title? first-name, last-name)> <! ELEMENT title (#PCDATA)> <! ELEMENT first-name (#PCDATA)> <! ELEMENT last-name (#PCDATA)> <! ELEMENT street (#PCDATA)> <! ELEMENT city (#PCDATA)> <! ELEMENT state (#PCDATA)> <! ELEMENT postal-code (#PCDATA)> Пример 3.16. DTD : • Элемент address содержит name, street, city, state и postal-code. Все эти элементы должны быть обязательно, и именно в этом порядке. • Элемент name содержит опциональный (об опциональности говорит символ? ) элемент title, за которым следуют элементы first-name и last-name. • Все остальные элементы содержат внутри себя текст (об этом говорит #PCDATA; вы не можете включать другие элементы в такой элемент). Синтаксис DTD очень прост, но с его помощью легко описывать, какие элементы могут появляться в XML документе. С другой стороны, синтаксис DTD отличается от синтаксиса XML Символы в DTD Для указания того, как часто в XML документе могут использоваться те или иные элементы, используются специальные символы. Вот несколько примеров. • В записи <! ELEMENT address (name, city, state)> элемент address должен содержать элементы name, city, state именно в этом порядке. Все они обязательны. Запятая определяет последовательность символов. • Запись <! ELEMENT name (title?, first-name, last-name)> означает, что элемент name содержит опциональный элемент title, за которым следуют обязательные элементы first-name и last-name. Символ? означает, что элемент может появиться один раз или не появиться вообще. • Запись <! ELEMENT addressbook (address+)> означает, что элемент addressbook содержит один или более элементов address. Символ + означает, что элемент должен встречаться как минимум один раз, но может и больше. • Запись <! ELEMENT private-addresses (address*)> означает, что private-addresses может содержать ноль или более элементов address. Звездочка означает, что элемент может встречаться любое количество раз, в том числе и ноль. • Запись <! ELEMENT name (title?, first-name, (middle-initial | middle-name)?, last-name)> означает, что элемент name содержит опциональный элемент title, за которым следует first-name. Далее возможны варианты: либо middle-initial, либо middle-name, но только что-нибудь одно. В конце обязательно присутствует элемент last-name. Вертикальная черта указывает на варианты. Может встретиться только один элемент из всех, разделенных вертикальной чертой. Обратите также внимание на то, как используются скобки для группировки элементов. • Запись <! ELEMENT name ((title?, first-name, last-name) | (surname, mothers-name, given-name))> говорит о том, что элемент name может содержать одну из двух последовательностей: опциональный title, first-name и last-name; или surname, mothers-name, given-name. Определение атрибутов Очень глубоко в технологию DTD в этом курсе мы погружаться не будем, но некоторые основные вопросы затронем. Один из таких наиболее простых но важных вопросов - определение атрибутов. Для любого элемента можно определить: • Какие атрибуты в нем могут быть • Какие атрибуты обязательны • Какие значения по умолчанию принимают атрибуты • Список всех возможных значений для атрибута Представьте, что вы хотите изменить DTD так, чтобы у элемента city был атрибут state (Пример 3.17, «Определение атрибута»). <! ELEMENT city (#PCDATA)> <! ATTLIST city state CDATA #REQUIRED> Пример 3.17. Определение атрибута Элемент city объявлен так же, как и раньше, но теперь для него добавлена инструкция ATTLIST, в которой определяется, что у элемента city есть атрибут state. Ключевое слово CDATA говорит анализатору, что атрибут state содержит внутри себя текст, а ключевое слово $REQUIRED говорит, что это обязательный атрибут. Если бы вы хотели указать, что атрибут необязательный, тогда вам необходимо использовать вместо #REQUIRED ключевое слово #IMPLIED (Пример 3.18, «Определение необязательного атрибута»). <! ELEMENT city (#PCDATA)> <! ATTLIST city state CDATA #IMPLIED> Пример 3.18. Определение необязательного атрибута В предыдущих примерах мы определяли только один атрибут. Чтобы определить несколько атрибутов, просто перечислите их в директиве ATTLIST (Пример 3.19, «Определение нескольких атрибутов»). <! ELEMENT city (#PCDATA)> <! ATTLIST city state CDATA #IMPLIED postal-code CDATA #REQUIRED> Пример 3.19. Определение нескольких атрибутов И последнее, о чем мы упомянем в контексте DTD, это указание допустимых значений атрибута. Вы можете указать список значений, и анализатор будет контролировать, что атрибут принимает значения только из заданного списка значений. Кроме того, можно задать и значение по умолчанию (Пример 3.20, «Список допустимых значений атрибута, значение по умолчанию»). <! ELEMENT city (#PCDATA)> <! ATTLIST city state CDATA (AZ|CA|NV|OR|UT|WA) " CA" > Пример 3.20. Список допустимых значений атрибута, значение по умолчанию
2. Язык преобразования XML документов - XSLT. Назначение, общая структура и основные понятия. Шаблоны как функции. Определение правил шаблона Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 833; Нарушение авторского права страницы