
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
IV. Порядок выполнения работы
Исходные данные для задачи: Построить множество Парето для функций:
При ограничениях:
Для построения множества будем использовать следующую методику: Возьмем два строго положительных числа
Составим новый критерий
и решим следующую задачу математического программирования:
Решение этой задачи определяет такой Переберем значения
Рисунок 5 1.
Решением будет
2. 3. 4. 5. 6. Теперь, по найденным точкам построим множество Парето (рисунок 6)
Рисунок 6 – множество Парето
Практическая работа №9
Статистический анализ систем по методу группового учета аргументов.
I. Цель работы.
Цель работы заключается в изучении методов статистического анализа систем, метода группового учета аргументов для построения эффективного (оптимального) уравнения связи элементов системы.
II. Краткие сведения из теории.
Среди многочисленных методов статистического анализа (корреляционный и регрессионный, компонентный, кластерный, дисперсионный, спектральный) особое место занимает так называемый метод группового учета аргументов - МГУА. Метод позволяет исследовать системы, рассматриваемые на уровне абстракций “ черного ящика”, переводит их на более высокий уровень познания. Исходная ситуация заключается в представлении некоторого объекта совокупностью присущих ему состояний S Каждое состояние обычно характеризуется набором параметров (x S Среди рассматриваемых параметров обычно выделяются несколько наиболее значимых, которые обычно олицетворяют цель исследования. Именно такой смысл вкладывают в термин результативный признак, символизируя его иным образом, например -
Таким образом исходную для анализа информацию целесообразно представить в виде таблицы. Иногда подобные системы представляют несколько по иному, подчеркивая активную роль субъекта при исследовании. Подобная ситуация рассматривается в теории эксперимента, а схематичное изображение “черного ящика” приобретает вид согласно рисунку 1.
При этом предполагается, что механизм взаимодействия является достаточно сложным, то есть изучаемая система плохо организована. Тем не менее ставится задача по определению математической зависимости связи результативного признака Построение и анализ эффективного уравнения связи Y= Сложность порождает ряд проблем, свойственных статистическому анализу. 1. Какова структура связи исследуемых параметров? В каком формальном виде следует определять эту зависимость (линейная, полиноминальная модель более высокого порядка, экспоненциальная, показательная и т.д. )? 2. Какие состояния системы целесообразно использовать для построения модели? Как организовать эксперименты, измерения элементов системы? 3. Какие элементы системы следует включать в программу исследования? Какие из них являются наиболее значимыми в контексте рассматриваемой задачи? Как оценить риск, связанный с тем, что некоторые из них не рассматриваются? ( Обычно на первых этапах изучения сложных процессов включают все предполагаемые независимые переменные, большая часть которых в дальнейшем отсеивается планирование отсеивающих экспериментов). 4. Как обработать результаты наблюдений (измерений) для получения достоверной зависимости исследуемых величин? 5. Как поставить формальное представление системы с ее качественными характеристиками? Как интерпретировать модель на физическом уровне? 6. Как быть в тех случаях, когда не выполняются исходные предпосылки статистики основополагающие требования эффективности, состоятельности и несмещенности оценок, однородность выборочных дисперсий, нарушенные нормальности распределения и другие? Следует отметить, что указанные сложности неоднозначны при интерполяционном, экстраполяционном и аппроксимационном подходах и связаны с отсутствием четкой логической концепцией, способной служить основой для разработки стандартизованных методов анализа и редукции (свертки) статических данных, что, естественно, приводит к неоднозначности суждений в зависимости от субъективного понимания ситуации конкретным исследователем. Использование машинного эксперимента при анализе сложных ситуаций открывает возможность представление системы не одной, а несколькими моделями. Рассматривая их с различных позиций, отдавая предпочтения логике, здравому смыслу и интуиции приходим к принципиально иному подходу - инкрементальному анализу систем. Именно с таких позиций следует рассматривать метод группового учета аргументов. В его основе лежит идея построения аппроксимирующей функции
при этом Y= к - количество статических (экспериментальных ) данных.
