
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Оценка общего качества уравнения множественной регрессии
Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью
где Частные Частный
где Фактическое значение частного Для двухфакторного уравнения частные
С помощью частного
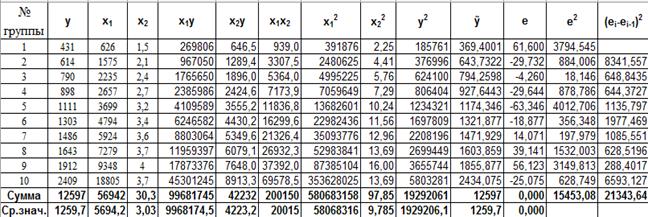
Решение типовых задач Задача 2.6.1. Рассмотрим в качестве примера множественной регрессии двухфакторную линейную модель. Исходные данные представлены в таблице 2.6.1. Таблица 2.6.1
Необходимо: 1. по МНК определить параметры множественной линейной регрессии 2. оценить статистическую значимость найденных эмпирических коэффициентов регрессии b1, b2; 3. сравнить влияние факторов на результат при помощи средних коэффициентов эластичности; 4. построить 95-% доверительные интервалы для найденных коэффициентов; 5. вычислить коэффициент детерминации R2 и оценить его статистическую значимость при α = 0, 05; 6. Проверить качество построенного уравнения регрессии с помощью F-статистики Фишера. 7. Оценить целесообразность включения в уравнение одного фактора после другого с помощью частных F-статистик Фишера. Решение: Определим по МНК коэффициенты уравнения регрессии. Для этого нам необходимо рассчитать следующую таблицу:
Для вычисления коэффициентов уравнения регрессии необходимо определить значения 6-ти сумм: 1. 2. 3. 4. 5. 6. Подставим полученные значения 6-ти сумм в формулы для расчета коэффициентов уравнения регрессии (m=2):
или
Таким образом, мы получили эмпирические значения параметров множественной линейной регрессии, которая имеет следующий вид:
Рассмотрим матричный вид определения вектора оценок коэффициентов регрессии а. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения: B = (XTX)-1XTY
Матрица X Матрица Y
Матрица XT
б. Умножаем матрицы, (XTX)
в. Умножаем матрицы, (XTY)
г. Находим определитель det (XTX)T = 7865492387 д. Находим обратную матрицу (XTX)-1
е. Вектор оценок коэффициентов регрессии равен: B = (XTX)-1XTY
Таким образом, мы получили уравнение регрессии: y = -190, 6301 + 0, 072x1 + 343, 293x2 2. оценим статистическую значимость найденных эмпирических коэффициентов регрессии b1, b2 с помощью t-статистики Стьюдента. Для этого сначала необходимо определить стандартные ошибки коэффициентов корреляции:
или
Определим значения t-статистик для каждого из коэффициентов:
Сравним полученные расчетные значения t-статистики Стьюдента с соответствующим критическим значением (см. таблица Распределение Стъюдента):
Так как 3. Рассчитаем средние коэффициенты эластичности для коэффициентов, входящих в уравнение множественной регрессии по следующей формуле:
Таким образом, в случае изменения фактора X1 (доход семьи) на 1% зависимая переменная Y (расходы на питание) изменится на 0, 326%, а если фактор X2 (количество человек в семье) изменится на 1%, то значение параметра Y изменится на 0, 826%. Следовательно, большей чувствительностью модель обладает по фактору количество человек в семье.
