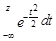|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Оценки дисперсий прогнозов при детерминированных параметрах моделей.⇐ ПредыдущаяСтр 16 из 16
В этой связи, в научной литературе обычно рассматриваются методы оценки дисперсий прогнозов процессов, представленных в виде временных рядов, не учитывающие ошибки оценок коэффициентов, описывающих их моделей. Таким образом, эти методы учитывают специфику моделей с детерминированными параметрами. Очевидно, что эти методы не в полной мере адекватны условиям поставленной задачи. Однако они характеризуются определенной математической строгостью и при небольших ошибках (дисперсиях) коэффициентов моделей позволяют получить относительно точные оценки дисперсий прогнозов, а следовательно, и их доверительных интервалов. Эти методы можно рассматривать как следствие более общих результатов теории прогнозирования, Г. Валдом, Н.Винером, А. Колмогоровым, П. Уиттлом. В их основе лежит идея представления прогнозного значения рассматриваемого процесса, описываемого моделями типа АРСС(k, m), в виде условного математического ожидания, зависящего от известных в моменты Т, Т–1,... его значений в прошлом, и ошибки, выражаемой текущим и предшествующими значениями “белого шума”. В целях избежания излишней громоздкости рассмотрим эти методы на примере наиболее простых вариантов моделей временных рядов первого порядка. Модель АР(1). В соответствии с выражением (12.34) представим модель АР(1) в виде следующего уравнения:
которое для наших целей более удобно представить в следующем виде:
Из выражения (12.48) вытекает, что прогноз на один шаг вперед, т. е. на момент Т+1, является случайной величиной, определяемой следующим выражением:
Математическое ожидание этого прогноза имеет следующий вид:
Ошибка такого прогноза определяется как
При определении дисперсии прогноза различие между параметром a1 и его оценкой a1 во внимание не принимается. В результате имеем
Для момента Т+2 прогноз определяется по следующей схеме:
Из выражения (12.53) следует, что математическое ожидание этого прогноза имеет следующий вид:
а ошибка D уT(2) равна
В свою очередь, с учетом независимости eT+2 и eT+1 из выражения (12.54) следует, что дисперсия прогноза на момент Т+2 оценивается согласно следующему выражению:
Продолжая схему прогнозирования, определенную выражениями (12.48)-(12.55) несложно видеть, что прогноз на l шагов вперед на основе модели АР(1) представляется в следующем виде:
Его математическое ожидание определяется выражением
а ошибка и ее дисперсия – соответственно выражениями
Из выражений (12.57), в частности, вытекает, что так как ç a1ç < 1, то c ростом l математическое ожидание прогноза стремится к математическому ожиданию стационарного процесса
а дисперсия прогноза стремится к дисперсии процесса
поскольку из выражения (12.59) следует, что
Модель СС(1). Прогнозируя на момент Т+1 на основе модели СС(1)
получим следующее прогнозное значение рассматриваемой переменной y:
Поскольку математическое ожидание ошибки eT+1 равно нулю, а ее значение в момент времени Т известно, то математическое ожидание такого прогноза равно
где Из (12.61) и (12.62) вытекает, что при неразличимости параметра b1 и его оценки b1 ошибка такого прогноза равна eT+1.
а его дисперсия –
Прогноз на два шага по модели СС(1) определяется выражением
Его математическое ожидание равно
Ошибка такого прогноза равна
а ее дисперсия определяется следующим выражением:
Несложно заметить, что выражение (12.68) определяет величину дисперсии ошибки прогноза, полученного с использованием модели СС(1), на любое количество шагов вперед, поскольку сама ошибка представляется в следующем виде:
Модель АРСС(1, 1). Модель АРСС(1, 1), являющуюся комбинацией рассмотренных выше моделей АР(1) и СС(1), представим в следующем виде:
Несложно заметить, что прогнозное значение переменной уT+1 определяется следующим выражением:
Математическое ожидание такого прогноза с учетом равенства нулю математического ожидания ошибки eT+1 и известного значения ошибки
Прогнозируя на момент Т+2, получим следующие выражения, определяющие прогнозное значение рассматриваемой переменной и его математическое ожидание соответственно:
