
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Усиленный закон больших чисел
Пусть есть бесконечная последовательность независимых одинаково распределённых случайных величин
Тогда Теорема Чебышева: Если для независимых СВ Если дисперсии (
Если Следствие: Если независимые случайные величины X1, X2, ..., Xn имеют одинаковые математические ожидания, а дисперсии ограничены одной и той же постоянной, то
Теорема Бернулли: Относительная частота появления события в n независимых испытаниях, в каждом из которых оно происходит с одной и той же вероятностью P, при увеличении n сходится по вероятности к вероятности появления этого события в 1 испытании.
Из этой теоремы следует, что при большом числе испытаний случайная величина
6. Центральная предельная теорема для независимых одинаково распределенных случайных величин. Центральная предельная теорема представляет собой группу теорем, устанавливающих условия, при которых возникает нормальный закон распределения. Одной из основных теорем является теорема Ляпунова. Теорема. Если
неограниченно приближается к нормальному. Доказательство. Проведем доказательство для случая непрерывных случайных величин Характеристическая функция величины
Следовательно, характеристическая функция случайной величины
Исследуем более подробно функцию
где Найдем величины
Продифференцируем (1.6.2) по
Полагая в (1.6.6)
Очевидно, не ограничивая общности, можно положить
Продифференцируем (13.8.6) еще раз:
отсюда
При
Подставляя в (1.6.4)
Обратимся к случайной величине
Эта величина удобна тем, что ее дисперсия не зависит от Вместо того чтобы доказывать, что закон распределения величины Найдем характеристическую функцию величины
где Из формул (1.6.12) и (13.8.3) получим
или, пользуясь формулой (1.6.10),
Прологарифмируем выражение (1.6.14):
Введем обозначение
Тогда
Будем неограниченно увеличивать
Тогда получим
По определению функция
и
откуда
Это есть не что иное, как характеристическая функция нормального закона с параметрами Таким образом, доказано, что при увеличении Мы доказали центральную предельную теорему для частного, но важного случая одинаково распределенных слагаемых. Однако в достаточно широком классе условий она справедлива и для неодинаково распределенных слагаемых. Например, А. М. Ляпунов доказал центральную предельную теорему для следующих условий:
где
Наиболее общим (необходимым и достаточным) условием справедливости центральной предельной теоремы является условие Линдеберга: при любом
где
7. Основные понятия математической статистики: случайная выборка из распределения, выборочное пространство, вариационный ряд, эмпирическая функция распределения, выборочное среднее, выборочные дисперсии, выборочные моменты. Точечные оценки известных значений параметров распределений: несмещенные оценки, состоятельные оценки. Примеры Допустим, что опыт состоял из n повторных измерений некоторой неизвестной величины и в результате получены значения Пространство элементарных событий называется выборочным пространством или пространством исходов. Вариационным рядом называется выборка, полученная в результате расположения значений исходной выборки Пусть задана случайная выборка Замечание: при этом эмпирическая функция непрерывна справа. Математическое ожидание эмпирической функции распределения E[ Дисперсия эмпирического распределения D= Вы́ борочное (эмпири́ ческое) сре́ днее — это приближение теоретического среднего распределения, основанное на выборке из него. Пусть Выборочная дисперсия — это оценка теоретической дисперсии распределения на основе выборки. Различают выборочную дисперсию и несмещённую, или исправленную, выборочные дисперсии. Пусть Несмещённая (исправленная) дисперсия — это случайная величина Выборочные моменты в математической статистике — это оценка теоретических моментов распределения на основе выборки. Пусть Центральный выборочный момент порядка k — это случайная величина Статистической оценкой Качество оценки определяют, проверяя, обладает ли она свойствами несмещенности, состоятельности, эффективности. Несмещенной называют статистическую оценку При рассмотрении выборок большого объема (n велико! ) к статистическим оценкам предъявляется требование состоятельности. Состоятельной называют статистическую оценку, которая при n→ ∞ стремится по вероятности к оцениваемому параметру: Пример 1: Рассмотрим оценку математического ожидания на основе теоремы Чебышева В качестве состоятельной оценки математического ожидания может быть использовано среднее арифметическое значение выборки, которое называется выборочным средним: Тогда Пример 2: Рассмотрим оценку дисперсии D(x). D(x)=M(|𝑥 − В качестве состоятельной оценки D может быть использовано среднее арифметическое квадратов отклонений выборочных значений от выборочной средней. Такая оценка называется выборочной дисперсией Выборочным средним квадратическим отклонением(стандартом) называют квадратный корень из выборочной дисперсии: Обычным эмпирическим моментом порядка k называют среднее значение k-x степеней разностей ( n = å Начальным эмпирическим моментом порядка k называют обычный момент порядка k при С = 0 Центральным эмпирическим моментом порядка k называют обычный момент порядка k при