4. Построим 95-% доверительные интервалы для найденных коэффициентов:
Таким образом, если по другим выборкам мы получим значение коэффициентов, принадлежащие этим интервалам, то мы можем утверждать, что уравнение регрессии покажет такое же поведение для Y как определенное по выборке. 5. Определим коэффициент детерминации R2 и оценим его статистическую значимость при α = 0, 05
Следовательно, учтенные в модели факторы на 99, 5% определяют поведение зависимой переменной Y. 6. Проверим качество построенного уравнения регрессии с помощью F-статистики Фишера:
Сравним полученные расчетные значения F-статистики Фишера с соответствующим табличным значением (см. таблица Распределение Фишера):
Следовательно, так как 6. Оценим целесообразность включения в уравнение одного фактора после другого с помощью частных F-статистик Фишера
В нашем случае Сравнивая значения Сравнение
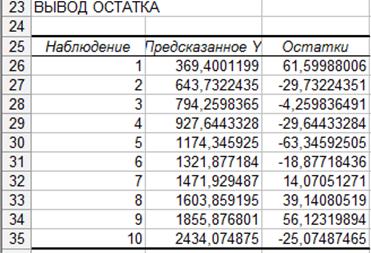
Рассмотрим решение задачи с помощью Excel Ехсеl позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Воспользуемся надстройкой Пакет анализа. Сервис — Анализ данных — Регрессия — ОК. Появляется диалоговое окно, которое нужно заполнить. В графе Входной интервал Y: указывается ссылка на ячейки, содержащие значения результативного признака у. В графе Входной интервал Х: указывается ссылка на ячейки, содержащие значения факторов х1,..., хm (m≤ 16). Если первые из ячеек содержат пояснительный текст, то рядом со словом Метки нужно поставить «галочку» Уровень надежности (доверительная вероятность) по умолчанию предполагается равным 95%. Если исследователя это значение не устраивает, то рядом со словами Уровень надежности нужно поставить «галочку» и указать требуемое значение. Поставив «галочку» рядом со словом константа-ноль, исследователь получит b0 =0 по умолчанию. Если нужны значения остатков еi и их график, то нужно поставить «галочки» рядом со словами Остатки и График остатков. ОК. Появляется итоговое окно. Если число в графе Значимость F превышает 1 — Уровень надежности, то принимается гипотеза R2 = 0. Иначе принимается гипотеза R2 ≠ 0. Р-значение — это значения уровней значимости, соответствующие вычисленным t-статистикам. Р-значение = СТЬЮДРАСП (t -статистика; n-m-1) (статистическая функция мастера функций ƒ x). Если Р-значение превышает 1 — Уровень надежности, то соответствующая переменная статистически незначима и ее можно исключить из модели. Нижние 95% и Верхние 95% — это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если исследователь согласился с принятым по умолчанию значением доверительной вероятности 95%, то последние два столбца будут дублировать два предыдущих столбца. Если исследователь вводил свое значение доверительной вероятности p, то последние два столбца содержат значения соответственно нижней и верхней границы p-процентных доверительных интервалов.
Таким образом, при определении зависимости расходов на питание (Y) от размера дохода (X1) и от количества человек в семье (X2) было обнаружено, что при неизменном значении параметра количество человек в семье и изменения на 1 у.е. размера дохода семьи, расходы на питание вырастут на 0, 07 у.е. В то же время, если не измениться доход семьи, а количество человек станет на одного больше, то расходы в семье вырастут на 343, 29 у.е. Поскольку
Упражнения и задачи
Задача 2.7.1 По 10-ти предприятиям изучается зависимость объема выпуска продукции от численности персонала и расхода материалов. Даны: Коэффициент детерминации: ? Множественный коэффициент корреляции: 0, 80 Уравнение регрессии: y =? +0, 48x1 +70x2 +1, 2x3 Стандартные ошибки параметров (S): 2 0, 06? 0, 24 t-критерий для параметров 1, 5? 4? Восстановить пропущенные характеристики оценки значимости уравнения.
Задача 2.7.2. Проверить гипотезу H0 о статистической незначимости уравнения регрессии, если индекс корреляции rxy=0, 4, число измерений 10, число параметров 3. (По критерию Фишера).
Задача 2.7.3. По 20-ти предприятиям концерна изучается зависимость прибыли y от выработки продукции на одного работника x1 и индекса цен x2. Полученные данные:
Найдите уравнение множественной регрессии в стандартизированном натуральном масштабе.
