
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ЛЕКЦИЯ 5 ТЕМА: Системы баз данныхСтр 1 из 5Следующая ⇒
ЛЕКЦИЯ 5 ТЕМА: Системы баз данных СОДЕРЖАНИЕ Основы систем баз данных понятия, характеристика, архитектура. Модели данных. Нормализация Ограничение целостности данных. Оптимизация запросов и их обработка Основы SQL. Параллельная обработка данных и их восстановление. Проектирование и разработка баз данных. Технология программирования QRM. Распределенные, параллельные, гетерогенные базы данных ( 2 часа) Основы систем баз данных понятия, характеристика, архитектура. Основные понятия и определения Стержневые идеи современных информационных технологий базируются на концепции баз данных. Согласно этой концепции, основой информационных технологий являются данные, которые должны быть организованы в базы данных в целях адекватного отображения изменяющегося реального мира и удовлетворения информационных потребностей пользователей. Одним из важнейших понятий в теории баз данных является понятие информации. Под информацией понимаются любые сведения о каком-либо событии, процессе, объекте. Данные — это информация, представленная в определенном виде, позволяющем автоматизировать ее сбор, хранение и дальнейшую обработку человеком или информационным средством. Для компьютерных технологий данные — это информация в дискретном, фиксированном виде, удобная для хранения, обработки на ЭВМ, а также для передачи по каналам связи. База данных (БД ) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области, или иначе БД — это совокупность взаимосвязанных данных при такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений в определенной предметной области. БД состоит из множества связанных файлов. Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Автоматизированная информационная система (АИС) — это система, реализующая автоматизированный сбор, обработку, манипулирование данными, функционирующая на основе ЭВМ и других технических средств и включающая соответствующее программное обеспечение (ПО) и персонал. В дальнейшем в этом качестве будет использоваться термин информационная система (ИС), который подразумевает понятие автоматизированная. Каждая ИС в зависимости от ее назначения имеет дело с той или иной частью реального мира, которую принято называть предметной областью (ПрО) системы. Выявление ПрО — это необходимый начальный этап разработки любой ИС. Именно на этом этапе определяются информационные потребности всей совокупности пользователей будущей системы, которые, в свою очередь, предопределяют содержание ее базы данных. Банк данных (БнД) является разновидностью ИС. БнД — это система специальным образом организованных данных: баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных. Под задачами обработки данных обычно понимается специальный класс решаемых на ЭВМ задач, связанных с видом, хранением, сортировкой, отбором по заданному условию и группировкой записей однородной структуры. Отдельные программы или комплекс программ, реализующие автоматизацию решения прикладных задач обработки данных, называются приложениями. Приложения, созданные средствами СУБД, относят к приложениям СУБД. Приложения, созданные вне среды СУБД с помощью систем программирования, использующих средства доступа к БД, к примеру, Delphi или Visual Studio, называют внешними приложениями. Современное состояние технологий баз данных Информационные системы, созданные средствами технологии баз данных, иногда принято называть банками данных (БнД). БнД включает в себя: ƒ технические средства; ƒ одну или несколько БД; СУБД; словарь или каталог данных; администратора; вычислительную систему; обслуживающий персонал.
БнД — информационная система, реализующая централизованное управление данных в интересах всех пользователей АС. (Средство интеграции данных).
