
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Тема 5. Классификация и кодирование технико-экономической информации.
Классификация (от латинского classis – разряд и facio – делаю, раскладываю) – система соподчиненных понятий (классов объектов) какой-либо области знания или деятельности человека, часто представляемая в виде различных по форме схем (таблиц) и используемая как средство для установления связей между этими понятиями или классами объектов, а также для точной ориентировки в многообразии понятий или соответствующих объектов (Большая советская энциклопедия. Изд. 3-е, т. 12. – М., 1973. – С. 269). Классификация есть разделение множества объектов на подмножества по их сходству или различию в соответствии с принятыми методами (ГОСТ 6.01.1-87 Единая система классификации и кодирования технико-экономической информации. Основные понятия. – М.: Изд. стандартов. 1987). Классификация фиксирует закономерные связи между классами объектов. Цель классификации – определить такое место объекта в системе, которое указывает на его свойства. Классификация является важнейшим средством создания систем хранения и поиска информации. Функции классификации: 1) научная классификация является инструментом научного познания, прогнозирования и управления, т.к. отражает систему законов, присущих отражаемому в ней фрагменту объективной действительности. Она содействует развитию науки, в ряде случаев предопределяя направления новейших научных исследований и способствуя появлению новых научных открытий (например, Периодическая система химических элементов Д.И. Менделеева); 2) классификация выполняет функцию объективного отражения и фиксации результатов научного познания. Одна из важнейших проблем управления – классификация документов и разработка схем классификации документов.
Методы классификации 1. Иерархический – последовательный метод. Заданное множество объектов последовательно делится на подчиненные подмножества – классификационные группировки. Более старый, традиционный метод. Получаемая на основе этого метода классификационная схема имеет иерархическую структуру. Первоначальный объем классифицируемых объектов детализируется на каждой следующей ступени классификации. Правила построения: 1) деление каждой классификационной группировки производится только по одному основанию; 2) получаемые в результате деления группировки не должны пересекаться, и должны относиться только к одной вышестоящей группировке; 3) деление исходного множества на подмножества должно быть логичным, последовательным, без пропусков и без добавления промежуточного уровня классификации. На верхних ступенях классификации должны быть использованы признаки, к которым в дальнейшем будет обращено наибольшее число запросов; 4) полнота деления: сумма подмножеств деления должна составлять делимое множество, не должна оставаться какая-то часть объектов, не вошедших в состав классификационных группировок. Несоблюдение этих правил затрудняет использование классификатора. Глубина классификации – количество ступеней деления. Емкость классификатора не ограничена и определяется глубиной классификацией и количеством группировок на каждой ступени классификации. Преимущества метода: а) практически не ограничивается глубина классификации информации, что дает возможность более детально анализировать предметы, явления или документы; б) большая информационная емкость метода позволяет его использовать для кодирования большого объема информации; Недостатки метода: а) фиксированность признаков классификации и заранее установленный порядок их следования делают структуру негибкой. Изменение любого признака ведет к перераспределению группировок и необходимости переработки классификатора. Для внесения небольших изменений необходимо предусматривать резервные емкости. По этой причине иерархический метод классификации предпочтителен для объектов со стабильными соподчиненными признаками и для решения стабильного комплекса задач; б) невозможность осуществлять поиск по произвольному сочетанию признаков. 2. Фасетный – параллельный метод. Классифицируемое множество делится на группировки независимо, по различным признакам классификации. При этом методе классификации заранее жесткой классификационной схемы и конечных группировок не создается. Разрабатывается лишь система таблиц (списков) признаков объектов классификации, называемых фасетами. При необходимости создания классификационной группировки для решения конкретной задачи осуществляется выборка необходимых признаков из фасетов и их объединение в определенной последовательности. Последовательность использования фасетов при образовании группировок задается фасетной формулой. Емкость классификатора зависит от числа фасетов и от количества признаков в фасетах. Правила построения: 1) значения признаков из различных фасетов не должны пересекаться; 2) отбираются только существенные фасеты; 3) фасеты должны занимать в классификаторе строго определенное место и иметь определенные идентификационные коды. Преимущество метода: гибкость. Изменения в одном из фасетов не оказывает влияния на остальные. Классификатор приспосабливается к меняющемуся характеру задач. Позволяет включать новые и исключать старые фасеты. Дает возможность поиска по любому сочетанию признаков. В современных классификационных схемах часто используются оба метода классификации. Пример совместного использования иерархического и фасетного методов классификации – Универсальная десятичная классификация, используется во всем мире. Ее основная классификационная таблица построена на основе иерархического метода классификации, а расширение возможностей классификатора достигнуто за счет введения системы таблиц дополнительных признаков, всесторонне характеризующих классифицируемые документы.