8. Задача проверки статистических гипотез. Основная и альтернативная, простая и сложная гипотезы. Статистические критерии. Ошибки 1-oгo и 2-ого родов при проверки гипотез. Функция мощности критерия. Наиболее мощный и равномерно наиболее мощный критерии. Лемма Неймана-Пирсона. Проверка простых гипотез о параметрах биноминального, полиноминального и нормального распределений. Задачи статистической проверки гипотез ставятся в следующем виде: относительно некоторой генеральной совокупности высказывается та или иная гипотеза Например, статистическими являются гипотезы: 1) генеральная совокупность распределена по закону Пуассона; 2) дисперсии двух нормальных совокупностей равны между собой. В первой гипотезе сделано предположение о виде неизвестного распределений, во второй — о параметрах двух известных распределений. Гипотеза «на Марсе есть жизнь» не является статистической, поскольку в ней не идет речь ни о виде, ни о параметрах распределения. Наряду с выдвинутой гипотезой рассматривают и противоречащую ей гипотезу. Если выдвинутая гипотеза будет отвергнута, то имеет место противоречащая гипотеза. По этой причине эти гипотезы целесообразно различать. Нулевой (основной) называют выдвинутую гипотезу Конкурирующей (альтернативной) - называют гипотезу Различают гипотезы, которые содержат только одно и более одного предположений. Простой называют гипотезу, содержащую только одно предположение. Например, если λ - параметр показательного распределения, то гипотеза Сложной называют гипотезу, которая состоит, из конечного или бесконечного числа простых гипотез. Например, сложная гипотеза Статистическим критерием называют случайную величину К, которая служит для проверки нулевой гипотезы. Например, если проверяют гипотезу о равенстве дисперсий двух нормальных генеральных совокупностей, то в качестве критерия К принимают отношение исправленных выборочных дисперсий: F= Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Поскольку проверку проводят статистическими методами, то ее называют статистической. В итоге статистической проверки гипотезы в двух случаях может быть принято неправильное решение, т.е. могут быть допущены ошибки двух родов. Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка второго рода состоит в том, что будет принята неправильная гипотеза. Подчеркнем, что последствия этих ошибок могут оказаться весьма различными. Например, если отвергнуто правильное решение «продолжать строительство жилого дома», то эта ошибка первого рода повлечет материальный ущерб; если же принято неправильное решение «продолжать строительство», несмотря на опасность обвала стройки, то эта ошибка второго рода может повлечь гибель людей. Можно привести примеры, когда ошибка первого рода влечет более тяжелые последствия, чем ошибка второго рода. Правильное решение может быть принято также в двух случаях: a. гипотеза принимается, причем в действительности она правильная; b. гипотеза отвергается, причем и в действительности она неверна. Вероятность допустить ошибку 1 рода принято обозначать через α; ее называют уровнем значимости. Наиболее часто уровень значимости принимают равным 0.05 или 0.01. Если, например, принят уровень значимости, равный 0.05, то это означает, что в пяти случаях из ста имеется риск допустить ошибку 1 рода (отвергнуть правильную гипотезу). Критической областью называют совокупность значений критерия, при которых нулевую гипотезу отвергают. Мощностью критерия называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза. Другими словами, мощность критерия есть вероятность того, что нулевая гипотеза будет отвергнута, если верна конкурирующая гипотеза. Величина риска, связанная с отклонением верной гипотезой, обычно соотносится с функцией потерь типа 1-0: Потери считаются равными 1, если принята гипотеза Функция мощности критерия указывает, как часто мы отклоняем нулевую гипотезу, когда q истинное значение параметра, и хорошим следует считать тот критерий, у которого функция m(q) принимает близкие к 0 значения в области Критерий обладающий наименьшей вероятностью ошибки второго рода, при заданном уровне ошибки первого рода, называется наиболее мощным критерием. Равномерно наиболее мощным критерием называется такой критерий φ уровня a, который равномерно по всем q Î q Î (Примечание: Функция 0 a(q), q Î Q