Рисунок 3. Банк данных Обеспечение целостности данных на уровне БД предполагает наличие средств, позволяющих удостовериться, что информация в БД всегда остается корректной и полной. Целостность данных должна обеспечиваться независимо от способа занесения данных в память (в интерактивном режиме, посредством импорта или с помощью специальной программы). К средствам обеспечения целостности данных на уровне СУБД относятся: · встроенные средства для назначения первичного ключа, в том числе средства для работы с типом полей с автоматическим приращением, когда СУБД самостоятельно присваивает новое уникальное значение; · средства поддержания ссылочной целостности, которые обеспечивают запись информации о связях таблиц и автоматически пресекают любую операцию, приводящую к нарушению ссылочной целостности. Большую пользу для обеспечения условий целостности данных, приносят триггеры, которые сохраняют связи между таблицами при добавлении, обновлении или удалении строк в таблицах. Триггером называют сохраненную процедуру специального типа, которая вступает в действие, когда пользователь изменяет данные в указанной таблице с помощью одной или нескольких из следующих операций: UPDATE, INSERT или DELETE. Триггеры позволяют выполнять запросы к другим таблицам и могут содержать сложные инструкции SQL Импорт-экспорт данных. Функция импорта позволяет средствам СУБД обрабатывать информацию из внешних источников двумя способами: · Данные из других приложений (например, электронных таблиц) преобразуются из другого формата (например, формата электронной таблицы) и копируются в новую таблицу СУБД; · Объекты импортируются из одной БД в другую БД в рамках одной СУБД. Экспорт представляет собой способ вывода данных и объектов БД в другую БД, электронную таблицу или формат файла, позволяющий другой БД, приложению или программе использовать эти данные или объекты БД. Экспорт по своей сути напоминает копирование и вставку через буфер обмена. Разработка и сопровождение приложений. СУБД обладают развитыми средствами для создания приложений, Этими средствами являются: мощные языки программирования; средства реализации меню, экранных форм ввода-вывода данных и генерации отчетов; средства генерации прикладных программ (приложений), генерации исполнимых файлов. Многопользовательские функции. Практически все СУБД предназначены для работы в многопользовательских средах, но обладают для этого различными возможностями. Наиболее общими функциями являются следующие: · блокировка БД, файла, записи, поля; · идентификация рабочей станции, установившей блокировку; · обновление информации после модификации; · контроль за временем обращения и повторения обращения; · обработка транзакций; · работа с сетевыми операционными системами. Репликация баз данных представляет собой создание специальных копий – реплик общей БД, с которыми пользователи могут одновременно работать на разных компьютерах. Отличие реплики от обычной копии файлов БД заключается в том, что для реплики БД возможна синхронизация изменений. При проведении сеанса синхронизации все изменения, сделанные одним пользователем, могут автоматически вноситься в общую реплику и реплики других пользователей, и наоборот. Интеграция с Интернет отражает новейшие направления развития функциональных возможностей СУБД. Одно из этих направлений – публикация данных в Интернете и в корпоративной сети. СУБД позволяют публиковать объекты БД в виде статических и динамических Web-страниц. Во многих объектах БД возможно использование гиперссылок для перехода к другим документам. Существуют средства создания интерактивных Web-страниц для просмотра, ввода и анализа данных. Основными WWW-технологиями доступа к БД являются следующие: 1. Однократное или периодическое преобразование содержимого баз данных в статические документы. Содержимое БД просматривает специальная программа-преобразователь, создающая множество файлов в виде связных HTML-документов. Полученные файлы копируются на WWW-сервер. Доступ к ним осуществляется как к статическим гипертекстовым документам сервера. Такая технология эффективна при небольших массивах данных простой структуры с редким обновлением, а также при пониженных требованиях к актуальности данных, предоставляемых через ресурс WWW. Создание