Из выражений (12.72) и (12.73) вытекает, что оценка дисперсии прогноза на два шага вперед с использованием модели АРСС(1, 1) может быть представлена в следующем виде:
Продолжая последовательно процедуру прогнозирования на момент Т+l, получим следующие выражения прогнозного значения случайной величины и ее математического ожидания:
Соответственно из выражений (12.75) и (12.76) вытекает, что оценка дисперсии этой ошибки (дисперсии прогноза) может быть определена следующим образом:
Несложно показать, что l®¥ оценка дисперсии прогноза уT+l стремится к следующему пределу:
По аналогичной схеме в предположении о детерминированном характере показателей моделей могут быть получены выражения, определяющие оценки дисперсий прогнозов моделей временных рядов и других модификаций, включая модели финансовой эконометрики. Вопросы к главе XII 1. Что представляет собой “верификации прогноза”? 2. Как оценивается точность прогноза? 3. Что представляет собой “доверительный интервал прогноза”? 4. Охарактеризуйте методы оценки доверительного интервала прогноза в моделях с детерминированными и случайными параметрами. 5. Охарактеризуйте особенности прогнозирования на основе моделей временных рядов. Упражнения к главе XII Задание 12.1 На основании выборки из 20 наблюдений оценено следующее уравнение зависимости затрат на рекламу у от годового оборота х в определенной отрасли (см. задание 2.4):
Известно, что ошибка уравнения распределена нормально с нулевым математическим ожиданием и постоянной дисперсией. Требуется: 1. Определить 95%-й прогнозный интервал математического ожидания целевой переменной y0 при x0=30. 2. Определить 95%-е прогнозные интервалы математического ожидания целевой переменной при значениях объясняющей переменной 10, 15, 20, 25. Отобразить все прогнозные интервалы и линию регрессии на графике. Прокомментировать результат. Проверить правильность утверждения: “С доверительной вероятностью 95% все перечисленные прогнозные значения математического ожидания лежат в данном интервале ”. 3. Оценить 95%-й прогнозный интервал для отдельного значения целевой переменной при x0=30 и сравнить его с прогнозным интервалом в п. 1.
Задание 12.2 На основании выборки из 10 наблюдений оценено следующее уравнение зависимости спроса на некоторое благо у домохозяйств определенной структуры (у) от цены этого блага (х1) и дохода домохозяйства (х2) (см. задание 2.15):
Известно, что ошибка уравнения распределена нормально с нулевым математическим ожиданием и постоянной дисперсией. Требуется: 1. Рассчитать 95%-й прогнозный интервал математического ожидания целевой переменной y0 для значений объясняющих переменных (5, 5; 1100) и (6, 0; 1150). 2. Определить 95%-й прогнозный интервал для отдельного значения целевой переменной при таких же, как в п. 1, значениях объясняющих переменных.
Задание 12.3 Имеется информация о средних транспортных индексах в летний период 1999 г. (см. табл. 6.3). Требуется на основе модели ARIMA (0, 1, 1), оцененной в задании 6.5, построить точечный прогноз исследуемого показателя на 3 периода вперед.
Задание 12.4 Имеются данные процесса контроля качества (см. табл. 6.5). Требуется на основании модели ARIMA (1, 1, 1), оцененной в задании 6.6 п. 2, построить точечный прогноз исследуемого показателя на 3 периода вперед.
Задание 12.5 Имеется модель следующая модель GARCH(1, 1):
Требуется построить точечный прогноз условной дисперсии на 3 периода вперед, если последнее ее расчетное значение для базисного периода равно 0, 7619, а остаток составляет 0, 0707.
Задание 12.6 На основании информации, приведенной в табл. 12.1, оценены коэффициенты структурной формы системы взаимозависимых уравнений Сt =41, 4245+0, 6216× Yt+ еt; Yt = Сt + It. Требуется: 1. Оценить коэффициенты прогнозной формы. 2. Рассчитать точечный прогноз валового национального продукта и потребления, если объем инвестиций равен 164, 50. 3. Построить 95%-й совместный прогнозный интервал для эндогенных переменных. 4. Определить 95%-е прогнозные интервалы для отдельно взятых эндогенных переменных.
Таблица 12.1