называется вероятностью ошибки первого рода – она указывает относительную частоту отклонения гипотезы Лемма Неймана-Пирсона. Рассмотрим вероятностную модель состоящую из двух распределений Статистика L называется статистикой отношения правдоподобия, а критерий j* - критерием отношения правдоподобия или критерием Неймана-Пирсона. Критерий j* отвергает нулевую гипотезу, если правдоподобие альтернативы функции Свойства критерия Пирсона: Критерий отношения правдоподобия j* является наиболее мощным критерием в классе всех критериев проверки простой гипотезы при простой альтернативе, размер которых не превосходит размера критерия j*. Если критерий j* имеет размер a, то он обладает наибольшей мощностью в классе всех критериев уровня a. Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Общая схема проверки гипотез: 1. Формулируются гипотезы Но и 2. Выбирается уровень значимости критерия a. 3. По выборочным данным вычисляется значение некоторой случайной величины K, называемой статистикой критерия, который имеет известное стандартное распределение (нормальное, Т-распределение Стьюдента и т.п.) 4. Вычисляется критическая область и область принятия гипотезы. То есть находится критическое (граничное) значение критерия при уровне значимости a, взятым из соответствующих таблиц. 5. Найденное значение a) Если вычисленное по выборке значение критерия (В этом случае наблюдаемое по экспериментальным данным различие генеральных совокупностей можно объяснить только случайностью выборки. Однако принятие гипотезы b) Если вычисленное значение критерия (В этом случае наблюдаемое различие генеральных совокупностей уже нельзя объяснить только случайностями и говорят, что наблюдаемое различие значимо (статистически значимо) на уровне значимости a.) Критерии значимости подразделяются на три типа: 1. Критерии значимости, которые служат для проверки гипотез о параметрах распределений генеральной совокупности (чаще всего нормального распределения). Эти критерии называются параметрическими. Параметрические критерии предполагают, что выборка порождена распределением из заданного параметрического семейства. В частности, существует много критериев, 39 предназначенных для анализа выборок из нормального распределения. Преимущество этих критериев в том, что они более мощные. Если выборка действительно удовлетворяет дополнительным предположениям, то параметрические критерии дают более точные результаты. Однако если выборка им не удовлетворяет, то вероятность ошибок (как I, так и II рода) может резко возрасти. Прежде чем применять такие критерии, необходимо убедиться, что выборка удовлетворяет дополнительным предположениям. Гипотезы о виде распределения проверяются с помощью критериев согласия. 2. Критерии, которые для проверки гипотез не используют предположений о распределении генеральной совокупности. Эти критерии не требуют знания параметров распределений, поэтому называются непараметрическими. 3. Особую группу критериев составляют критерии согласия, служащие для проверки гипотез о согласии распределения генеральной совокупности, из которой получена выборка, с ранее принятой теоретической моделью (чаще всего нормальным распределением).
9. Критерии согласия. Критерий согласия Пирсона (критерий χ 2). Теорема Пирсона о предельном распределении χ 2-статистики (без доказательства) Во многих случаях закон распределения изучаемой случайно величины неизвестен, но есть основания предположить, что он имеет вполне определенный вид: нормальный, биномиальный или какой-либо другой. Пусть необходимо проверить гипотезу Для проверки гипотезы о распределении случайной величины X проведем выборку, которую оформим в виде статистического ряда: Критерием согласия называют статистический критерий проверки гипотезы о предполагаемом законе неизвестного распределения. (Он используется для проверки согласия предполагаемого вида распределения с опытными данными на основании выборки.) Существуют различные критерии согласия: Пирсона, Колмогорова, Фишера, Смирнова и др. Критерий согласия Пирсона — наиболее часто употребляемый критерий для проверки простой гипотезы о законе распределения. Критерий Для проверки гипотезы Разбивают всю область значений с.в. Xна m интервалов Δ 1, Δ 2,..., Δ m и подсчитывают вероятности Тогда теоретическое число значений с. в. X, попавших в интервал Если эмпирические частоты ( В качестве меры расхождения между Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1331; Нарушение авторского права страницы
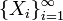 , определённых на одном вероятностном пространстве
, определённых на одном вероятностном пространстве  . Пусть
. Пусть  . Обозначим Sn выборочное среднее первых n членов:
. Обозначим Sn выборочное среднее первых n членов:  .
