
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Доверительные интервалы для параметров нормального распределения
Построим доверительные интервалы для параметров нормального распределения, т. е. когда выборка производится из генеральной совокупности, имеющей нормальное распределение с параметрами аист2. Доверительный интервал для математического ожидания при известной дисперсии Пусть с. в. X ~ iV(a, а); а — известна, доверительная вероятность (надежность) 7 — задана. Пусть х\, х2,..., хп — выборка, полученная в результате проведения п независимых наблюдений за с. в. X. Чтобы подчеркнуть случайный характер величин х\, х2, • •., in, перепишем их в виде Х\, Х2,......, Х„, т. е. под Xi будем понимать значение с. в. X в г-м опыте. Случайные величины Xi, Х2: ..., Хп — независимьг, закон распределения любой из них совпадает с законом распределения с. в. X (т. е. Xi ~ iV(a, сг)). А это значит, что МХг = МХ2 =... = МХп = MX = a, DXi = DX2 =... = DXn = DX. Выборочное среднее n xB — x = n У^ Xj i=i также будет распределено по нормальному закону (примем без доказательства). Параметры распределения X таковы: М(Х) = a, D(X) = о1 = —. Действительно, М(Х) = М (1£ хЛ = I ■ £ МХ; = I • £ MX = MX = а, ^ г=1 ' г—1 г=1 ^ t=l ' г=1 г=1 Таким образом, X ~ N ( a, 1. V \ЛМ Следовательно, пользуясь формулой р{|Х-а|< а = 2Ф0(^)=2ф(1)~1 (формула (2.47)), можно записать 7 - р{\Х -а\< с} = 2Ф0 (Ц^) = 2ФоМ, е ■ у/п где t — —^—. Из последнего равенства находим £ = (7.3) у/П поэтому 7 = р < \Х - а\ < > = 2Ф0(£ ) или I J р (х - * • ^ < а < х +1 • = 2Ф0(*) == 7. I у/п у/пJ В соответствии с определением доверительного интервала получаем, что доверительный интервал для а = MX есть * + *.-£ =), (7.5) \/п у/П, где t определяется из равенства (7.4), т.е. из уравнения
7 2 1 + 7 (или Ф(£ ) = —^—)? ПРИ заданном 7 по таблице функции Лапласа находим аргумент t. Заметим, что из равенства (7.3) следует: с возрастанием объема выборки п число е убывает и, значит, точность оценки увеличивается; увеличение надежности 7 влечет уменьшение точности оценки. Пример 7.5. Произведено 5 независимых наблюдений над с. в. X ~ ~ JV(a, 20). Результаты наблюдений таковы: х\ — —25, х2 ~ 34, #3 — = — 20, = 10, Ж5 = 21. Найти оценку для а = MX, а также построить для него 95%-й доверительный интервал. О Находим сначала хъ: х = ~ • (-25 + 34 - 20 + 10 + 21) = 4, т.е. _ у х = 4. Учитывая, что 7 = 0, 95 и Фо(£ ) = ^ П0ЛУчаем ФоМ — 0, 475. По таблице (см. Приложение) выясняем, что t = 17 = 1, 96. Тогда е = 1 96 ■ 20 = ———— ~ 17, 5 (формула (7.3)). Доверительный интервал для а = v5
= MX (согласно (7.6)) таков: (4 - 17, 5; 4 + 17, 5), т.е. (-13, 5; 21, 5). • Доверительный интервал для математического ожидания при неизвестной дисперсии Пусть с. в. X ~ N(a, а), а — неизвестна, 7 — задана. Найдем такое число е, чтобы выполнялось соотношение р{Х — £ < а < Х + е} = 7 или р{\Х -а\< е} = у. Введем случайную величину ~Х — а Т = s
у/п где S — исправленное среднее квадратическое отклонение с. в. X, вычисленное по выборке: -L- - - Х)\ 1=1 Доказывается, что с. в. Т имеет распределение Стьюдента (см. п. 4.3) с п — 1 степенью свободы. Плотность этого распределения имеет вид: где Г(р) = J up~l - e~udu — гамма-функция; /т(£, п — 1) — четная о
функция. Перейдем в левой части равенства (7.7) от с. в. X к с. в. Т: \Х - а\ £ у/П у/К J или р ||Т| < = 7 или р{|Т| < Ц} = 7, где
е • у/п Ц- s • 2-J fr{t, n — l)dt = 7. о Пользуясь таблицей квантилей распределения Стьюдента (см. приложение 4 на с. 252), находим значение < 7 в зависимости от доверительной вероятности 7 и числа степеней свободы п — 1 (Ц — квантиль уровня 1 — 7).