статических Web-страниц не требует использования механизма поиска и индексирования данных. Доступ к БД осуществляется с помощью специальной программы, запускаемой WWW-сервером в ответ на запрос WWW-клиента. Программа, обрабатывая запрос, просматривает содержимое БД, создает динамический выходной НТМL-документ, возвращаемый клиенту. Данная технология предпочтительна для больших БД со сложной структурой и при необходимости поддержки операций поиска, а также при частом обновлении и невозможности синхронизации преобразования БД в статические документы с обновлением содержимого. Обеспечение безопасности данных – одна из важных функций современных СУБД. Средства безопасности обеспечивают выполнение таких операций, как: шифрование прикладных программ, шифрование данных, защита паролем, ограничение доступа к БД или отдельным ее объектам. Можно дать следующую обобщенную характеристику возможностям современных СУБД. 1. СУБД включает язык определения данных, с помощью которого можно определить базу данных, ее структуру, типы данных, а также средства задания ограничений для хранимой информации. В многопользовательском варианте СУБД этот язык позволяет формировать представления как некоторое подмножество базы данных, с поддержкой которых пользователь может создавать свой взгляд на хранимые данные, обеспечивать дополнительный уровень безопасности данных и многое другое. 2. СУБД позволяет вставлять, удалять, обновлять и извлекать информацию из базы данных посредством языка управления данными. 3. Большинство СУБД могут работать на компьютерах с разной архитектурой и под разными операционными системами, причем на работу пользователя при доступе к данным практически тип платформы влияния не оказывает. 4. Многопользовательские СУБД имеют достаточно развитые средства администрирования БД. 5. СУБД предоставляет контролируемый доступ к базе данных с помощью: ƒ системы обеспечения безопасности, предотвращающей несанкционированный доступ к информации базы данных; ƒ системы поддержки целостности базы данных, обеспечивающей непротиворечивое состояние хранимых данных; ƒ системы управления параллельной работой приложений, контролирующей процессы их совместного доступа к базе данных; ƒ системы восстановления, позволяющей восстановить базу данных до предыдущего непротиворечивого состояния, нарушенного в результате аппаратного или программного обеспечения. Архитектура СУБД
Рисунок – трехуровневая архитертура базы данных По числу уровней описания данных, поддерживаемых СУБД, различают одно-, двух- и трехуровневые системы. В настоящее время чаще всего поддерживается трехуровневая архитектура описания БД, с тремя уровнями абстракции, на которых можно рассматривать базу данных. Различают два типа независимости от данных: логическую и физическую. Логическая независимость от данных означает полную защищенность внешних схем от изменений, вносимых в концептуальную схему. Такие изменения концептуальной схемы, как добавление или удаление новых сущностей, атрибутов или связей, должны осуществляться без необходимости внесения изменений в уже существующие внешние схемы для других групп пользователей. Физическая независимость от данных означает защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему. Такие изменения внутренней схемы, как использование различных файловых систем или структур хранения, разных устройств хранения, модификация индексов или хеширование, должны осуществляться без необходимости внесения изменений в концептуальную или внешнюю схемы. Далее рассмотрим каждый из трех названных уровней. Внешний уровень — это пользовательский уровень. Пользователем может быть программист, или конечный пользователь, или администратор базы данных. Представление базы данных с точки зрения пользователей называется внешним представлением. Каждая группа пользователей выделяет в моделируемой предметной области, общей для всей организации, те сущности, атрибуты и связи, которые ей интересны. Эти частичные или переопределенные описания БД для отдельных групп пользователей или ориентированные на отдельные аспекты предметной области называют подсхемой. Функции СУБД Управление данными во внешней памяти. Семантические модели Семантическая модель (концептуальная модель, инфологическая модель) — модель предметной