. почти наверное.
почти наверное. дисперсии
дисперсии 
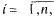 то для любого числа
то для любого числа  > 0 справедливо
> 0 справедливо 
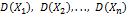 ) n независимых случайных величин X1, X2, ..., Xn ограничены одной и той же величиной (не превышающего значения С), то при неограниченном увеличении числа n среднее арифметическое случайных величин сходится по вероятности к среднему арифметическому их математических ожиданий.
) n независимых случайных величин X1, X2, ..., Xn ограничены одной и той же величиной (не превышающего значения С), то при неограниченном увеличении числа n среднее арифметическое случайных величин сходится по вероятности к среднему арифметическому их математических ожиданий.
 , а
, а  , то
, то 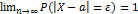 . Выполнение неравенства
. Выполнение неравенства  , где
, где 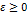 - почти достоверное событие. Существует ненулевая вероятность того, что неравенство выполняться не будет.
- почти достоверное событие. Существует ненулевая вероятность того, что неравенство выполняться не будет. ,
,  . В соответствии с теоремой Чебышева сумма большого числа случайных величин мало отличается от неслучайных величин, то есть перестает быть случайной.
. В соответствии с теоремой Чебышева сумма большого числа случайных величин мало отличается от неслучайных величин, то есть перестает быть случайной. , где m - число появления события в n испытаниях.
, где m - число появления события в n испытаниях. практически перестает быть случайной.
практически перестает быть случайной. - независимые случайные величины, имеющие один и тот же закон распределения с математическим ожиданием
- независимые случайные величины, имеющие один и тот же закон распределения с математическим ожиданием  и дисперсией
и дисперсией  , то при неограниченном увеличении
, то при неограниченном увеличении  закон распределения суммы
закон распределения суммы (1.6.1)
(1.6.1) (для прерывных оно будет аналогичным).
(для прерывных оно будет аналогичным).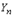 представляет собой произведение характеристических функций слагаемых. Случайные величины
представляет собой произведение характеристических функций слагаемых. Случайные величины 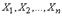 имеют один и тот же закон распределения с плотностью
имеют один и тот же закон распределения с плотностью  и, следовательно, одну и ту же характеристическую функцию
и, следовательно, одну и ту же характеристическую функцию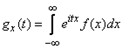 . (1.6.2)
. (1.6.2) будет
будет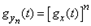 . (1.6.3)
. (1.6.3) . Представим ее в окрестности точки
. Представим ее в окрестности точки  по формуле Маклорена с тремя членами:
по формуле Маклорена с тремя членами: 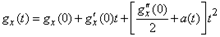 , (1.6.4)
, (1.6.4) при
при  .
.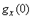 ,
,  ,
,  . Полагая в формуле (1.6.2)
. Полагая в формуле (1.6.2)  имеем:
имеем:  . (1.6.5)
. (1.6.5) :
:  . (1.6.6)
. (1.6.6)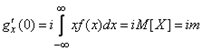 . (1.6.7)
. (1.6.7) (для этого достаточно перенести начало отсчета в точку
(для этого достаточно перенести начало отсчета в точку 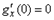 .
. ,
,  . (1.6.8)
. (1.6.8) интеграл в выражении (1.6.8) есть не что иное, как дисперсия величины
интеграл в выражении (1.6.8) есть не что иное, как дисперсия величины  с плотностью
с плотностью  , следовательно
, следовательно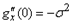 . (1.6.9)
. (1.6.9)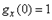 ,
,  , получим:
, получим: 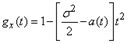 . (1.6.10)
. (1.6.10) . Мы хотим доказать, что ее закон распределения при увеличении
. Мы хотим доказать, что ее закон распределения при увеличении  к другой («нормированной») случайной величине
к другой («нормированной») случайной величине . (1.6.11)
. (1.6.11) как линейную функцию независимых случайных величин
как линейную функцию независимых случайных величин  , каждая из которых имеет дисперсию
, каждая из которых имеет дисперсию 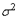 . Если мы докажем, что закон распределения величины
. Если мы докажем, что закон распределения величины 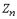 приближается к нормальному, то, очевидно, это будет справедливо и для величины
приближается к нормальному, то, очевидно, это будет справедливо и для величины  при увеличении
при увеличении  , (1.6.12)
, (1.6.12) - характеристическая функция случайной величины
- характеристическая функция случайной величины  .