Определив значение из равенства (7.8), находим значение е: е = t7 - -А-. (7.9) Следовательно, равенство (7.7) принимает вид plx-t7--^< a< X + t7--^\= 7. I Vn V™ J А это значит, что интервал покрывает о — MX с вероятностью 7, т. е. является доверительным интервалом для неизвестного математического ожидания с. в. X. fn Пример 7.6. По условию примера 7.5, считая, что с. в. X ~ iV(a, < j), построить для неизвестного MX = а доверительный интервал. Считать 7 = 0, 95. О Оценку х для MX уже знаем: х = 4. Находим значение S: S2 = 1 ((-25 - 4)2 • 1 + (34 - 4)2 + (-20 - 4)2 + (10 - 4)2 + (21 - 4)2) = = 660, 5; S « 25, 7. По таблице для 7 = 0, 95 и n — 1 = 4 находим ty = 2, 78. 25 7
Следовательно, £ = 2, 78 - тр^ ~ 31, 9. Доверительный интервал таков: (—27, 9; 35, 9). ' • Доверительный интервал для среднего квадратического отклонения нормального распределения Пусть с. в. X ~ N(a, a), о — неизвестно, 7 — задано. Можно показать, что если MX = а известно, то доверительный интервал для среднего квадратического отклонения о имеет вид: {^ ' У^ ' \ Х2 ' Xi ) ' 1 71 где п — объем выборки, s2 — ^ — о)2, а i=l 2 _ 2 2 _ 2 ** — ' _ ^ 1 ~ 7 2 2 'п являются квантилями ^-распределения с п степенями свободы (см. п. 4.3), определяемые по таблице квантилей Ха, н распределения Хп (см- приложение 3 на с. 251). Если а = MX неизвестно, то доверительный интервал для неизвестного сг имеет вид: \ Х2 ' Xi ) ' п где п — объем выборки, S2 = —• — X)2 — исправленное i-1 среднее квадратическое отклонение, квантили 2 __ 2 2 ________________ 2 Xl~Xl+7 1 Х2 — Х1-7 —2——2—* о 1 т 1 — 'У определяются по таблице к ПРИ к=п~1иа= —^— и а = — соответственно. Пример 7.7. Для оценки параметра нормально распределенной случайной величины была сделана выборка объема в 30 единиц и вычислено s = 1, 5. Найти доверительный интервал, покрывающий а с вероятностью 7 = 0, 90. О Имеем п — 30, 7 = 0, 9. По таблице Ха к нах°Дим Xi = X2I + 0, 9 =х2(0, 95; 29) = 17, 7,
—о—: 30—1 xl = х\ — о, 9 = Х2(0, 05; 29) - 42, 6. 2; 30-1 Доверительный интервал имеет вид: /у/30-1-1, 5 л/30 — 1 • 1, 5\ V ' чЯ7Д ) или 1, 238 < СГ < 1, 920. • Скажем несколько слов о доверительном интервале для оценки вероятности успеха при большом числе испытаний Бернулли.
