
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Последовательный (линейный) поиск.
Если нет никакой дополнительной информации о разыскиваемых данных, то очевидный подход используется последовательный просмотр массива с увеличением шаг за шагом той его части, где желаемого элемента не обнаружено. Условия окончания поиска таковы: 1.Элемент найден, т.е. Ki=K. 2.Весь массив просмотрен и совпадения не обнаружено.
Алгоритм X. Алгоритм X. Дана таблица записей R1, R2, …, RN с ключами K1, K2, …, KN соответственно. Алгоритм предназначен для поиска записи с ключом K (N> =1). X1. Установить i1. X2. Если K=Ki, то алгоритм заканчивается успешно. X3. Увеличить I на 1. X4.Если i£ N, то перейти к X2. В противном случае алгоритм заканчивается неудачно. Данный алгоритм – не самая лучшая реализация последовательного поиска. Бинарный поиск (поиск делением пополам). Поиск можно сделать значительно более эффективным, если данные будут упорядочены. Основная идея – выбрать случайно некоторый элемент, предположим, Ki, и сравнить его с аргументом поиска. Если он равен K, то поиск заканчивается, если он меньше K, то мы заключаем, что все элементы с индексами < =i можно исключить из дальнейшего поиска. Если же он > K, то исключаются индексы > =i. Здесь используем два указателя l и u, которые указывают верхнюю и нижнюю границы поиска.
Алгоритм Y.
Y1. Установить l 1, u N. Y2. На этом шаге мы знаем, что если K имеется в таблице, то справедливо условие Kl£ K£ Ku. Если u< l, алгоритм завершается неудачно, в противном случае следует установить i [(l+u): 2], чтобы i соответствовало приблизительно середине рассматриваемой части таблицы. Y3. Если K< Ki, перейти к Y4. Если K> Ki, перейти к Y5. Если K=Ki, алгоритм успешно завершен. Y4. Установить u I-1 и перейти к Y2. Y5. Установить l I+1 и перейти к Y2.
Приведенный алгоритм, как и в случае последовательного описка, находит совпадающий элемент с наименьшим индексом.
20. Сортировка массива: области применения сортировки массива. Внутренняя и внешняя сортировки. Сортировка массива простым выбором, с помощью прямого обмена, вставками. Программисты традиционно используют слово «сортировка», обозначая им такую перестановку предметов, при которой они располагаются в порядке убывания и возрастания. Сортировкой называют процесс перегруппировки заданной последовательности объектов в некотором определённом порядке. Определённый порядок в последовательности объектов необходим для удобства работы с этими объектами. Одной из целей сортировки является облечение последующего поиска элементов в отсортированном множестве. Упорядоченные данные позволяют эффективно их обновлять, исключать, искать нужный элемент. Области применения сортировки массива: 1.Решение задачи группирования, когда нужно собрать вместе все элементы с одинаковыми значениями некоторого признака. Допустим, имеется 10000 элементов, расположенных в случайном порядке, причём значения многих из них равны и нужно переупорядочить массив так, что элементы с равными значениями занимали соседние позиции в массиве. 2.Поиск общих элементов в двух и более массивах. Если два или более массивов рассортировать в одно и том же порядке, то можно отыскать в них все общие элементы за один последовательный просмотр всех массивов без возвратов. 3.Поиск информации по значениям ключей, с её помощью можно сделать результаты обработки данных более удобными для восприятия человеком. Сортировка называется устойчивой, если она удовлетворяет такому дополнительному условию, что записи с одинаковыми ключами располагаются в прежнем порядке. Эффективность алгоритма сортировки зависит от многих факторов, в том числе - от числа сортируемых элементов - от степени начальной отсортированности - от необходимости исключения или добавления элементов - от доступа к сортируемым элементам (прямой или последовательный). Принципиальным для выбора метода сортировки является последний фактор. Если данные могут быть расположены в оперативной памяти, то к любому элементу возможен прямой доступ. Удобной структурой в этом случае выступает массив сортируемых элементов. Если данные размещены на внешнем носителе, то к ним могут обращаться лишь последовательно. В качестве структуры подобных данных можно взять файловый тип. В этой связи выделяют сортировку двух классов: массивов (внутренняя) и файлов (внешняя). Методы внутренней сортировки обеспечивают большую гибкость при построении структур данных и доступа к ним, внешние же методы обеспечивают достижение нужного результата в условиях ограниченных ресурсов. Для упорядочивания массивов по возрастанию или убыванию элементов, содержащихся в нем, используются различные методы сортировки (для одномерных массивов): 1. Сортировка выбором. Среди элементов, начиная с первого, выбирается наибольший (в случае упорядочивания по убыванию) или наименьший (в случае упорядочивания по возрастанию) элемент и ставится на первое место, а первый – на место наибольшего (наименьшего). Затем, начиная со второго, эта процедура повторяется. 2. Сортировка обменами (пузырьковая сортировка). Сравниваются два соседних числа аi и аi+1. Если аi > аi+1 (в случае упорядочивания по возрастанию) или аi < аi+1 (в случае упорядочивания по убыванию), то меньшее число (более легкий пузырек) перемещается на одну позицию влево. Обычно такой просмотр организуют с конца массива и после первого прохода самое маленькое число перемещается на первое место. Затем все повторяется с конца массива до второго элемента и т.д. известна и другая разновидность сортировки обменами, при которой также сравниваются два соседа и, если хотя бы одна из смежных пар была переставлена, просмотр начи нают с самого начала. Так продолжается до тех пор, пока очередной просмотр не закончится без перестановок. 3. Сортировка вставками. Идея этого метода базируется на последовательном пополнении ранее упорядоченных элементов. Пусть дана последовательность чисел 4. Сортировка Шелла. Метод Д.Л. Шелла, опубликованный в 1959 г., предлагает сортировать массив в несколько этапов. На первом этапе в сортировке участвуют достаточно далекие элементы, например, отстоящие друг от друга на восемь позиций. На втором проходе сортируются элементы, расстояние между которыми уменьшено, например до четырех. Затем упорядочиваются каждые вторые элементы и, наконец, на последнем этапе сравниваются смежные элементы. Выбор последовательно уменьшающихся шагов в методе Шелла представляет сложную математическую задачу. 5. Сортировка Хоара. Хоар применил подход, который известен в математике как «метод деления пополам». Выбирается какой-то средний элемент последовательности xx. Если он стоит на своем месте (имеется в виду ситуация, когда последовательность упорядочена), то все элементы, расположенные левее, не больше xx, а элементы, находящиеся правее, - не меньше xx.
Популярное:
|
Последнее изменение этой страницы: 2016-04-10; Просмотров: 718; Нарушение авторского права страницы


 . Пусть
. Пусть 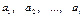 - упорядоченная последовательность. Т.е.
- упорядоченная последовательность. Т.е. 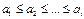 (в случае упорядочивания по возрастанию) или
(в случае упорядочивания по возрастанию) или  (в случае упорядочивания по убыванию). Берется следующее число
(в случае упорядочивания по убыванию). Берется следующее число  и вставляется в последовательность так, чтобы новая последовательность была также возрастающей (убывающей). Процесс производится до тех пор, пока все элементы от I+1 до n не будут перебраны.
и вставляется в последовательность так, чтобы новая последовательность была также возрастающей (убывающей). Процесс производится до тех пор, пока все элементы от I+1 до n не будут перебраны.