Классификация документов Использование документных классификаций способствует решению следующих задач: 1) повышение оперативности работы аппарата управления за счет более точного распределения документопотоков; 2) создание и эффективное использование систем хранения и поиска документной информации; 3) осуществление кодирования документов и документной информации; 4) совершенствование документов и т.д. Разработка классификационных схем документов базируется на теории больших систем. Согласно теории больших систем, любой объект материального мира есть часть какой-то системы объектов этого же материального мира, являющейся, в свою очередь подсистемой системы более высокого уровня. Каждый элемент системы низшего уровня не только несет в себе черты системы более высокого уровня, но и имеет признаки, отличающие его от элементов системы более высокого уровня. Так, совокупность документов РФ имеет определенные родовые черты системы более высокого уровня – мировой документационной системы. С другой стороны, систему документов РФ можно рассматривать как систему более высокого уровня для отраслевой системы документации, а ее, в свою очередь – для системы документации учреждения или организации. Такая иерархия систем документации применительно к унифицированным формам документов (УФД) была закреплена Правилами по стандартизации, утвержденными Госстандартом России в 1993 году. В соответствии с этими Правилами все унифицированные офрмы документов РФ, в зависимости от уровня утверждения и области применения, разделяются на три категории: - общероссийские УФД; - отраслевые УФД; - УФД предприятий. Практическое воплощение классификация документов находит в разрабатываемых различного рода классификационных схемах. Примеры классификационных схем – ОКУД (Общероссийский классификатор управленческой документации), ОК ЕСКД (Общероссийский классификатор изделий и конструкторских документов машиностроения и приборостроения), ОКОЗ (Общеправовой классификатор отраслей законодательства). Во всех этих классификаторах в качестве объектов классификации выступают документы, но документы различного функционального назначения. Классификационными схемами также являются структуры перечней документов с указанием сроков хранения, номенклатур дел и табелей документов. Во всех этих схемах в качестве объектов классификации выступают документы разных видов и категорий, находящиеся на различных стадиях своего «жизненного цикла». Разработка классификаторов представляет собой сложный технологический процесс, включающий целый комплекс взаимосвязанных работ: сбор всего множества документов, подлежащих включению в состав классификатора в качестве объектов классификации, выявление всех характеристик документов, их взаимосвязей и взаимозависимостей, выбор методов классификации и кодирования объектов, структуры классификатора и структуры кода, признаков классификации и т.д. Например, разработка любого общероссийского классификатора технико-экономической и социальной информации (ОК ТЭСИ) осуществляется в соответствии с Правилами по стандартизации, введенными в действие Госстандартом РФ с 01.07.1994. Правила выделяют пять стадий разработки: 1) организация разработки общероссийского классификатора; 2) разработка первой редакции проекта классификатора; 3) разработка окончательной редакции проекта классификатора и представление его для принятия; 4) принятие и государственная регистрация классификатора; 5) издание классификатора. В качестве основания классификации используются определенные признаки классификации. От правильного выбора признаков зависит качество классификатора и его соответствия решаемым задачам. В качестве признаков классификации могут быть выбраны: - материал носителя информации (бумага, магнитная лента, фотопленка и т.д.); - форма изложения содержания документов (связный текст, таблица, анкета); - исторический период (дореволюционные, советские, современные документы); - степень формализации документов и их приспособленность к обработке средствами вычислительной техники (традиционные, машиноориентированные, машиночитаемые); - уровни разработки и утверждения документов; - структура учреждений и организаций или более крупные структурные элементы экономики; - функции учреждений и организаций; - др. Например, номенклатура дел – классификационный справочник документов, создаваемый в любой организации. В качестве признаков классификации в номенклатуре дел используется структура организации или вопросы ее деятельности, а также значимость документов. На верхних ступенях классификации документы распределяются на классификационные группировки в соответствии с утвержденной структурой организации. Наименования структурных