области, предназначенная для представления семантики предметной области на самом высоком уровне абстракции. Это означает, что устранена или минимизирована необходимость использовать понятия «низкого уровня», связанные со спецификой физического представления и хранения данных. Семантическое моделирование стало предметом интенсивных исследований с конца 1970-х годов. Основным побудительным мотивом подобных исследований (то есть проблемой, которую пытались разрешить исследователи) был следующий факт. Дело в том, что системы баз данных обычно обладают весьма ограниченными сведениями о смысле хранящихся в них данных. Чаще всего они позволяют лишь манипулировать данными определенных простых типов и определяют некоторые простейшие ограничения целостности, наложенные на эти данные. Любая более сложная интерпретация возлагается на пользователя. Однако было бы замечательно, если бы системы могли обладать немного более широким объемом сведений и несколько интеллектуальнее отвечать на запросы пользователя, а также поддерживать более сложные (то есть более высокоуровневые) интерфейсы пользователя.[…] Наиболее известным представителем класса семантических моделей является модель «сущность-связь» (ER-модель). В XX веке доминировала методология управления производством получившая название «Фордизм», по имени своего основоположника Генри Форда. Фордизм — модель массового производства стандартизированных товаров на сборочных конвейерах с использованием низкоквалифицированных работников, занятых простыми операциями и объединенных на крупных фабриках. Такое производство обладает «эффектом масштаба» и отличается низкой себестоимостью единицы продукции, доступной массовому потребителю. Один из основных постулатов фордизма: «Производить большие партии изделий выгоднее, чем мелкие», прочно укоренился в головах управленцев XX века. Со второй половины XX века (после второй мировой войны) предпринималось множество попыток модифицировать фордистскую модель. В частности на заводах «Тойота» в 50х годах стали ставить эксперименты, адаптируя американские концепции массового производства к реалиям послевоенной промышленности Японии. Тогда была переделана система крепления прессового инструмента, чтобы сделать его замену более быстрой. Потом были и другие новаторские решения и открытия, со временем сложившиеся в новую методологию — Lean Manufacturing (LM) – Бережливое производство. Цель LM – производить продукцию с постоянным уменьшением усилий людей, с меньшим объемом применения аппаратуры, как можно быстрее, на минимальном пространстве и при этом делать то, что ожидает купить клиент. Эта концепция родилась в послевоенной Японии, тогда промышленность страны испытывала нехватку во всем: в ресурсах, материалах, аппаратуре, кадрах, и не могла рассчитывать на помощь государства. Япония мобилизовала свои силы и стала рационально использовать любые ресурсы, одновременно находясь в процессе поиска, выявления и ликвидации потерь любого масштаба. · потери при ненужной транспортировке; · потери из-за лишних этапов обработки; · потери из-за лишних запасов; · потери из-за ненужных перемещений; · потери из-за выпуска дефектной продукции. Позже к видам потерь были добавлены: · перегрузка рабочих, сотрудников или мощностей при работе с повышенной интенсивностью. Быстрореагирующее производство (Quick Response Manufacturing, QRM) Происхождение бережливого производства связано с компанией Тойота, особенность которой – постоянные большие объёмы выпускаемой продукции. Однако за последние несколько лет произошёл быстрый рост количества функции, предлагаемых производителями своим заказчикам, это связанно в частности с: Развитием Интернет, который позволяет покупателю/заказчику без труда оценивать огромное количество функций и делать свой выбор. Данные тенденции развития дают основания полагать, что в XXI веке будет расти спрос на небольшую по объёму и крайне разнообразную продукцию с такими функциями, которые пожелают сами заказчики покупатели. На этой почве и появилась методология QRM, которая была сформирована американским математиком Раджан Сури и подробно описана в его монографии вышедшей в свет в 1998 году. Цель QRM – сократить время выполнения заказа за счет всех операций компании, как внутренних, так и внешних.
