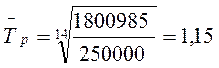|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
РЕГРЕССИОННЫЙ АНАЛИЗ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХСтр 1 из 7Следующая ⇒
РЕГРЕССИОННЫЙ АНАЛИЗ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ЯВЛЕНИЙ
Корреляционно-регрессионный анализ как общее понятие включает в себя предварительный анализ наличия связи, ее направления и приблизительное определение ее формы, осуществляемый с помощью метода приведения параллельных данных, балансового, аналитических группировок, графического метода, а также изучение степени тесноты взаимосвязи между признаками посредством расчета различных мер связи. Регрессионный анализ заключается в определении аналитического выра-жения связи, в котором изменение одной величины (называемой зависимой или результативным признаком) обусловлено влиянием одной или нескольких независимых величин (факторов), а множество всех прочих факторов, также оказывающих влияние на зависимую величину, принимается за постоянные и средние значения. Регрессия может быть однофакторной (парной) и многофакторной (множественной). Нахождение аналитического выражения взаимосвязи производится путем построения уравнения регрессии. Уравнение регрессии позволяет определить, каким в среднем будет значение результативного признака (У) при том или ином значении факторного признака (X), если остальные факторы, влияющие на У и не связанные с X, рассматривались неизменными (т. е. мы абстрагировались от них).
2.1. Основные задачи и предпосылки применения корреляционно-регрессионного анализа
Все явления и процессы, характеризующие социально-экономическое развитие и составляющие единую систему национальных счетов, тесно взаимосвязаны и взаимозависимы между собой. Целью регрессионного анализа является оценка функциональной зависимости условного среднего значения результативного признака (Y) от факторных (х1, х2; …, хn). Основной предпосылкой регрессионного анализа является то, что только результативный признак (Y) подчиняется нормальному закону распределения, а факторные признаки х1, х2; …, хn могут иметь произвольный закон распределения. В анализе динамических рядов в качестве факторного признака выступает время t. При этом в регрессионном анализе заранее подразумевается наличие причинно-следственных связей между результативным (Y) и факторными (х1, х2; …, хn ) признаками. Уравнение регрессии, или статистическая модель связи социально-эконо-мических явлений, выражаемая функцией y = f (х1, х2, …, хn ) является адекватным реальному моделируемому явлению или процессу при соблюдения следующихтребований их построения. 1. Совокупность исследуемых исходных данных должна быть однородной и математически описываться непрерывными функциями. 2. Возможность описания моделируемого явления одним или несколькими уравнениями причинно-следственных связей. 3. Все факторные признаки должны иметь количественное (цифровое) выражение. 4. Наличие достаточно большого объема исследуемой выборочной совокупности. 5. Причинно-следственные связи между явлениями и процессами следует описывать линейной или приводимой к линейной формами зависимости. 6. Отсутствие количественных ограничений на параметры модели связи. 7. Постоянство территориальной и временной структуры изучаемой совокупности. Соблюдение этих требований позволяет исследователю построить статис-тическую модель связи, наилучшим образом аппроксимирующую моделируемые социально-экономические явления и процессы. Построение регрессионных моделей, какими бы сложными они не были, само по себе не вскрывает полностью всех причинно-следственных связей. Основой их адекватности является предварительный качественный анализ, основанный на учете специфики и особенностей сущности исследуемых социально-экономических явлений. К задачам регрессионного анализа относятся: 1) установление формы зависимости; 2) определение уравнения регрессии т.е. определение неизвестных коэффициентов модели; Оценка неизвестных значений зависимой переменной. По аналитическому выражению различают линейную и нелинейную связи. Линейная связь имеет место, когда с возрастанием (или убыванием) значений Х значения Y увеличиваются (или уменьшаются) более или менее равномерно. Математически линейная связь может быть выражена уравнением прямой, которое называется линейным уравнением регрессии: Yтеор = b0 + b1·X, где Х- факторный признак; Yтеор –результативный признак; b0, b1- коэффициенты уравнения. Если же она выражается уравнением какой-либо кривой линии (параболы, гиперболы, степенной, показательной, экспоненциальной и т. д.), то такую связь называют нелинейной. В экономическом анализе для ее выражения часто пользуются уравнением параболы второго порядка: Yтеор= b0 + b1·X + b2· X2 Уравнение нелинейной связи может быть выражено и в виде уравнения гиперболы: Yтеор= b0 + b1/X или показательной функции: Yтеор= b0 · b1X
После определения формы связи, т.е. вида уравнения регрессии, по эмпирическим данным определяют коэффициенты искомого уравнения.