группировок соответствуют наименованиям тех структурных подразделений, в которых документы хранятся. На следующей ступени классификации документы распределяются на группировки в соответствии с их видами, значимостью для работы организации, сроками хранения документов. Еще один пример создаваемого на предприятии классификатора – табель форм документов. Для разработки табеля, построенного по функциональному признаку, сначала должен быть создан классификатор функций, выполняемых всеми подразделениями организации. На верхних ступенях классификации документы распределяются по их функциональной принадлежности. На последней ступени классификации табеля документы располагаются по категориям: вначале указываются общероссийские формы документов, затем отраслевые, и в конце – формы документов предприятия. Унифицированные системы документации (УСД) также основаны на функциональном разделении совокупности документов. Наиболее широко используемые из них – организационно-распорядительная, первичная учетная, отчетно-статистическая, учетная и отчетная бухгалтерская, по труду, конструкторской документации и др. На второй ступени классификации класс форм документов разделяется на подклассы, на третьей – на конкретные унифицированные формы документов:
Классификаторы ТЭСИ Для автоматизации обработки информации необходимо было разработать классификаторы не только документов, но и всех видов информации, используемых в управлении. Эти классификаторы стали основой стандартного формализованного языка описания данных. Поэтому в 70-х гг. была начата разработка Общегосударственной автоматизированной системы сбора и обработки информации для целей планирования и управления народным хозяйством (ОГАС). Необходимо было установить единые требования к носителям информации, разработать единый язык формализованного описания данных, закрепить общие методологические принципы обработки данных. Одно из направлений решения этой задачи – разработка Единой системы классификации и кодирования технико-экономической и социальной информации (ЕСКК ТЭСИ). 1971 г. – начало активных работ по созданию ЕСКК ТЭСИ, координаторы – Госстандарт СССР и ВНИИКИ (Всесоюзный научно-исследовательский институт технической информации, классификации и кодирования). Основная цель ЕСКК ТЭСИ – стандартизация информационного обеспечения управления путем создания единого языка формализованного описания данных. 90-е гг. – Государственная программа перехода РФ на международную систему учета и статистики, включающая в себя раздел «Развитие и применение Единой системы классификации и кодирования информации». ЕСКК ТЭСИ – совокупность общероссийских классификаторов технико-экономической и социальной информации, средств их ведения, нормативных и методических документов по их разработке, ведению и применению. Объекты классификации и кодирования в ЕСКК ТЭСИ РФ – технико-экономические и социальные объекты и их свойства, используемые в различных областях хозяйственной деятельности. Задачи ЕСКК ТЭСИ РФ: - классификация и кодирование технико-экономической и социальной информации; - унификация технико-экономических и социальных показателей; - обеспечение однозначности и сопоставимости данных, используемых при описании объектов ТЭСИ; - создание условий для автоматизации процессов обработки информации, включая создание автоматизированных банков данных; - создание распределенного автоматизированного банка общероссийских классификаторов; - создание комплекса взаимоувязанных общероссийских классификаторов и общероссийских форм документов и обеспечение их ведения; - использование в отечественной практике международного и национального зарубежного опыта работ по классификации и кодированию информации; - гармонизация ОК ТЭСИ с международными классификаторами и стандартами по классификации и кодированию информации с учетом отечественной практики. Классификатор ТЭСИ – систематизированный свод наименований и кодов классификационных группировок и/или объектов классификации. Общероссийский классификатор – принятый Госстандартом РФ, входящий в состав ЕСКК ТЭСИ РФ и обязательный для применения на территории всей страны. Общероссийские классификаторы ТЭСИ относятся к нормативным документами по своему статусу соответствуют государственным стандартам РФ. Общероссийские классификаторы обеспечивают сопоставимость данных в различных областях и уровнях хозяйственной деятельности и используются в общероссийских унифицированных формах документов. Отраслевой классификатор ТЭСИ – классификатор, принятый министерством, ведомством РФ и обязательный для применения всеми предприятиями данного министерства, ведомства. Включают информацию, содержащуюся в унифицированных отраслевых