Обычный заказ лежит 5 дней в отделе приема заказов, прежде чем его отправят на производство, потом уходит 12 дней, находится на изготовление компонентов, 9 дней на сборку и 8 дней на то, чтобы уже выполненный заказ упаковали и отправили заказчику. В итоге на выполнение заказа уходит 34 дня (белый цвет). Если сложить участки серого цвета, то получим 19, 5 часов, т.е меньше 3 дней при восьми часовом рабочем дне. Остальное время – это когда данной работой никто не занимается. По словам Сури, данное соотношение не является случайным, во многих производственных проектах реальное время работы составляет менее 5% от времени выполнения заказа. переход от функциональных цехов к QRM-ячейкам. Ячейка – это набор независимых (отделенных от остальной компании), сочетаемых друг с другом многофункциональных ресурсов (людей и станков). QRM-ячейка направлена на выполнение всех видов работ вокруг определенного рыночного сегмента (например, конкретный тип продукции). В философии QRM-ячейки можно проследить некоторую аналогию с Scrum командой. иметь в запасе мощность до 20% для наиболее часто используемого оборудования. Это необходимо для предупреждения «пробок», уменьшает КПП и делает предприятие более готовым в изменчивости спроса. поиск непроизводительного времени с уровня цеха и до управления предприятием, служб маркетинга и логистики. Как показывает практика, больше всего времени расходуется впустую в офисах, а не на производстве. ориентация работников всех подразделений на единую цель – снижение временных затрат. Важно то, что учитывается не только время на те или иные процедуры, но и общее время от заказа до его отгрузки клиенту. Единая цель, к которой стремятся рабочие, а отсюда и единые параметры оценки работы для ее достижения, сплачивают команду работников. Все знают что время – деньги, но на самом деле время – гораздо большие деньги, чем полагают большинство менеджеров! Для компаний, работающих по AM, свойственна способность быстро реконфигурировать трудовые и материальные ресурсы, чтобы не упускать возможности заработать и избегать неприятностей. Основным преимуществом концепции AM является умение оперативно подстраиваться под изменяющуюся ситуацию и работать в условиях неопределенности на рынке. AM подходит для отраслей, где высок уровень неопределенности (например ИТ, потребительская электроника). Сценарий · Как можно больше интеллектуальных ресурсов и как можно меньше материальных. · Постоянная стержневая группа кроссфункциональных специалистов. Группа специалистов на проектах на договорной основе, а также вынос непрофильных работ на аутсорс. Штат не раздувается, а люди составляющие ядро компании горят делом. · Далее приведены принципы, на которые ориентируется AM, помогающие компании оставаться на плаву при изменчивости рынка: · Разветвлённая сеть партнерских организации (с дублирующими и дополняющими компетенциями) и поставщиков. · Организация работ: проектно—командная, иерархия минимальная.