Расчет коэффициентов модели
Чаще всего определение коэффициентов уравнения регрессии осуществляется с помощью метода наименьших квадратов (МНК). Сущность МНК заключается в том, что сумма квадратов отклонений фактических значений результативного признака от теоретических значений, полученных по уравнению регрессии, должна быть минимальной.
где Yi- фактические (экспериментальные) значения результативного признака; Yтеор- значения результативного признака, полученного по уравнению регрессии. В зависимости от формы связи в каждом конкретном случае определяется своя система уравнений, удовлетворяющая условию минимизации. Линейная зависимость Для функции y = f(x), имеющей вид: y = b0 +b1x. коэффициенты a0 и a1 определяются из условия, чтобы сумма квадратов разности между левой и правой частями была бы минимальной.
Используя метод нахождения экстремума путем вычисления соответствующих частных производных и приравнивая их к нулю
находят систему нормальных уравнений:
Коэффициенты b1 и b0 определяются по формулам:
Экспоненциальная (степенная) зависимость Для функции y = f(x), имеющей вид: Коэффициенты b1 и b0 определяются по формулам
Параболическая зависимость Для функции y = f(x), имеющей вид: y = b0+b1x+b2x2 . Коэффициенты b0, b1, b2 определяются при решении системы из трех уравнений (например, методом Гаусса ):
Для функции y = f(x), имеющей вид: y= b0 + b1/X система уравнений для определения коэффициентов уравнения регрессии имеет вид:
Для функции y = f(x), имеющей вид: y=b0· b1x система уравнений для определения коэффициентов уравнения имеет вид:
Коэффициент эластичности
На основе уравнений регрессии часто рассчитывают коэффициенты эластичности результативного признака относительно факторного. Коэффициент эластичности Э показывает на сколько процентов в среднем изменится результативный признак Y при изменении факторного признака Х на 1% и рассчитывается по формуле Эхi=bi Пример расчета коэффициентов уравнения регрессии
Рассмотрим применение регрессионного и корреляционного методов при анализе экономических процессов. Имеются статистические данные о зависимости рентабельности производства продукции (%) по ряду предприятий, производящих одноименную продукцию, от выработки (в стоимостных показателях) на одного среднесписочного работника производственно-промышленного персонала. Полученные данные представлены в таблице (табл. 3):
Таблица 3 – Статистические данные по предприятиям
Для прогноза результирующего признака Y применим простую модель парной регрессии, в которой используется только одна факторная переменная — Х. Анализ табличных данных показывает наличие прямой линейной зависимости между факторным Х (выработки продукции) и результативным признаком Y (рентабельностью производства). Тесноту и направление связи между факторным и результативным признаками определим с помощью коэффициентом корреляции r.
где Xi и Yi - значения факторного и результативного признаков соответственно; n – объем выборки (число пар исходных данных). Для рассматриваемого примера значение коэффициента корреляции составляет: r = Для описания рассматриваемого экономического процесса с помощью метода экономико-математического моделирования рассчитаем параметры уравнения регрессии: Yтеор = b0 + b1·X. Данные для расчета параметров представим в табл.4
Таблица 4 – Таблица расчетных данных для определения коэффициентов уравнения регрессии
Коэффициенты b1 и b0 линейного уравнения регрессии определяются по формулам (13), (13а):
Подставив данные из таблицы получим следующие значения коэффициентов: b0 =2, 423; b1 = 0, 00873. Для примера линейное уравнение регрессии имеет вид: Yтеор = 2, 423 + 0, 00873·X. Коэффициент b1 характеризует наклон линии регрессии. b1 = 0, 00873 и это означает, что при увеличении Х на единицу ожидаемое значение Y возрастет на 0, 00873. Отсюда b1 может быть интерпретирован как прирост нормы рентабельности, который варьирует в зависимости от средней выручки. Свободный член уравнения b0 =2, 423 у. е.; это значение Y при X, равном нулю. Поскольку маловероятно значение выработки, равное нулю, то можно интерпретировать b0 как меру влияния на величину рентабельности других факторов, не включенных в уравнение регрессии. Регрессионная модель может быть использована для прогноза уровня рентабельности, (который