формах документов и отсутствующую в общероссийских классификаторах, или представляют собой выборки из общероссийских классификаторов, в которых допускается перекодирование объектов классификации, дополнение отсутствующими в них объектами и признаками классификации. Статус этой категории классификаторов соответствует отраслевым стандартам. Классификатор ТЭСИ предприятия – классификатор, принятый предприятием или объединением предприятий и применяемый только этими хозяйствующими субъектами. Включают информацию, содержащуюся в унифицированных формах документов предприятия и отсутствующую в общероссийских и отраслевых классификаторах, или представляют собой выборки из общероссийских и отраслевых классификаторов, в которых допускается перекодирование объектов классификации, дополнение отсутствующими в них объектами и признаками классификации. Статус этой категории классификаторов соответствует стандартам предприятий. Для кодирования документной информации используется целый комплекс общероссийских классификаторов:
Общероссийский классификатор информации об общероссийских классификаторах (ОКОК) утвержден Госстандартом в декабре 1995 года. В нем закреплена общая классификация классификаторов ТЭСИ. В соответствии с ней все общероссийские классификаторы распределены на восемь групп в зависимости от вида классифицируемой информации: 1) социальная информация; 2) информация по описанию организации экономики; 3) информация о продукции, видах экономической деятельности и оказываемых услугах; 4) информация о природных и трудовых ресурсах; 5) информация о финансово-кредитной сфере; 6) информация об управленческой документации, показателях и единицах измерения; 7) информация о стандартах и технологических процессах; 8) прочие виды технико-экономической и социальной информации.
Методы кодирования Код (индекс) – система условных обозначений, присваиваемых объектам и классификационным группировкам. Кодирование (индексирование) – присвоение кодов (индексов) объектам классификации и классификационным группировкам. Знаки, составляющие индекс или код, называются их алфавитом. Алфавит может включать буквы, цифры, знаки пунктуации и их комбинации. Например, индекс дела в номенклатуре дел состоит из индекса структурного подразделения, в котором хранится дело, и порядкового номера дела внутри раздела. Характеристики кода: а) алфавит – знаки, используемые для образования кода; б) основание кода – число знаков в алфавите кода; в) длина кода. Индекс или код является идентификаторами объекта классификации или классификационной группировки. Его назначение состоит в однозначном обозначении объектов классификации. Это формализованное имя объекта, которое обеспечивает возможность точного определения объекта классификации. Поэтому разработчики классификационных схем стремятся сделать индексы или коды мнемоничными, то есть такими, чтобы по внешнему виду, алфавиту кода пользователь уже мог определить объект и узнать возможно больше информации о характере объекта классификации, для которого использован этот код. Например, в Общероссийском классификаторе стран мира (ОКСМ) буквенный код России RU, код США USA, а в Общероссийском классификаторе валют (ОКВ) код рубля RUR, доллара США USD. Кодирование – это процесс преобразования одного алфавита сообщения в другой алфавит. Кодирование документа – это процесс преобразования документа на естественном языке в язык кода. Основное назначение кодирования состоит в приспособлении информационного сообщения к каналу связи. Поэтому кодирование документов и документной информации направлено на приспособления документам к возможностям его обработки с помощью средств вычислительной техники. С помощью кодирования информации обеспечивается возможность ее представления в компактной форме, ускоряется запись данных в первичных документах и в документах на машинных носителях и последующая обработка этих данных. Кодирование документной информации обеспечивает ее защиту от несанкционированного доступа. Кодирование информации прошло длительный путь развития со времен появления письменности до широкого внедрения современных информационных технологий. Первоначально кодирование документной информации осуществлялось в виде криптографии (тайнописи). Тайнопись представляет собой систему приемов изменения сообщения на естественного языке, используемую с целью сделать это сообщение понятным лишь ограниченному кругу лиц, знающих эту систему. Со времен кардинала Ришелье в тайнописи пользовались цифрами, поэтому тайнопись стали называть также шифрованием. В русских памятниках письменности тайнопись известна с 12-13 веков, а в мировой истории – со времен спартанцев и Юлия Цезаря. Научно-техническая