КРАТКИЙ СЛОВАРЬ ТЕРМИНОВ adjustedR2 – скорректированный коэффициент детерминации autocorrelation function (ACF)– автокорреляционная функция autoregressive conditional heteroscedasicity (ARCH)– авторегрессионная модель с условной гетероскедастичностью autoregressive model (AR)– авторегрессионная модель autoregressive integrated moving average model (ARIMA)– интегрированная модель авторегрессии-скользящего среднего best linear unbiesed estimator (BLUE) –лучшая (эффективная) оценка в классе линейных несмещенных оценок binary variable – бинарная переменная, которая может принимать значения 0 и 1 Box-Jenkins model (ARIMA) – модель Бокса и Дженкинса, интегрированная модель авторегрессии-скользящего среднего censored model – модель, основанная на цензурированной выборке, зависимые переменные ограничиваются некоторым пороговым значением classical normal regression (CNR)– классическая регрессионная модель, ошибки которой имеют совместное нормальное распределение classical regression (CR)– классическая регрессионная модель coefficient of determination (R-squared) – коэффициент детерминации conditional distribution – условное распределение confidence interval– доверительный интервал consistent estimator– состоятельная оценка convergence in distribution – конвергенция по распределению correlation– корреляция correlation coefficient– коэффициент корреляции count data – счетные данные covariance– ковариация cross-section data – поперечные данные, показатели, характеризующие разные объекты в фиксированный момент времени density function– функция плотности dependent variable– зависимая переменная distributed lags model – модель распределенных лагов distribution – распределение dummy variable – фиктивная переменная duration model – модель “времени жизни” efficient estimator – эффективная оценка endogenous variable – эндогенная переменная, переменная, определяемая внутри модели estimator – оценивание exogenous variable – экзогенная, внешняя по отношению к модели переменная explanatory variables – объясняющие переменные exponential smoothing– экспоненциальное сглаживание fitted value – прогнозное значение generalized autoregressive conditonal heteroscedasticity model (GARCH)– обобщенная авторегрессионная условно гетероскастичная модель generalized least squres (GLS) estimation– обобщенный метод наименьших квадратов goodness-of-fit– качество приближения моделью данных hazard rate– интенсивность отказов heteroscedasticity– гетероскедастичность, непостоянство дисперсии homoscedasticity– гомоскедастичность, постоянство дисперсии idempotent matrix– идемпотентная матрица independent variable – независимая переменная index function– индексная функция indirect least squares– косвенный метод наименьших квадратов information matrix– информационная матрица instrumental variable (IV)– инструментальная переменная intersept– свободный член joint distributoin– совместное распределение kernel estimator – метод оценивания непараметрической регрессии lag operator– оператор сдвига lagged variable– запаздывающая переменная latent variable– скрытая, ненаблюдаемая переменная law of large numbers– закон больших чисел likelihood function– функция правдоподобия linear probability model– линейная модель вероятности linear regression model– линейная регрессионная модель logit model– logit-модель, нелинейная модель бинарной зависимой переменной, основанная на логистическом распределении ошибки loglikelihood function– логарифм функции правдоподобия marginal distribution – маржинальное распределение, распределение одной или нескольких компонент случайного вектора maximum likelihood (ML)– метод максимальльного правдоподобия maximum likelihood estimate – оценка максимального правдоподобия maximum likelihood estimator – оценивание с помощью метода максимального правдоподобия maximum score estimator (MSCORE) – оценивание по методу максимального счета mean– математическое ожидание mean absolute deviation– среднее абсолютное отклонение mean absolute percentage error– среднее относительное отклонение mean squared error– среднеквадратическая ошибка model for binary choice– модель бинарного выбора model for multiple choice– модель множественного выбора model specification– спецификация