будет на предприятии, например, где средняя выработка на одного работника составит 600 руб.) Для того чтобы определить прогнозируемое значение, следует Х = 600 подставить в регрессионное уравнение: Y = 2, 423 + 0, 00873 • 600 = 7, 661. Отсюда прогнозируемый уровень рентабельности для предприятия со средней выработкой 600 рублей на одного рабочего ППП составляет 7, 661 %. Коэффициент эластичности для модели Э = 0, 00873 Изменение уровня рентабельности производственного предприятия, определяемое средней выработкой на одного работника можно определить также с помощью параболической зависимости. Для определения коэффициентов параболы используются формулы, полученные на основе решения системы уравнений (15). Данные для расчета коэффициентов приведены в табл. 4 В результате расчетов получено уравнение параболы со следующими коэффициентами: y = 4, 7893+0, 00156 x+5, 1· 10 –6 x2 . Для проверки адекватности моделей, построенных на основе линейного и параболического уравнения регрессии, проверим значимость каждого коэффициента, используя формулы (20-23). Для коэффициента b0 линейной модели
Для коэффициент b1 линейной модели
Для коэффициента b0 параболической модели
Для коэффициента b1 параболической модели
Для коэффициента b2 параболической модели
tкр = 2, 1 при α = 0, 05; n=n-k-1=20-1-1=18 Из приведенных расчетов видно, что при α = 0, 05 значимыми является коэффициенты линейного уравнения регрессии и параболического, за исключением коэффициента, стоящего перед квадратом факторного признака, что свидетельствует об отсутствии квадратичной зависимости между рассматриваемыми признаками моделируемого экономического процесса. Проверка адекватности всей модели осуществляется с помощью расчета ЯВЛЕНИЙ Процесс развития, изменения социально-экономических явлений во времени в статистике называют динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя, расположенных в хронологическом порядке. Процесс экономического развития изображается в виде совокупности перерывов непрерывного, позволяющих детально проанализировать особенности развития при помощи характеристик, отражающих изменение параметров экономической системы во времени. Составными элементами ряда динамики являются показатели уровней ряда и периоды времени (годы, кварталы, месяцы, сутки) или моменты (даты) времени. Ряды динамики различаются по следующим признакам. 1. По времени - моментные и интервальные ряды. Интервальный ряд динамики - последовательность, в которой уровень явления относится к результату, накопленному или вновь произведенному за определенный интервал времени. Таковы, например, ряды показателей объема продукции по месяцам года, количества отработанных человеко-дней по отдельным периодам и т. д. Если же уровень ряда показывает фактическое наличие изучаемого явления в конкретный момент времени, то совокупность уровней образует моментный ряд динамики. Примерами моментных рядов могут быть последовательности показателей численности населения на начало года, величины запаса какого-либо материала на начало периода и т. д. Важное аналитическое отличие моментных рядов от интервальных состоит в том, что сумма уровней интервального ряда дает вполне реальный показатель - общий выпуск продукции за год, общие затраты рабочего времени, общий объем продаж акций и т. д., сумма же уровней моментного ряда, хотя иногда и подсчитывается, но реального содержания, как правило, не имеет. 2. По форме представления уровней - ряды абсолютных, относительных и средних величин (табл. 6-8). 3. По расстоянию между датами или интервалам времени выделяют полные и неполные хронологические ряды. Полные ряды динамики имеют место, когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами. Это равноотстоящие ряды динамики (см. табл. 6 и 7). Неполные - когда принцип равных интервалов не соблюдается (см. табл. 8). 4. По числу показателей можно выделить изолированные и комплексные (многомерные) ряды динамики. Если ведется анализ во времени одного показателя, имеем изолированный ряд динамики (см. табл. 6 и 7). Комплексный ряд динамики получаем в том случае, когда в хронологической последовательности дается система показателей, связанных между собой единством процесса или явления (см. табл. 8). Таблица 6 - Объем продаж долларов США на ММВБ, млн долл.