Доверительный интервал, который с надежностью 7 покрывает оцениваемый параметр р при больших значениях п (порядка сотен), имеет вид (рьрг), где P\=P -t- у--------- ^----- и р2=р +t-у--------- п--- где р* = — относительная частота события A; t определяется из равенства 2Фо(£ ) = 7. Для оценки приближенного равенства р р* можно использовать равенство р{|р* — р| < е} = 2Фо ^J^^J (см. п. 4.1). Упражнения 1. Глубина моря измеряется прибором, систематическая ошибка которого равна нулю, а случайные ошибки распределены нормально с а = 15 м. Сколько надо сделать независимых измерений, чтобы определить глубину моря с ошибкой не более 5 м при надежности 7 = 0, 9? 2. По условию примера 6.3 найти точечную оценку и доверительный интервал для среднего роста студентов, считать 7 = 0, 95. 3. Производятся независимые испытания с одинаковой, но с неизвестной вероятностью р появления события а в каждом испытании. Найти доверительный интервал для оценки р с надежностью 0, 95, если в 400 испытаниях события а появилось 80 раз. 7.5. Проверка статистических гипотез Задачи статистической проверки гипотез Одна из часто встречающихся на практике задач, связанных с применением статистических методов, состоит в решении вопроса о том, должно ли на основании данной выборки быть принято или, напротив, отвергнуто некоторое предположение (гипотеза) относительно генеральной совокупности (случайной величины). Например, новое лекарство испытано на определенном числе людей. Можно ли сделать по данным результатам лечения обоснованный вывод о том, что новое лекарство более эффективно, чем применявшиеся ранее методы лечения? Аналогичный вопрос логично задать, говоря о новом правиле поступления в вуз, о новом методе обучения, о пользе быстрой ходьбы, о преимуществах новой модели автомобиля или технологического процесса и т. д. Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез. Задачи статистической проверки гипотез ставятся в следующем виде: относительно некоторой генеральной совокупности высказывается та или иная гипотеза Н. Из этой генеральной совокупности извлекается выборка. Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу Н или принять ее. Следует отметить, что статистическими методами гипотезу можно только опровергнуть или не опровергнуть, но не доказать. Например, для проверки утверждения (гипотеза Н) автора, что «в рукописи нет ошибок», рецензент прочел (изучил) несколько страниц рукописи. Если он обнаружил хотя бы одну ошибку, то гипотеза Н отвергается, в противном случае — не отвергается, говорят, что «результат проверки с гипотезой согласуется». Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Статистическая гипотеза. Статистический критерий Под статистической гипотезой (или просто гипотезой) понимают всякое высказывание (предположение) о генеральной совокупности, проверяемое по выборке. Статистические гипотезы делятся на гипотезы о параметрах распределения известного вида (это так называемые параметрические гипотезы) и гипотезы о виде неизвестного распределения {weпараметрические гипотезы). Одну из гипотез выделяют в качестве основной (или нулевой) и обозначают Hq, а другую, являющуюся логическим отрицанием Hq, т. е. противоположную Hq — в качестве конкурирующей (или альтернативной) гипотезы и обозначают Н\. Гипотезу, однозначно фиксирующую распределение наблюдений, называют простой (в ней идет речь об одном значении параметра), в противном случае — сложной. Например, гипотеза Hq, состоящая в том что математическое ожидание с.в. X равно ао, т.е. MX ~ ао, является простой. В качестве альтернативной гипотезы можно рассматривать одну из следующих гипотез: H\i MX > ао (сложная гипотеза), Н\\ MX < ао (сложная), Н\: MX ф ао (сложная) или Н\\ MX = ai (простая гипотеза). Имея две гипотезы Hq и Нi, надо на основе выборки Xi,..., Хп принять либо основную гипотезу #о, либо конкурирующую Н\. Правило, по которому принимается решение принять или отклонить гипотезу Hq (соответственно, отклонить или принять Hi), называется статистическим критерием (или просто критерием) проверки гипотезы Щ. Проверку гипотез осуществляют на основании результатов выборки Xi, Х2,..., Хп, из которых формируют функцию выборки Тп = = Т(Х 1, ^2,... Дп)) называемой статистикой критерия. Основной принцип проверки гипотез состоит в следующем. Множество возможных значений статистики критерия Тп разбивается на два непересекающихся подмножества: критическую область S, т. е. область отклонения гипотезы Hq и область S принятия этой гипотезы. Если фактически наблюдаемое значение статистики критерия (т. е. значение критерия, вычисленное по выборке: Тнабл — Т{х\, х2,..., хп)) попадает в критическую область S, то основная гипотеза Hq отклоняется и принимается альтернативная гипотеза Н\ \ если же Тнабл попадает в S, то принимается Но, а Hi отклоняется. При проверке гипотезы может быть принято неправильное решение, т. е. могут быть допущены ошибки двух родов: Ошибка первого рода состоит в том, что отвергается нулевая гипотеза Hq, когда на самом деле она верна. Ошибка второго рода состоит в том, что отвергается альтернативная гипотеза Hi, когда она на самом деле верна. Рассматриваемые случаи наглядно иллюстрирует следующая таблица.