. (1.6.13)
(1.6.13) . (1.6.14)
. (1.6.14)
 .
.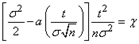 . (1.6.15)
. (1.6.15) . (1.6.16)
. (1.6.16) , согласно формуле (1.6.15), стремится к нулю. При значительном
, согласно формуле (1.6.15), стремится к нулю. При значительном  в ряд и ограничимся одним членом разложения (остальные при
в ряд и ограничимся одним членом разложения (остальные при  станут пренебрежимо малыми):
станут пренебрежимо малыми):  .
.
 .
.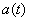 стремится к нулю при
стремится к нулю при  ; следовательно,
; следовательно, 
 ,
, 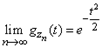 . (1.6.17)
. (1.6.17) (см. пример 2,
(см. пример 2,  13.7).
13.7).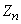 неограниченно приближается к характеристической функции нормального закона; отсюда заключаем что и закон распределения величины
неограниченно приближается к характеристической функции нормального закона; отсюда заключаем что и закон распределения величины  ) неограниченно приближается к нормальному закону. Теорема доказана.
) неограниченно приближается к нормальному закону. Теорема доказана. , (1.6.18)
, (1.6.18)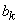 - третий абсолютный центральный момент величины
- третий абсолютный центральный момент величины 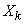 :
: 
 .
. - дисперсия величины
- дисперсия величины  .
.
 ,
,  - математическое ожидание,
- математическое ожидание, 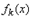 - плотность распределения случайной величины
- плотность распределения случайной величины  ,
,  .
.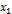 ….
….  . Эти значения естественно считать реализацией набора из n независимых одинаково распределенных случайных величин с неизвестной функцией распределения F(x). Величина x=(
. Эти значения естественно считать реализацией набора из n независимых одинаково распределенных случайных величин с неизвестной функцией распределения F(x). Величина x=(  наблюдений
наблюдений  Построим по выборке ступенчатую функцию
Построим по выборке ступенчатую функцию  , возрастающую скачками величины
, возрастающую скачками величины  в точках
в точках  . Построенная функция называется эмпирической функцией распределения. Для задания значений в точках разрыва формально определим её так:
. Построенная функция называется эмпирической функцией распределения. Для задания значений в точках разрыва формально определим её так:  .
.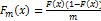 .
. ). Тогда её выборочным средним называется случайная величина
). Тогда её выборочным средним называется случайная величина  .
. , где символ
, где символ  обозначает выборочное среднее.
обозначает выборочное среднее. .
. .
. , где символ
, где символ  параметра 𝜃 теоретического распределения называют его приближенное значение, зависящее от данных выбора. Очевидно, что оценка 𝜃 есть значение некоторой функции результатов наблюдений над случайной величиной, т. е. 𝜃 ̅ = 𝜃 ̅ (𝑋 1, 𝑋 2, …, 𝑋 𝑛 ). Точечной называют оценку, которая определяется одним числом. При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, т. е. приводить к грубым ошибкам.
параметра 𝜃 теоретического распределения называют его приближенное значение, зависящее от данных выбора. Очевидно, что оценка 𝜃 есть значение некоторой функции результатов наблюдений над случайной величиной, т. е. 𝜃 ̅ = 𝜃 ̅ (𝑋 1, 𝑋 2, …, 𝑋 𝑛 ). Точечной называют оценку, которая определяется одним числом. При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, т. е. приводить к грубым ошибкам. , математическое ожидание которой равно оцениваемому параметру q при любом объеме выборки, т. е. M(
, математическое ожидание которой равно оцениваемому параметру q при любом объеме выборки, т. е. M( 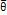 )= q.
)= q.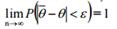 . Если дисперсия несмещенной оценки при n→ ∞ стремится к нулю, то такая оценка оказывается и состоятельной.
. Если дисперсия несмещенной оценки при n→ ∞ стремится к нулю, то такая оценка оказывается и состоятельной.
 Найдем математическое ожидание этой оценки:
Найдем математическое ожидание этой оценки: 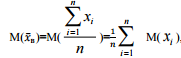 , т.к.
, т.к.  имеет одинаковый закон распределения, то
имеет одинаковый закон распределения, то  .
. . Следовательно, оценка является несмещенной. Выборочная средняя является эффективной оценкой для нормально-распределенной случайной величины.
. Следовательно, оценка является несмещенной. Выборочная средняя является эффективной оценкой для нормально-распределенной случайной величины.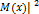 ).