Таблица 7 - Индекс инфляции в 1996 г
Таблица 8 - Потребление основных продуктов питания на одного члена семьи, кг/год
Критерий серий
Рассмотрим последовательность N значений случайной величины x(k) и каждое значение отнесем к одной из двух взаимно исключающих категорий, которые обозначим знаками плюс (+) и минус (-). В качестве примера рассмотрим последовательность измеренных значений величины xi при i = 1, 2, 3, ..., N, среднее значение которых равно Полученная последовательность наблюдений, имеющих знак плюс или минус, может выглядеть следующим образом: + + - + + - + + + - + - - + - - + - - - 1 2 3 4 5 6 7 8 9 10 11 12 Серией называется последовательность одинаковых значений, перед которыми или после которых расположены значения другой категории или наблюдения отсутствуют вообще. В рассмотренном примере имеется r = 12 серий в последовательности из N = 20 наблюдений. Число серий, которое встречается в последовательности наблюдений, позволяет определить, являются ли результаты независимыми случайными наблюдениями над одной и той же случайной величиной. Если после-довательность N наблюдений представляет собой независимые наблюденные значения одной и той же случайной величины, т. е. вероятность знаков (+) и (-) не меняется от одного наблюдения к другому, то выборочное распределение числа серий в последовательности есть случайная величина r(k) со средним значением
и дисперсией
где N1 - число наблюдений со знаком (+), N2 - число наблюдений со знаком (-). В частном случае, когда N1 = N2 =N/2 , представленные соотношения перепишутся в виде
В приложении 1 приведена таблица, содержащая данные о 100a-про-центных точках функции распределения r(k). Если последовательность значений содержит тренд, то это означает, что вероятность знаков (+) или (-) меняется от одного наблюденного значения к другому. Наличие тренда можно проверить следующим образом. Рассмотрим гипотезу об отсутствии тренда, т. е. предположим, что полученные данные представляет собой независимые значения одной и той же случайной величины. Полагая, что число наблюденных значений со знаком (+) равно числу значений со знаком (-), можно считать, что число серий в последовательности будет иметь выборочное распределение, представленное в приложении 1. Гипотезу можно подвергнуть проверке при любом уровне значимости a путем сопоставления фактического числа серий с граничными значениями rn; 1-a/2 и rn; a/2, где n=N/2. Если фактическое число серий выходит за границы этого интервала, гипотезу следует отвергнуть при выбранном уровне значимости. В противном случае ее можно принять. Например, имеется последовательность из N=20 чисел: 5, 5; 5, 1; 5, 7; 5, 2; 4, 8; 5, 7; 5, 0; 6, 5; 5, 4; 5, 8; 6, 8; 6, 6; 4, 9; 5, 4; 5, 9; 5, 4; 6, 8; 5, 8; 6, 9; 5, 5. Определим, являются ли независимыми наблюденные значения, путем проверки числа серий, которые встречаются, если отсчитывать наблюденные значения от их медианы. Выполним проверку при уровне значимости a = 0, 05. Просматривая выборку, можно убедиться, что медианой данного ряда является значение x = 5, 6. Примем, что числа более 5, 6 имеют знак (+), а менее 5, 6 - знак (-). В результате получаем последовательность - - + - - + - + - + + + - - + - + + + - 1 2 3 4 5 6 7 8 9 10 11 12 13 Таким образом, имеется 13 серий, представляющих последовательность 20 наблюденных значений. Рассмотрим гипотезу о независимости наблюденных значений. Область принятия этой гипотезы определяется интервалом [r10; 1-a/2 < r £ r10; a/2].
Критерий инверсий
Рассмотрим последовательность N значений случайной величины x(k). Обозначим эти значения символом xi, где i == 1, 2, 3, ..., N. Подсчитаем теперь число случаев, когда xi > xj, при i < j. Каждое такое неравенство называется инверсией. Общее число инверсий обозначается символом А, которое формально определяется так. По ряду значений x1, x2 …, xN определим величину
Тогда Например,
Для примера рассмотрим последовательность N = 8 значений: x1=5, x2=3, x3=8, x4=9, x5=4, x6=1, x7=7, x8=5. В этой последовательности x1 > x2, x1 > x5 и Если последовательность N наблюдений содержит независимые значения одной и той же случайной величины, то число инверсий есть случайная величина А(k) со средним значением
и дисперсией
В приложении 2 содержатся данные о 100a-процентных точках функции распределения величины А(k).