Таким образом, особое внимание, в компаниях типа AM уделяется минимизации потерь от возможных, неожиданных негативных изменений, таких как потеря контрактов или рынка производимого изделия. Одновременно, многодисциплинарная, быстро расширяемая, команда и разветвленная партнерская сеть Выбор той или иной методологии зависит от объёмов производства, а также от отрасли в которой работает компания. Если производство серийное, то главная задача как правило — это минимизация расходов. Компании, создающие небольшие партии продукта, должны уметь выполнять заказы быстро, поэтому интереснее ориентироваться на QRM. Те, кто работает с индивидуальными заказами — могут выбрать AM. Таблица основных отличий QRM, AM Автоматизация заводов сейчас востребована, и мы регулярно бываем на разных типах заводов, обсуждая с заказчиками варианты сотрудничества. Если посмотреть на Российские производственные компании через призму вышеописанных методологий, я могу выделить 4 типа заводов: Небольшие и средние современные производственные компании. Маленькие инновационные производственные предприятия. Параллельные системы баз данных начинают вытеснять традиционные компьютеры основного класса, так как они позволяют работать со значительно более крупными базами данных в режиме, поддерживающем транзакции. Десять лет назад будущее параллельных машин баз данных выглядело неопределенным даже для самых верных их сторонников. Большинство проектов разработки машин баз данных концентрировалось вокруг специализированного аппаратного обеспечения, находящегося еще в стадии разработки, такого как CCD-память (charge-coupled device, устройство с зарядовой связью), пузырьковая память (bubble memory), диски с фиксированными головками и оптические диски. Ни одна из этих технологий себя не оправдала. Таким образом, создалось впечатление, что традиционые центральные процессоры, электронная основная память и магнитные диски с подвижными головками будут доминировать в течение еще многих лет. В то время прогнозы сходились на том, что пропускную способность диска удастся увеличить в два раза, а скорость процессоров возрастет намного больше. Следовательно, скептики предрекали, что многопроцессорные системы вскоре столкнутся с проблемами ограниченной пропускной способности при вводе-выводе, если только не будет найден способ расширения этого узкого места. В то время как прогноз о будущем аппаратного обеспечения оказался достаточно точным, скептики ошиблись в предсказании будущего параллельных систем баз данных. За последние десять лет компании Teradata, Tandem и ряд новоявленных компаний успешно разрабатывали и продавали параллельные машины. Каким образом параллельным системам баз данных удалось избежать участи экспоната в кунсткамере компьютерных неудач? Одно из объяснений – широкое распространение реляционных баз данных. Реляционные базы данных, как мы уже знаем, состоят из таблиц. Каждая таблица состоит из столбцов (их называют полями или атрибутами) и строк (их называют записями или кортежами). Таблицы в реляционных базах данных обладают рядом свойств. Основными являются следующие: Столбцы располагаются в определенном порядке, который создается при создании таблицы. В таблице может не быть ни одной строки, но обязательно должен быть хотя бы один столбец. У каждого столбца есть уникальное имя (в пределах таблицы), и все значения в одном столбце имеют один тип (число, текст, дата...). На пересечении каждого столбца и строки может находиться только атомарное значение (одно значение, не состоящее из группы значений). Таблицы, удовлетворяющие этому условию, называют нормализованными. Две операции могут работать последовательно, если направить вывод одной операции на вход другой. Это так называемый конвейерный параллелизм (pipelined parallelism). Если разделять вводимые данные между несколькими процессорами и памятью, часто оказывается возможным разбить операцию на несколько независимых операций, каждая из которых работает с частью данных. Такое разделение данных и обработки называется раздельным параллелизмом (partitioned рarallelism) (смотри рисунок).