Задача 2.7.4. По 20 наблюдениям получены следующие результаты:
a) Оцените коэффициенты линейной регрессии b) Определите стандартные ошибки коэффициентов; c) Вычислите d) Оцените 95%-е доверительные интервалы для коэффициентов b1 и b2; e) Оцените статистическую значимость коэффициентов регрессии и детерминации при уровне значимости a=0, 05; f) Сделайте выводы по модели.
Задача 2.7.5. Для оценки коэффициентов уравнения регрессии
a) Определите эмпирические коэффициенты регрессии; b) Оцените их дисперсию и ковариацию cov(b1, b2) c) С доверительной вероятностью g = 0, 95 оценить значимость коэффициентов регрессии и для значимых коэффициентов определить доверительные интервалы, оценить значимость уравнения регрессии.
Задача 2.7.6 Вычислить эластичность в общем виде и в точке x = 1 для функции: y = 3x2 + 2/x где x1 = x2, x2 = 1/x
Задача 2.7.7. Предполагается, что объем предложения товара у линейно зависит от цены товара Х1 и зарплаты сотрудников X2: у=β 0+β 1X1+β 2X2. Статистические данные собраны за 14 месяцев.
Найти: 1. Оценить по МНК коэффициенты теоретического уравнения множественной регрессии 2. Дайте сравнительную оценку силы связи факторов с результатом с помощью средних (общих) коэффициентов эластичности; 3. Оценить статистическую значимость параметров регрессионной модели с помощью t-критерия; нулевую гипотезу о значимости уравнения и показателей тесноты связи проверьте с помощью F-критерия; 4. Рассчитайте доверительный интервал прогноза для уровня значимости 5% (α = 0, 05);
Автокорреляция
Популярное:
|
Последнее изменение этой страницы: 2016-06-05; Просмотров: 2473; Нарушение авторского права страницы
 -критерия Фишера:
-критерия Фишера: 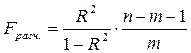 , (2.16)
, (2.16) – коэффициент детерминации;
– коэффициент детерминации; 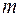 – количество объясняющих переменных X (в линейной регрессии совпадает с числом включенных в модель факторов); n – число наблюдений.
– количество объясняющих переменных X (в линейной регрессии совпадает с числом включенных в модель факторов); n – число наблюдений.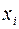 частный
частный 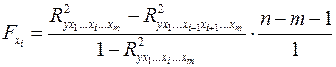 , (2.17)
, (2.17) – коэффициент множественной детерминации для модели с полным набором факторов,
– коэффициент множественной детерминации для модели с полным набором факторов,  – тот же показатель, но без включения в модель фактора
– тот же показатель, но без включения в модель фактора  – число наблюдений,
– число наблюдений, 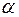 и числе степеней свободы: 1 и
и числе степеней свободы: 1 и  . Если фактическое значение
. Если фактическое значение 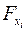 превышает
превышает  , то дополнительное включение фактора
, то дополнительное включение фактора 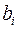 при факторе
при факторе 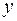 , следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим. ,
,  . (2.17а)
. (2.17а) ;
; 
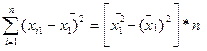 =
= 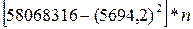 =
= 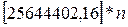
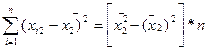 =
= 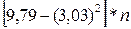 =
= 
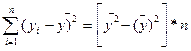 =
=  =
= 
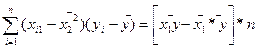 =
= 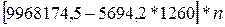 =
= 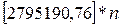
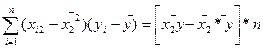 =
=  =
= 
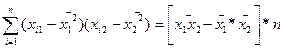 =
=  =
= 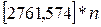
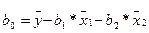
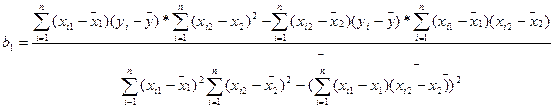
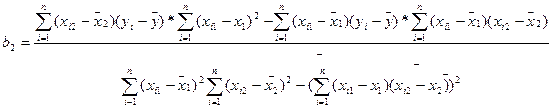
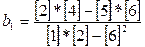 =
= 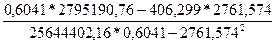 =0, 072;
=0, 072; 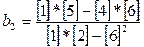 =
=  =343, 293;
=343, 293; 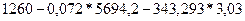 = -190, 63.