Критерий инверсий вообще говоря, имеет большую мощность, чем критерий серий, при выявлении монотонного тренда в последовательности наблюдений. Однако критерий инверсий обладает малой мощностью при выявлении колебательного тренда. Например, проверим последовательность N = 20 значений, рассмотренных ранее, на наличие тренда при уровне значимости a = 0, 05. Число инверсий в этом случае таково:
Общее число инверсий А= 62. Рассмотрим гипотезу о том, что наблюдения представляют независимые значения случайной величины х(k), не содержащей тренда. Область принятия гипотезы определяется неравенством A20; 1-a/2 < A £ A20; a/2. По данным приложения 2 при a = 0, 05 находим A20; 1-a/2=A20; 0, 975 = 64 и A20; a/2=A20; 0, 025= 125. Следовательно, гипотезу отвергают при 5%-ном уровне значимости, так как значение А = 62 не попадает в интервал между 64 и 125. Заметим, что гипотеза о независимости этой же последовательности значений при использовании критерия серий была принята. Этот факт иллюстрирует разницу в чувствительности двух методов проверки. Таблица 11 – Таблица исходных данных и расчетных показателей динамического ряда (изменения стоимости зернокомбайна «Дон 1500» во времени)
3.5. Средние показатели рядов динамики
Средние показателирядов динамики являются обобщающей характеристикой его абсолютных уровней, абсолютной скорости и интенсивности изменения уровней ряда динамики. Различают следующие средние показатели: средний уровень ряда динамики, средний абсолютный прирост, средний темп роста и прироста. Методы расчета среднего уровня ряда динамики зависят от его вида и способов получения статистических данных. В интервальном ряду динамики с равноотстоящими уровнями во времени расчет среднего уровня ряда Средний уровень ряда для цены зернокомбайна по исходным данным составляет: Рср = 10333219/15=688881, 26 руб Если интервальный ряд динамики имеет не равноотстоящие уровни, то средний уровень ряда вычисляется по формуле
где t – число периодов времени, в течение которых уровень не изменяется. Для моментального ряда с равноотстоящими уровнями средняя хронологическая рассчитывается по формуле
где n – число уровней ряда. Средняя хронологическая для неравноотстоящих уровней моментного ряда динамики вычисляется по формуле
Определение среднего абсолютного прироста производится по цепным абсолютным приростам по формуле:
Средний абсолютный прирост для цены комбайна «Дон 1500» составляет 85322, 34/14=6094, 5 руб Среднегодовой темп роста вычисляется по формуле средней геометрической:
где m – число коэффициентов роста. Среднегодовой темп роста для зернокомбайна составляет:
Среднегодовой темп прироста получим, вычтя из среднего темпа роста 100%. Среднегодовой темп прироста для зернокомбайна «Дон 1500» составляет 15 %. ЛИТЕРАТУРА 1. Теория статистики: под 18ред. проф. Р.А. Шмойловой. –3-е изд., перераб. – М.: Финансы и статистика, 191999. -.: ил. 2. Сиденко А.В., Попов Г.Ю., Матвеева В.М. Статистика: Учебник. – М.: Издательство «Дело и сервис», 2000. – 464 с. 1. Ефимова М.Р., Рябцев В.М. Общая теория статистики: Учебник. – М.: финансы и статистика, 1991. – 304 с. 2. Общая теория статистики: Статистическая методология в изучении коммерческой деятельности: Учебник/ А.И. Харламов, О.Я. Башина, В.Т. Бабурин и др.; под ред. А.А. Спирина, О.Э. Башиной. – М.: Финансы и статистика, 1996. – 296 с. 3. Адамов В.Е. Статистика промышленности. – М.: Финансы и статистика, 1987. 4. Бакланов Г.И. и др. Статистика промышленности: Учебник. – М.: Статистика, 1976.–476 с. 5. Курс экономической статистики / Под ред. Проф. А.И. Петрова. – М.: Статистика, 1975. 6. Статистика рынка товаров и услуг / Под ред. Проф. И.