революция сопровождалась появлением различных видов кодов, которые не только защищали информацию от несанкционированного доступа, но и приспосабливали передаваемое сообщение к каналу связи и техническому устройству передачи и обработки информации: код Морзе, телеграфный код, перфоленты, перфокарты, кодирование в вычислительной технике, классификаторы ТЭСИ. Назначение кодов ТЭСИ: 1) однозначное обозначение объектов классификации; 2) передача в сжатом виде определенной информации о характеристиках этих объектов. Требования к методам кодирования ТЭСИ: - метод должен предусматривать использование в качестве алфавита кода десятичных цифр и букв; - обеспечение по возможности минимальной длины кода; - обеспечение достаточного резерва незанятых позиций для кодирования новых объектов без нарушения структуры классификатора; - ориентация на автоматизированную обработку информации. Методы кодирования: - регистрационные (носят самостоятельный характер); - классификационные (основаны на предварительной классификации объектов). Регистрационные методы кодирования I. Порядковый: кодами служат числа натурального ряда. Каждый из объектов классифицируемого множества кодируется путем присвоения ему текущего порядкового номера. Преимущества метода: 1) обеспечивает большую долговечность классификатора при незначительной избыточности кода; 2) простота метода; 3) использование наиболее коротких кодов; 4) обеспечение однозначности определения каждого объекта классификации; 5) простое присвоение кодов новым объектам, появляющимся в процессе классификатора. Недостатки метода: 1) отсутствие в коде конкретной информации о свойствах объекта; 2) сложность машинной обработки информации при получении итогов по группе объектов классификации с одинаковыми признаками.; 3) нельзя разместить вновь появившиеся объекты классификации в необходимом месте классификатора, т.к. резервные коды располагаются в конце ряда. Этот метод очень редко применяется при создании классификаторов, чаще применяется в сочетании с другими методами кодирования. II. Серийно-порядковый: кодами служат числа натурального ряда с закреплением отдельных серий этих чисел с закреплением отдельных серий этих чисел (интервалов натурального ряда) за объектами классификации с одинаковыми признаками. В каждой серии, кроме кодов имеющихся объектов классификации, предусматривается определенное количество кодов для резерва. Резерв кодов располагается в середине или в конце серии. Этот метод целесообразно применять для объектов, имеющих два соподчиненных признака. Классификационные методы кодирования. I. Последовательный: код классификационной группировки и/или объекта классификации образуется с использованием кодов последовательно расположенных подчиненных группировок, полученных при иерархическом методе классификации. Код нижестоящей группировки образуется путем добавления соответствующего количества разрядов к коду вышестоящей группировки. Преимущества: 1) логичность построения кода; 2) большая емкость. Недостатки: 1) ограниченные возможности идентификации объектов; 2) применять код по частям нельзя, т.к. значения последующих разрядов кода зависят от предыдущих; 3) сложно группировать объекты по различным сочетаниям признаков; 4) практически невозможно вносить новые признаки и изменять код без коренной перестройки классификатора. Целесообразно применять этот метод, если набор признаков классификации и их последовательность стабильны в течение длительного времени. II. Параллельный: код классификационной группировки и/или объекта классификации образуется с использованием кодов независимых группировок, .полученных при фасетном методе классификации. Признаки объекта кодируются независимо друг от друга. Для этого метода возможны два варианта записи кодов объектов. 1. Каждый фасет и признак внутри фасета имеют свои коды, которые включатся в состав кода объекта. Такой способ записи удобно применять, если объекты характеризуются неодинаковым набором признаков и различным их числом. При формировании кода какого-либо объекта берутся только необходимые признаки. 2. Для определенных групп объектов выделяется фиксированный набор признаков и устанавливается стабильный порядок их следования, т.е. фасетная формула. В этом случае не надо каждый раз указывать, значение какого признака приведено в определенных разрядах кода объекта. Преимущества метода: 1) гибкость структуры кода, т.к. признаки независимы; 2) можно использовать при решении конкретных задач коды только тех признаков объектов, которые необходимы, т.