).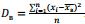 . В качестве несмещенной оценки берут исправленную выборочную дисперсию:
. В качестве несмещенной оценки берут исправленную выборочную дисперсию: 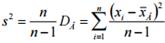 .
.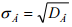 . На практике оценка чаще всего осуществляется либо методом моментов, либо методом максимального правдоподобия.
. На практике оценка чаще всего осуществляется либо методом моментов, либо методом максимального правдоподобия.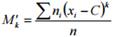 где
где 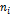 —частота варианты,
—частота варианты,  . В частности,
. В частности,  , т. е. начальный эмпирический момент первого порядка равен выборочной средней.
, т. е. начальный эмпирический момент первого порядка равен выборочной средней.
 . В частности,
. В частности, 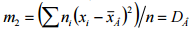 , т. е. центральный эмпирический момент второго порядка равен выборочной дисперсии.
, т. е. центральный эмпирический момент второго порядка равен выборочной дисперсии. . Из этой генеральной совокупности извлекается выборка. Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу
. Из этой генеральной совокупности извлекается выборка. Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу 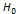 .
.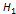 , которая противоречит нулевой. Например, если нулевая гипотеза состоит в предположении, что математическое ожидание анормального распределения равно 10, то конкурирующая гипотеза, в частности, может состоять в предположении, что а ≠ 10. Коротко это записывают так:
, которая противоречит нулевой. Например, если нулевая гипотеза состоит в предположении, что математическое ожидание анормального распределения равно 10, то конкурирующая гипотеза, в частности, может состоять в предположении, что а ≠ 10. Коротко это записывают так:  .: а= 10;
.: а= 10;  : а ≠ 10.
: а ≠ 10. : λ =
: λ = 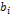 , где
, где  . Эта величина случайная, потому что в различных опытах дисперсии принимают различные, наперед неизвестные значения, и распределена по закону Фишера—Снедекора.
. Эта величина случайная, потому что в различных опытах дисперсии принимают различные, наперед неизвестные значения, и распределена по закону Фишера—Снедекора.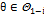 , i=0, 1; Если же принято
, i=0, 1; Если же принято 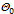 и близкие к 1 в области
и близкие к 1 в области  . В связи с этим вводятся две компоненты функции риска: a(q ) = m(q) при q Î
. В связи с этим вводятся две компоненты функции риска: a(q ) = m(q) при q Î 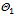 трактуется как вероятность отклонения гипотезы
трактуется как вероятность отклонения гипотезы 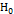 , когда она в действительности верна ( q Î
, когда она в действительности верна ( q Î 
 с общим носителем и функциями плотности
с общим носителем и функциями плотности  (x) и
(x) и  (x), xÎ X. По выборке
(x), xÎ X. По выборке  проверяется простая гипотеза
проверяется простая гипотеза 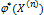 как индикаторную функцию критической области.
как индикаторную функцию критической области. 
 в С раз превосходит правдоподобие нулевой гипотезы
в С раз превосходит правдоподобие нулевой гипотезы  .
.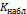 критерия сравнивается с
критерия сравнивается с  и по результатам сравнения делается вывод: принять гипотезу или отвергнуть.
и по результатам сравнения делается вывод: принять гипотезу или отвергнуть. о том, что с.в. X подчиняется определенному закону распределения, заданному функцией распределения
о том, что с.в. X подчиняется определенному закону распределения, заданному функцией распределения  (X), т.е.
(X), т.е.  (x)=
(x)=  (X). Под альтернативной гипотезой H1будем понимать в данном случае то, что просто не выполнена основная (т.е.
(X). Под альтернативной гипотезой H1будем понимать в данном случае то, что просто не выполнена основная (т.е.  :
:  где
где  — объем выборки. Требуется сделать заключение: согласуются ли результаты наблюдений с высказанным предположением. Для этого используем специально подобранную величину — критерий согласия.
— объем выборки. Требуется сделать заключение: согласуются ли результаты наблюдений с высказанным предположением. Для этого используем специально подобранную величину — критерий согласия. Пирсона.
Пирсона.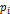 (i= 1, 2, ..., m) попадания с.в. X(т.е. наблюдения) в интервал
(i= 1, 2, ..., m) попадания с.в. X(т.е. наблюдения) в интервал 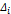 , используя формулу
, используя формулу 

 ), то проверяемую гипотезу
), то проверяемую гипотезу