К. Белявского. – М.: Финансы и статистика, 1995. 7. Вишневская Ю.У. Общая теория статистики: Практикум. – 1983. 8. Дарков Г.В., Максимов Г.К. Финансовая статистика. – М.: Финансы, 1975. 9. Елисеева И.И., Юзбашев М.М. Общая теория статистики: Учебник. – М.: Финансы и статистика, 1991 10. Маслова Н.П. Статистическая теория: предмет, содержание, структура и перспективы. – Ростов н/Д: РГЭА, 1995. 11. Остапенко В.В. Акционерное дело и ценные бумаги: справочное пособие. – М.: Экономика, 1995. 12. Статистика товарного обращения. – М.: Финансы и статистика, 1990 Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 1706; Нарушение авторского права страницы
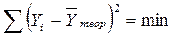
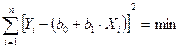 (11 )
(11 )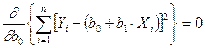
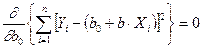 ,
, 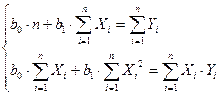 (12)
(12)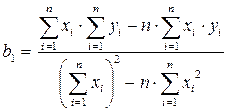 , (13)
, (13)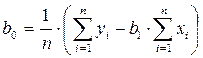 , или
, или 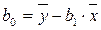 . (13 а )
. (13 а )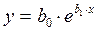

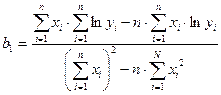 ,
, 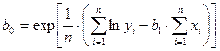 (14)
(14)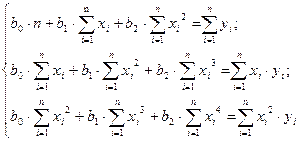 (15)
(15)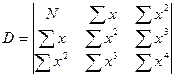 ,
, 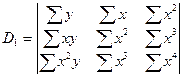
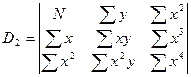 ,
, 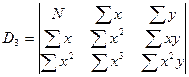
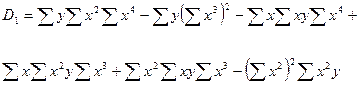 ;
; 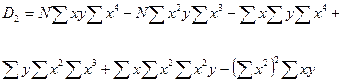 ;
; 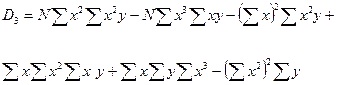 ;
; 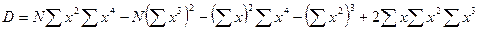 .
.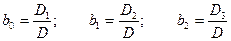 (16)
(16)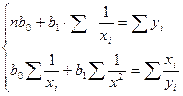 (17)
(17)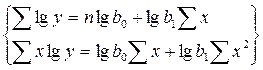 (18)
(18)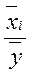 (19)
(19)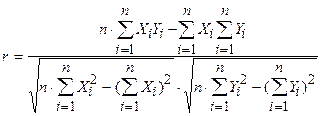
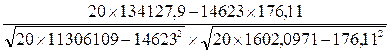 = 0, 955
= 0, 955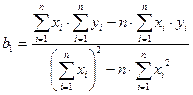 ,
, 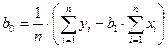 .
.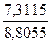 = 0, 7249, т. е. при увеличении средней выработки на одного работника по отдельному предприятию 1% уровень рентабельности в среднем вырастет на 0, 7%.
= 0, 7249, т. е. при увеличении средней выработки на одного работника по отдельному предприятию 1% уровень рентабельности в среднем вырастет на 0, 7%.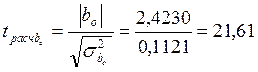
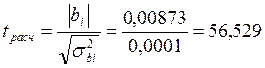 .
.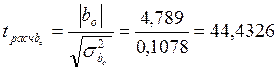
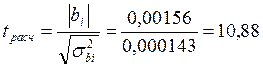
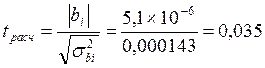
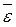 .
. 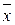 . Каждое наблюденное значение
. Каждое наблюденное значение 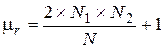
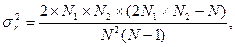
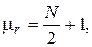
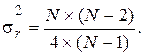
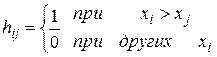 .
.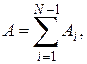 где
где 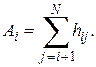
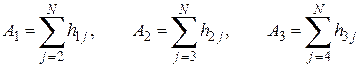 и т.д.
и т.д.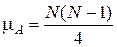
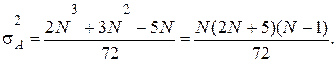
 производиться по формуле средней арифметической простой:
производиться по формуле средней арифметической простой: 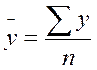 .
. 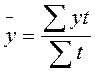 ,
, 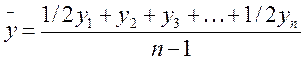 ,
, 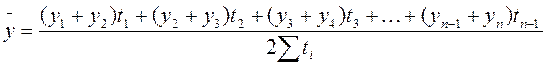 .
.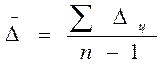 или
или 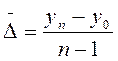 .
.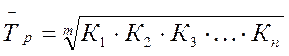 , или
, или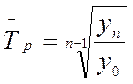 ,
,