Вероятность ошибки 1-го рода (обозначается через а) называется уровнем значимости критерия. Очевидно, а — p(H\\Hq). Чем меньше а, тем меньше вероятность отклонить верную гипотезу. Допустимую ошибку 1-го рода обычно задают заранее. В одних случаях считается возможным пренебречь событиями, вероятность которых меньше 0, 05 (а = 0, 05 означает, что в среднем в 5 случаях из 100 испытаний верная гипотеза будет отвергнута), в других случаях, когда речь идет, например, о разрушении сооружений, гибели судна и т.п., нельзя пренебречь обстоятельствами, которые могут появиться с вероятностью, равной 0, 001. Обычно для а используются стандартные значения: а — 0, 05; а = 0, 01; 0, 005; 0, 001. Вероятность ошибки 2-го рода обозначается через /3, т. е. /3 = = р(Яо|Я0. Величину 1 — /3, т. е. вероятность недопущения ошибки 2-го рода (отвергнуть неверную гипотезу Hq, принять верную Hi), называется мощностью критерия. Очевидно, 1 — /3 = p(i? i|jffi) — p{{xi, x2,..., хп Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше, что, конечно, желательно (как и уменьшение а). Последствия ошибок 1-го, 2-го рода могут быть совершенно различными: в одних случаях надо минимизировать а, в другом — tв. Так, применительно к радиолокации говорят, что а — вероятность пропуска сигнала, /3 — вероятность ложной тревоги; применительно к производству, к торговле можно сказать, что а — риск поставщика (т. е. забраковка по выборке всей партии изделий, удовлетворяющих стандарту), /3 — риск потребителя (т.е. прием по выборке всей партии изделий, не удовлетворяющей стандарту); применительно к судебной системе, ошибка 1-го рода приводит к оправданию виновного, ошибка 2-го рода — осуждению невиновного. Отметим, что одновременное уменьшение ошибок 1-го и 2-го рода возможно лишь при увеличении объема выборок. Поэтому обычно при заданном уровне значимости а отыскивается критерий с наибольшей мощностью. Методика проверки гипотез сводится к следующему: 1. Располагая выборкой Х\, Х2, • • •, Хп, формируют нулевую гипотезу Но и альтернативную Н\. 2. В каждом конкретном случае подбирают статистику критерия Тп — — Т(Х 1, ^2,..., Хп), обычно из перечисленных ниже: U — нормальное распределение, х2 — распределение хи-квадрат (Пирсона), t — распределение Стьюдента, F — распределение Фишера-Снедекора. 3. По статистике критерия Тп и уровню значимости а определяют критическую область S (и S). Для ее отыскания достаточно найти критическую точку tKp, т.е. границу (или квантиль), отделяющую область S от S. Границы областей определяются, соответственно, из соотношений: Р(Тп ~> ^кр) — ск, для правосторонней критической области S (рис. 63); Р{Тп < tKр) = ск, для левосторонней критической области S (рис. 64); Р(Тп < = Р{Тп > tjp) = для двусторонней критической области S (рис. 65).
Для каждого критерия имеются соответствующие таблицы, по которым и находят критическую точку, удовлетворяющую приведенным выше соотношениям. 4. Для полученной реализации выборки х = (xi, x2,..., хп) подсчитывают значение критерия, т. е. Тна бл = Т(х i, ж2, ..., xn) = t. 5. Если t £ S (например, t > tKp для правосторонней области 5), то нулевую гипотезу Щ отвергают; если же t £ S (t < £ кр), то нет оснований, чтобы отвергнуть гипотезу Hq.
Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 1001; Нарушение авторского права страницы
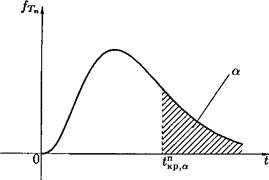 Рис. 63
Рис. 63
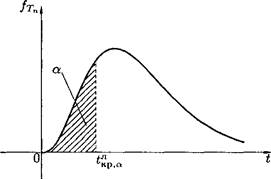 Рис. 64
Рис. 64
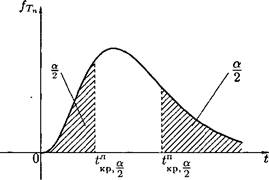 Рис. 65
Рис. 65