модели moving average– скользящее среднее moving average (MA) model– модель скользящего среднего multicollinearity– мультиколлинеарность multiple regression model– модель множественной регрессии normal (Gaussian) distribution– нормальное (Гаучссовское) распределение OLS-estimator– оценивание с помощью метода наименьших квадратов ommited variables – пропущенная (невключенная в модель) независимая переменная ordired data – упорядоченные данные ordinary least squares (OLS) method– метод наименьших квадратов panel data– сочетание временного и поперечного ряда, т. е. совокупность показателей, относящихся к разным объектам, за определенный период времени partial autocorrelation function (PACF)– частная автокорреляционная функция partial correlation coefficient– частный коэффициент корреляции probit model – probit-модель, нелинейная модель бинарной зависимой переменной, основанная на нормальном распределении ошибки qualitative variable – качественная переменная random utility model– модель случайной полезности random walk– случайное блуждание ranking variable– ординальная, порядковая, ранговая, переменная reduced form of the model– приведенная или прогнозная форма модели residuals– остатки restricted regression– регрессия с ограничениями на параметры sample– выборка sample mean (variance, covariance, moment etc.)– выборочное среднее (дисперсия, ковариация, момент и т. д.) seemingly unrelated regression (SUR)– система внешне несвязанных уравнений selection model– модель, основанная на случайно усеченной выборке serial correlation– корреляция между показателями, относящимися к разным моментам времени significance level – уровень значимости simultaneous equations – одновременные уравнения slope– коэффициент наклона standart deviation– стандартное отклонение (квадратный корень из дисперсии) stationary time series – стационарный временной ряд strictly stationary process – строго стационарный процесс, стационарный в узком смысле процесс time-series data– временной ряд truncated model– модель, построенная для усеченной выборки, т. е. такой, из котрой исключены некоторые наблюдения two-stage least squares (2SLS)– двухшаговый метод наименьших квадратов unbiased estimator– несмещенная оценка unrestricted regression – модель без ограничений на параметры variance– дисперсия variance (covariance) matrix– ковариационная матрица weighted least squares – взвешенный метод наименьших квадратов white noise– “белый шум”, процесс с независимыми одинаково распределенными значениями с нулевыми средними ПРИЛОЖЕНИЕ 1. Функция стандартного нормального распределения Ф(z)=
ПРИЛОЖЕНИЕ 2. Двусторонние квантили распределения Стьюдента
ПРИЛОЖЕНИЕ 3. Таблица критерия Дарбина-Уотсона для a= 0, 05
Окончание приложения 2
ПРИЛОЖЕНИЕ 4. Таблица критерия Фишера для a = 0, 05 Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 862; Нарушение авторского права страницы
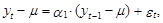
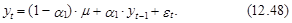
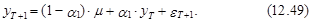
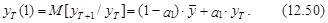
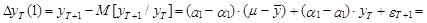

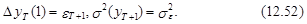


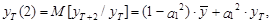
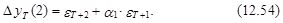
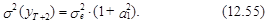
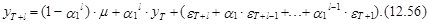



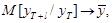

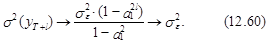
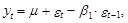
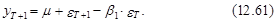

 – оценка ошибки модели в момент Т.
– оценка ошибки модели в момент Т.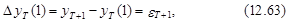
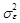

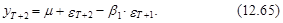
 –
–
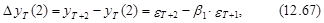


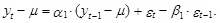
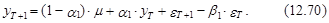
 равно
равно


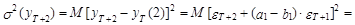
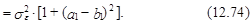
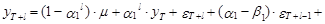


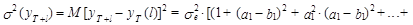

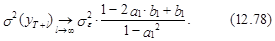

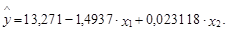
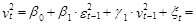
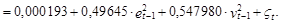
 ò
ò