Потоковый подход к реляционным операторам включает как конвейерный, так и разделенный параллелизм. Реляционные операции принимают отношения (однородные наборы записей) в качестве ввода и производят отношения на выходе. Это позволяет составлять из них графы потоков данных, что делает возможным конвейерный параллелизм (слева), при котором одна операция вычисляется параллельно с другой, и раздельный параллелизм, при котором операции (сортировка и просмотр на диаграмме справа) дублируются для каждого источника данных и дубли выполняются параллельно. При потоковом подходе к организации систем баз данных необходима операционная система типа клиент-сервер, основанная на передаче сообщений для взаимосвязи параллельных процессов, в которых выполняются реляционные операции. Для этого, в свою очередь, требуется высокоскоростная сеть, обеспечивающая взаимосвязь параллельных процессоров. Такие средства казались экзотическими еще десять лет назад, теперь же они находятся в основном русле компьютерной архитектуры. В парадигме " клиент-сервер" высокоскоростные локальные сети (LAN) рассматриваются как основа для большей части персональных компьютеров, рабочих станций и программного обеспечения рабочих групп. В то же время механизмы " клиент-сервер" являются превосходным базисом для разработки распределенных баз данных. Перед разработчиками машин основного класса встала трудноразрешимая задача создания достаточно мощных компьютеров, способных удовлетворить требования к ЦПУ и вводу/выводу, предъявляемые реляционными базами данных, которые обслуживают одновременно большое число пользователей или осуществляют поиск в терабайтных базах данных. Тем временем стали широко доступны мультипроцессоры разных поставщиков, основанные на быстрых и недорогих микропроцессорах, включая Encore, Intel, NCR, nCUBE, Sequent, Tandem, Teradata и Thinking Machines. Эти машины обладают большей мощностью за меньшую цену, чем их аналоги класса мэйнфрейм. Модульная архитектура мультипроцессоров позволяет при необходимости наращивать систему, увеличивая скорость процессоров, расширяя основную и внешнюю память для ускорения выполнения какой-либо конкретной работы или для расширения системы с целью выполнить большую работу за то же время. Литература 1.Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4. ЛЕКЦИЯ 5 ТЕМА: Системы баз данных СОДЕРЖАНИЕ Основы систем баз данных понятия, характеристика, архитектура. Модели данных. Нормализация Ограничение целостности данных. Оптимизация запросов и их обработка Основы SQL. Параллельная обработка данных и их восстановление. Проектирование и разработка баз данных. Технология программирования QRM. Распределенные, параллельные, гетерогенные базы данных ( 2 часа) Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 2556; Нарушение авторского права страницы


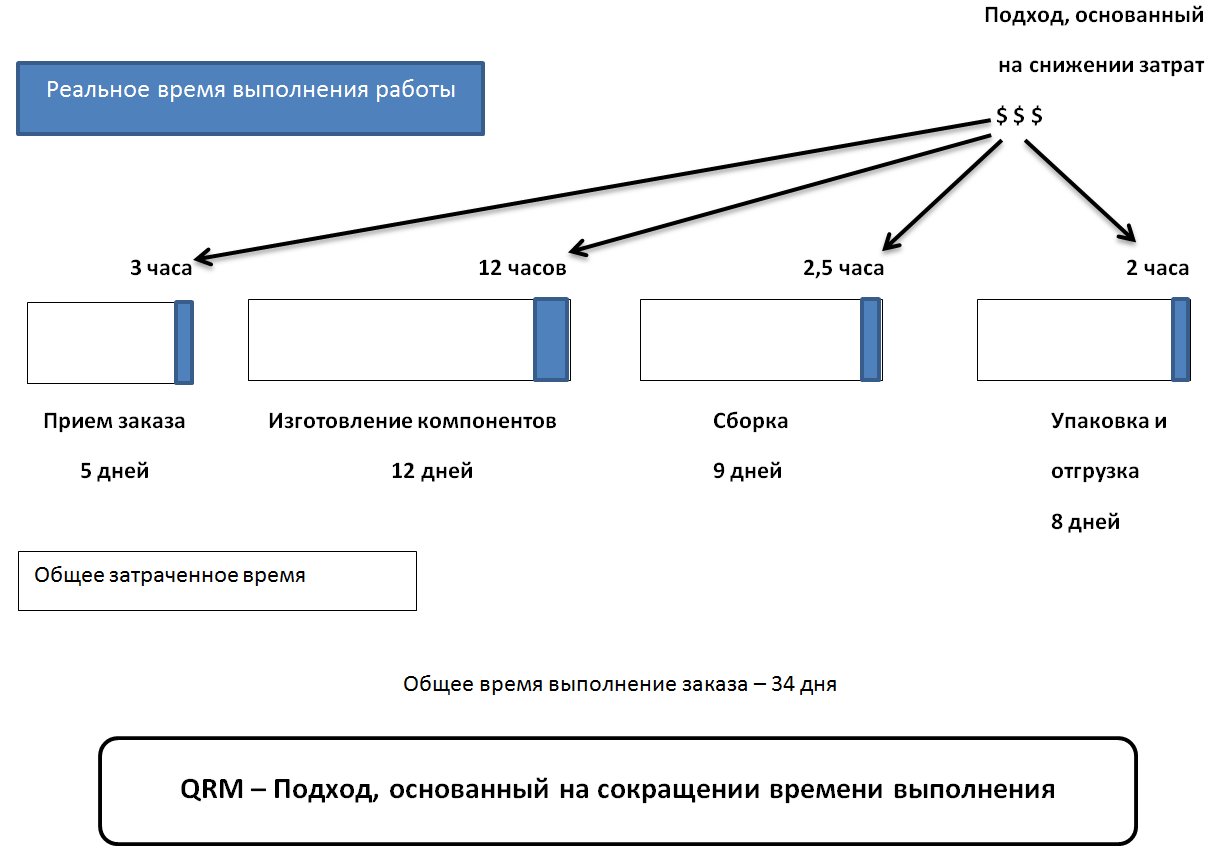
 Рисунок конвеерный параллелизм
Рисунок конвеерный параллелизм