в дальнейшем будет означать, что для каждого набора точек Предположим также, что степень полинома не превышает двух, тогда
поэтому число таких полигонов составит
Для каждой переменной
Основная суть метода группового учета аргументов заключается в том, что применяя определенную процедуру несколько раз (порождая селекции), образуют более сложные связи вплоть до включения всей совокупности элементов системы (см. рис. 2, рис.3, табл. 2). При этом степень полинома на “r” селекции равна числу 2 r. Так, например, первая селекция ( верхний индекс “1”) порождает зависимую от исходной новую статистику, формально выраженную как
где, например, равенство
Аналогичной символикой можно представить все этапы процедуры МГУА в виде рядов селекций:
либо
Примечание: индексы типа i r либо i r-1 понимать соответственно как Учитывая вложенность рассматриваемого построения, целесообразно представить результирующее взаимодействие Y как сложную функцию:
которая является результатом сложного взаимодействия и многократного отображения исходной статистики Для выражения исходной связи в аналитическом виде необходимо выполнить обратную процедуру, в результате чего может быть получена исследуемая зависимость в виде
то есть установлена связь независимых переменных и результативного признака. Это достигается последовательной подстановкой соответствующих уравнений регрессии в вышестоящие селекции по схеме
а связь между селекциями отражает система уравнений:
где
III. ЗАДАНИЕ И ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ.
1. На основании табл.1 и табл. 2 выполнить исходную статистику согласно варианту задания (номер по списку). В табл. 2 представлены все показатели исследуемого объекта - системы (машиностроительное предприятие) и три результативных признака y1, y2, y3. В табл. 1 для каждого варианта рассматривается только один результативный признак Y, а графо факторные признаки (в задаче 2) указывает на необходимость рассмотрения либо всех признаков x1, x2,..., x14, либо части, за исключением из полного множества тех, которые перечислены. В задаче 1 конкретно указано 2 либо 3 факторных признака. 2. Решить задачу 1 используя программу MGUA. Управляющие данные и исходную статистику представить согласно прилагаемой инструкции (см. пункт IV). 2.1. В результате нескольких запусков (допустим: 1) LH=3, LB=3; 2) LH=3, LB=4; 3) LH=6, LB=6) выявить «ошибочную» статистику (явно не вписывается в предполагаемую закономерность), т.е. те предприятия, значения параметров которых не соответствуют общим тенденциям. 2.2. Удалить «ошибочную» статистику и выполнить подобные расчеты с целью уже выявления оптимального уравнения связи. Для каждого ряда (селекции) есть свое лучшее уравнение, определяемое по критерию среднеквадратичного отклонения. Однако с некоторого момента (номера ряда) улучшение ситуации не происходит, математическое отображение взаимосвязи ухудшается, становится не эффективным - сложность модели возрастает, а точность снижается. 2.3. Восстановить искомую зависимость в исходных переменных 2.4. Проанализировать полученное уравнение связи, исходя из предпосылок. Сделать необходимые выводы. 3. Решить задачу 2 подобным образом, но учитывая то обстоятельство, что некоторые из многочисленных входных величин x1, x2, ..., xn реально не влияют на результативный признак. То есть необходимо выявить посредством эксперимента не влияющие факторы, исключить их из исходной статистики, а уже потом определить подходящую математическую модель системы.
Таблица 3. Варианты задач по статистическому анализу методом МГУА.
Таблица 4. Значение показателей производственно-хозяйственной деятельности Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 780; Нарушение авторского права страницы
 (1)
(1)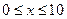 (2)
(2) и
и  , причем
, причем . (3)
. (3)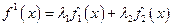 (4)
(4)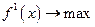 (5)
(5) , что точка
, что точка  принадлежит множеству Парето.
принадлежит множеству Парето.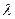 от 0 до 1 с шагом 0.1. На рисунке 5 приведены 5 кривых для различных случаев сочетаний
от 0 до 1 с шагом 0.1. На рисунке 5 приведены 5 кривых для различных случаев сочетаний  мы имеем в качестве критерия
мы имеем в качестве критерия  - параболу, ветви которой направлены вверх, а, следовательно, при ограничениях (2) максимум будет достигаться при
- параболу, ветви которой направлены вверх, а, следовательно, при ограничениях (2) максимум будет достигаться при  . Значения функций при этом будут
. Значения функций при этом будут  .
.