е. в конкретном случае работа идет с кодами небольшой длины; 3) можно группировать объекты по любому сочетанию признаков; 4) метод хорошо приспособлен для машинной обработки информации; 5) по конкретной кодовой комбинации можно указать набор характеристик, которыми обладает рассматриваемый объект; 6) из небольшого числа признаков можно образовать большое число кодовых комбинаций; 7) при необходимости легко добавить код нового признака. Метод подходит в тех случаях, когда набор признаков классификации часто меняется. Целесообразно использовать его для кодирования однородных объектов, иначе емкость классификатора используется не полностью. В классификационных методах даже при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда идентифицирует конкретный объект, а в регистрационных код идентифицирует объект, но не несет информацию о его свойствах. Поэтому чаще всего классификаторы сочетают обе разновидности методов. Проблемами использования классификаторов являются кодирование и ввод данных. Для автоматизированного кодирования требуются большие объемы памяти трудозатраты, т.к. вначале информация вводится на естественном языке. Для снижения трудозатрат используют штриховые (линейные) коды. Преимущества штриховых кодов: - резкое снижение числа ошибок при вводе информации в виде штриховых кодов по сравнению с вводом информации с клавиатуры на естественном языке; - легкость считывания штриховых кодов электронными оптическими системами по сравнению с буквенно-цифровыми символами; - высокая экономическая эффективность применения систем на основе штриховых кодов вследствие резкого снижения стоимости ввода данных в систему. Штрих-код – комбинация вертикальных полосок разной ширины и пробелов между ними. При этом за базу принимается ширина узкого элемента (полоски) кода. Широкие полоски должны быть кратными им по ширине или находиться с ними в определенных соотношениях. В основе штрихового кода лежит цифровой код. В разных странах используются различные виды штриховых кодов. В каждом из них установлено определенное соотношение между широкими и узкими полосками и между полосками и интервалами между ними. Так, в «Коде 39» каждому знаку цифрового кода соответствует комбинация из девяти элементов (три широких полоски и шесть узких) и из них пять штрихов и четыре интервала между ними. Разработка штриховых кодов осуществляется Международной ассоциаций по нумерации ЕАН (наша страна является членом с 1987 года). Коды ЕАН являются наиболее распространенными в Европе. 1988 г. – Госстандарт СССР утвердил РД 50-666-99 «Методические указания. Присвоение цифровых кодов товарам народного потребления». Эти цифровые коды служат основой для штриховых кодов, наносимых на ярлыки, упаковку и этикетки товаров. Такой цифровой торговый код строится в полном соответствии с кодом ЕАН‑ 13. Он состоит из тринадцати разрядов и имеет следующую структуру: - 2 знака – идентификатор страны-изготовителя товара; - 5 знаков – идентификатор фирмы-изготовителя товара; - 5 знаков – идентификатор товара; - 1 знак – контрольное число. Например, в этом коде США и Канада имеют идентификаторы с 00 до 09, Франция с 30 до 37, Германия с 40 до 43, СНГ 46, Япония 49, Италия с 80 до 83, Корея 88 и т.д. В штриховом коде, построенном на основе ЕАН‑ 13, каждому знаку цифрового кода соответствует комбинация из семи элементов – штрихов и пробелом между ними. Штриховые коды могут быть использованы и в других областях, при этом в качестве цифровых кодов для них могут использоваться коды классификаторов ТЭСИ. Для выявления ошибок в кодах в классификаторах ТЭСИ используется метод контрольных чисел. Он основан на принципе делимости чисел (контроль по модулю). К коду добавляется еще один проверочный знак (контрольное число), связанный с кодом определенной зависимостью. При работе с кодированной информацией специальной программой контроля выполняется проверка этой зависимости по каждому коду. Если зависимость нарушается, машина выдает информацию о наличии ошибки в коде. Наибольшее распространение получил контроль по модулю 11. Контрольным числом является остаток от деления на 11 суммы произведений весов (порядковых номеров разряда в коде слева направо) на значения разрядов кода:
где КЧ – контрольное число по модулю 11, ai – вес i-го разряда кода, xi - значение i-го разряда кода, а значение в квадратных скобках – целая часть числа. По этой методике в качестве весов используются натуральные числа от 1 до 10. Если разрядность кода больше 10, то набор весов повторяется. Остаток может получить значение от 0 до 10. При получении остатка, равного 10, строка весов сдвигается (весовой ряд начинается с 3 до 10, а если разрядность кода больше, то дальше веса идут с 1 до 10) и проводится повторный расчет контрольного числа. Если повторно получается 10, то в качестве контрольного числа используется 0.