= -190, 63.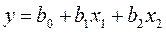 = - 190, 63+0, 072x1+343, 293x2
= - 190, 63+0, 072x1+343, 293x2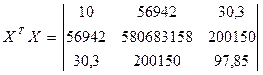
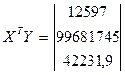
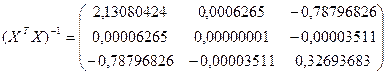

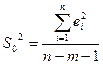 =
= 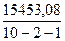 =2207, 582
=2207, 582
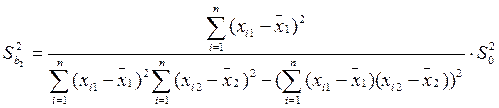
 =
=  =0, 0000169
=0, 0000169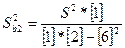 =
= 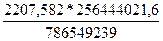 =719, 75304
=719, 75304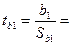
 =17, 5
=17, 5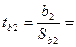
 =12, 7
=12, 7 =
= 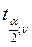 =
= 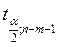 =
= 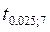 =2, 365
=2, 365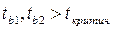 , мы делаем вывод о том, что оба коэффициента сильно значимы для построенной модели.
, мы делаем вывод о том, что оба коэффициента сильно значимы для построенной модели.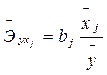



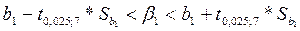


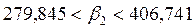
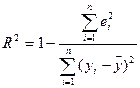 =
=  = 0, 995
= 0, 995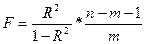 =
= 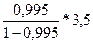 = 696, 5
= 696, 5 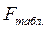 =
= 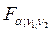 =
= 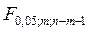 =
= 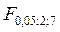 = 19, 4
= 19, 4 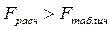 , мы делаем вывод о том, что модель имеет хороший уровень качества.
, мы делаем вывод о том, что модель имеет хороший уровень качества.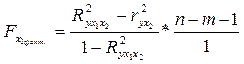 =
= 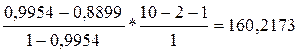
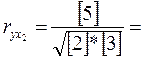
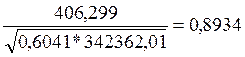
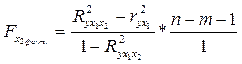 =
= 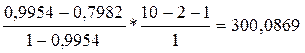
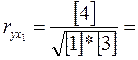

 = 160, 2173;
= 160, 2173;  = 300, 0869;
= 300, 0869;  = 23, 68 (для числа степеней свободы 7 и 1 соответственно и уровня значимости 0, 05)
= 23, 68 (для числа степеней свободы 7 и 1 соответственно и уровня значимости 0, 05)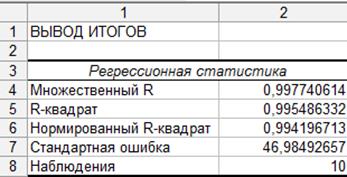

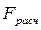 >
> 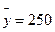 ,
, 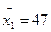 ,
, 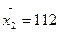 ,
, 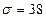 ,
, 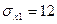 ,
, 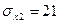 ,
, 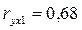 ,
, 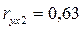 ,
, 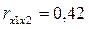
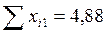 ;
; 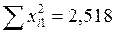 ;
;  ;
;  ;
; 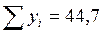 ;
; 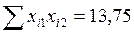 ;
;  ;
; 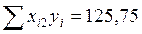 ;
;  ;
; 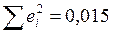 .
.
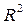 и
и 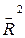 ;
; 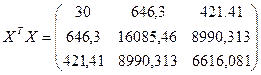 ;
; 
 ;
; 

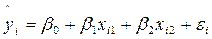 ;
;