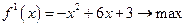 при ограничениях (2)
при ограничениях (2) . При этом получаются следующие значения функций:
. При этом получаются следующие значения функций: 






 , S
, S  ,...., S
,...., S  , по которым можно судить о его поведении внутри системы либо за ее границами (формальный математический подход приводит к известным задачам аппроксимации и экстраполяции соответственно).
, по которым можно судить о его поведении внутри системы либо за ее границами (формальный математический подход приводит к известным задачам аппроксимации и экстраполяции соответственно). , ..., x
, ..., x  , x
, x  ), номенклатура которых устанавливается на основе логики и здравого смысла (инкрементальный подход), поэтому
), номенклатура которых устанавливается на основе логики и здравого смысла (инкрементальный подход), поэтому = S
= S  . Не нарушая общности можно считать, что таким параметром является x
. Не нарушая общности можно считать, что таким параметром является x 
 .........
......... 
 1
1 


 2
2 




 ------ -------- ------------- -------- ------------
K
------ -------- ------------- -------- ------------
K 




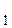 x
x 
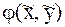
 x
x  Рис. 1. Модель “черного ящика”
Рис. 1. Модель “черного ящика”
 ( уравнение регрессии, обычно рассматривается полиноминальный тип), собственно, и является главным моментом в теории статистических методов, так как именно результативный признак используется в дальнейшем для управления объектом, выводе системы на экстремальный уровень, прогнозирования за границами системы и реализации иных приложений. С познаний системного анализа результативный признак образует основу для принятия последующего решения, которое должно учитывать все выявленные особенности задачи.
( уравнение регрессии, обычно рассматривается полиноминальный тип), собственно, и является главным моментом в теории статистических методов, так как именно результативный признак используется в дальнейшем для управления объектом, выводе системы на экстремальный уровень, прогнозирования за границами системы и реализации иных приложений. С познаний системного анализа результативный признак образует основу для принятия последующего решения, которое должно учитывать все выявленные особенности задачи. , минимизирующей сумму квадратов отклонений теоретических (Y) и экспериментальных (
, минимизирующей сумму квадратов отклонений теоретических (Y) и экспериментальных ( 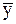 ) данных:
) данных:  (1)
(1)
 Среди различных подходов к построению теоретической модели наиболее универсальным и эффективным является подход, основанный на использовании полиномов. Существует много полиномов различной структуры, каждый из которых в равной степени претендуют на эффективное отображение исходной статистики. В частном случае можно рассматривать полиномы, объединяющие группы из двух переменных ( два элемента системы), связь которых с результативным признаком У проявляется наиболее существенно, а уже потом уточнять модель включением других элементов системы. Поэтому запись
Среди различных подходов к построению теоретической модели наиболее универсальным и эффективным является подход, основанный на использовании полиномов. Существует много полиномов различной структуры, каждый из которых в равной степени претендуют на эффективное отображение исходной статистики. В частном случае можно рассматривать полиномы, объединяющие группы из двух переменных ( два элемента системы), связь которых с результативным признаком У проявляется наиболее существенно, а уже потом уточнять модель включением других элементов системы. Поэтому запись (2)
(2) ,
, 
 существует некоторое отображение Y
существует некоторое отображение Y  в форме полинома, а единичный индекс означает, что данная процедура выполняется первых раз - первая селекция.
в форме полинома, а единичный индекс означает, что данная процедура выполняется первых раз - первая селекция. (3)
(3)
 в дальнейшем целесообразно выделить только те уравнения (3), которые соответствуют наименьшей дисперсии
в дальнейшем целесообразно выделить только те уравнения (3), которые соответствуют наименьшей дисперсии 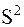 . Например, для десяти переменных (n=10) следует построить 45 моделей типа (3) и отобрать для каждой из них наиболее эффективные, то есть выделить 10-ть уравнений. В результате все элементы системы будут участвовать в ее представлении в виде парных связок (см. рис. 3). Если для некоторой переменной
. Например, для десяти переменных (n=10) следует построить 45 моделей типа (3) и отобрать для каждой из них наиболее эффективные, то есть выделить 10-ть уравнений. В результате все элементы системы будут участвовать в ее представлении в виде парных связок (см. рис. 3). Если для некоторой переменной  значение дисперсии (1) оказывается высоким, то это свидетельствует, как правило, об отсутствии рассматриваемой связи по переменной
значение дисперсии (1) оказывается высоким, то это свидетельствует, как правило, об отсутствии рассматриваемой связи по переменной 



 =
= 
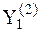 ...
... 






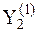 =
= 
 ...
... 
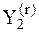







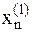
 =
= 
 ...
... 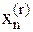




 , поэтому
, поэтому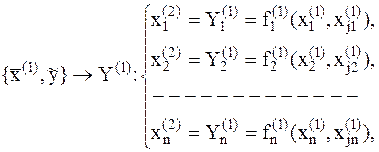 (4)
(4) означает, что выход первой селекции является входом второй селекции, а формальная запись
означает, что выход первой селекции является входом второй селекции, а формальная запись  выражает наиболее сильную связь первой переменной
выражает наиболее сильную связь первой переменной  c другой переменной
c другой переменной  , входящей в состав исходной группы.
, входящей в состав исходной группы.

 ....
....  исходная порожденная полученные уравнения
статистика статистика связи “r” селекции
Рис. 3. Последовательность обработки исходной
статистики.
исходная порожденная полученные уравнения
статистика статистика связи “r” селекции
Рис. 3. Последовательность обработки исходной
статистики.
 (5)
(5) (6)
(6) и
и 
 (7)
(7)


 (8)
(8)
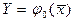 , постепенно перемещаясь с оптимального ряда на первый уровень и выполняя рассматриваемые в разделе II подстановки и преобразования.
, постепенно перемещаясь с оптимального ряда на первый уровень и выполняя рассматриваемые в разделе II подстановки и преобразования.