ОК ТЭСИ. Структура классификатора, как правило, должна иметь три блока: блок идентификации, включающий коды объектов классификации и классификационных группировок, блок наименований объектов и классификационных группировок на естественном языке и блок дополнительных признаков объектов, включающий наименования и коды дополнительных признаков объектов классификации. Кроме трехблочной структуры, классификатор может иметь двухблочную структуру (блок идентификации и блок наименований), в структуре могут выделяться другие виды блоков, а также разделы. Выбор структуры классификатора определяется характером объекта классификации, типом задач, которые решает классификатор, а также методами классификации и кодирования. Группа 1. Классификаторы социальной информации. Общероссийский классификатор информации по социальной защите населения (ОКИСЗН) предназначен для кодирования социальной информации. Он разработан в 1993 году взамен ранее действовавшего Общесоюзного классификатора информации по социальному обеспечению (ОКИСО). Он предназначен для решения следующих задач: - рациональная организация пенсионного обеспечения граждан; - социальная защита граждан, подвергшихся воздействию радиации вследствие чернобыльской катастрофы; - упрощение процедуры назначения пособий по социальному обеспечению и предоставления льгот инвалидам, ветеранам и другим категориям граждан, нуждающихся в социальной защите; - социальное обслуживание граждан. Объекты классификации ОКИСЗН: - виды пенсий и пособий; - условия назначения пенсий, их размеры; - причины и группы инвалидности; - трудовой стаж и его исчисление; - исчисление пенсии и заработка; - надбавки к пенсиям; - категории граждан, имеющих право на пенсии в связи с воздействием радиации вследствие чернобыльской катастрофы; - другая информация по социальной защите населения. Классификатор построен на основе фасетного метода классификации и параллельного метода кодирования. Количество фасетов и их состав определены действующим законодательством по социальной защите населения. Фасетам присвоены четырехзначные коды. Позиции внутри фасетов закодированы одно, двух или трехзначными кодами на основе порядкового метода кодирования. Структурно классификатор разделен на четыре раздела: 1) пенсионное обеспечение граждан; 2) социальная защита граждан, подвергшихся воздействию радиации вследствие чернобыльской катастрофы; 3) пособия и льготы; 4) социальное обслуживание. Общероссийский классификатор информации о населении (ОКИН) разработан в 1995 году взамен Общесоюзного классификатора информации по кадрам (ОКИК). При разработке ОКИН использован Общероссийский классификатор технико-экономических и социальных показателей (ОКТЭСП). ОКИН предназначен: - для использования при сборе, обработке и анализе демографической, социальной и экономической информации о населении, - решения задач учета, анализа и подготовки кадров предприятиями, учреждениями и организациями всех форм собственности, министерствами и ведомствами. ОКИН построен на основе фасетного метода классификации и параллельного метода кодирования. Количество фасетов и их содержание определяется составом реквизитов, содержащихся в формах документов, входящих в общероссийские УСД, а также в формах документов, предназначенных для переписи населения и других единовременных обследований населения. Каждый фасет состоит из двух блоков: идентификации и наименований. Объекты классификации в фасетах закодированы 1‑ 3 значными кодами на основе серийно-порядкового или порядкового методов кодирования. Сами фасеты закодированы двухзначными цифровыми кодами. В блоке наименований фасетов даны наименования объектов классификации. В отдельных случаях используется сокращенная форма записи, когда в последующих позициях вместо повторяющейся начальной части наименования ставится черточка, а в первой позиции, содержащей эту часть наименования, в конце ставится косая черта. Всего на момент утверждения ОКИН в его состав было включено 30 фасетов: 1) пол; 2) гражданство; 3) национальность; 4) языки народов РФ и иностранные языки; Популярное:
|
Последнее изменение этой страницы: 2016-06-05; Просмотров: 2649; Нарушение авторского права страницы
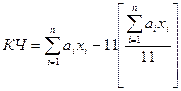 ,
,